Embed Size (px)
Citation preview

Page 1
Option Data MiningOption_Data MiningModélisation dans Clementine
Dan Noël
1
Objectifs de la session
• Découvrir les outils de Clementine destinés à la création de modèles de Data Mining.
2

Page 2
Le nœud TYPER
• Cet élément permet d’attribuer le rôle que doit jouer chaque variable dans le processus de modélisationchaque variable dans le processus de modélisation
• IN: La variable agit comme input dans le modèle
• OUT: La variable est le résultat à prédire
Palette <OPS SUR CHAMPS>…
3
• LES DEUX: Permet que la variable soit IN et OUT à la foisUtilisé uniquement pour les associations et les séquences
• AUCUN: La variable n’est pas utilisée pour la modélisation
Paramètres du nœud TYPER
Variables de la base
4
Choix du rôle des variables

Page 3
La modélisation dans Clementine
• Tous les différents algorithmes de modélisation de Cl ti t tClementine se trouvent sous:
Palette <Modélisation>…
5
Chaque icône représente un type d’algorithmesdisponibles dans le logiciel
Prédiction et classification:Réseaux de neurones
• Dans Clementine on trouve l’algorithme de é ti d é dcréation de réseaux de neurones sous:
Palette <Modélisation>…
6
Page 4
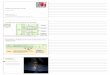
Exemple de flux réseau de neurones
7
ENTREE TRAITEMENT SORTIE
Paramètre du nœud RESEAU NEURONES
Définition du nom du modèle généré
Choix de la méthode
8
Critères de stop

Page 5
Options du nœud RESEAU NEURONES
Continuer la création d’un modèle stoppé
Meilleur traitement des variables Ensembles
Choix des ouputs detraitement et de sortie
9
Le graphique de feedback d’apprentissage
10

Page 6
Output du nœud RESEAU NEURONES (1)
Le réseau de neurones dans l’interface
11
Modèle généré par Clementine
Output du nœud RESEAU NEURONES (2)
Click droite surClick droite sur le modèle puis:
BROWSE
Description du modèle
importance variables
12
Ce modèle présente une performance (précision estimée) de 72.88%3 neurones de sorties correspondent au 3 états en matière de risque

Page 7
Comprendre le réseau de neurones…
Par la création dune table de sortie des résultats
13Ajouté au flux à partir de la modélisation
Table de sortie du réseau de neurones2 nouvelles variables…
Prédiction
14Confiance prédiction0 aucune … 1 parfaite

Page 8
Comparer prédiction avec la réalité
Ajouter une matrice pour effectuer la comparaison!!!
15
Résultat de la matrice de comparaison
Prédiction
Réalité
16
Comparaison
On se rend compte que ce modèle est meilleur « prédicteur » danscertains cas. Il est correct à 89% pour les « bad profit » mais ne réalise
une performance que de 32% environ pour les « bad loss ».

Page 9
Prédiction et classification:Les arbres de décision
• Les arbres de décision sont capables de détecter d è l à ti d j d d é t d’ét blides règles à partir de jeux de données et d’établir une relation entre celles-ci et une variable output
• Dans Clementine:–C 5.0
–C & TR
17
C & TR
–+ CHAID & QUEST (pas abordés dans ce cours)
Principales différences entre C5.0 et C & RT
• C5.0 ne supportent que les output de type b lisymbolique
• C5.0 donne un arbre et ensemble de règles comme sortie alors que C &RT rend uniquement un arbre de décision
• C5.0 fonctionne sur le principe des gains alors que C &RT sur la dispersion (GINI)
18
que C &RT sur la dispersion (GINI)
• Fonctionnement pas identique pour le traitement des missing values sur la variable output
• …

Page 10
Les arbres dans Clementine
• Dans Clementine on trouve les algorithmes d’ b d dé i i dd’arbres de décision dans:
Palette <Modélisation>…
19
Exemple de flux ARBRE C5.0
20
ENTREE TRAITEMENT SORTIE

Page 11
Paramètre du nœud C5.0
N d dèl é é éNom du modèle généré
Choix de l’output
Options modélisation
21
Output du nœud C5.0 (1)
L’arbre dans l’interface
22
Modèle généré par Clementine
Page 12
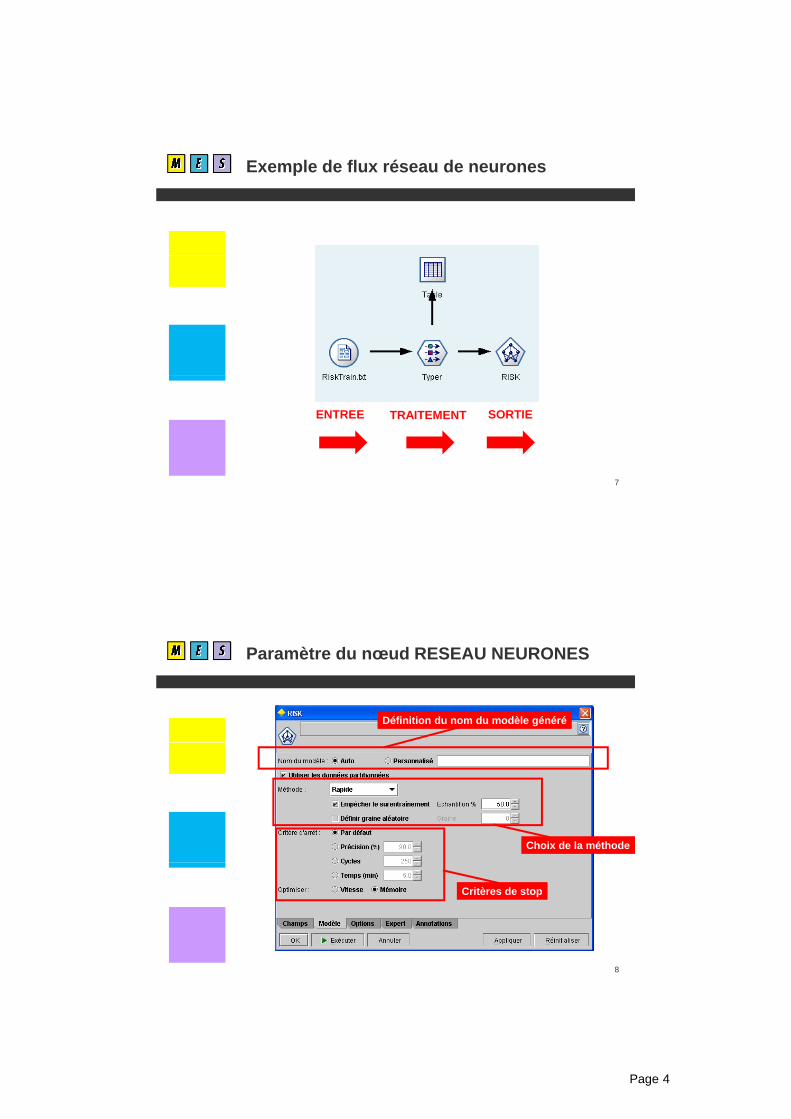
Output du nœud C5.0 (2)
Click droite surClick droite sur le modèle puis:
BROWSE
23
Autres display des règles…
24

Page 13
Visualiser les règles d’un modèle C5.0
• Autre output possible pour les arbres de type C5.0
• Sous la forme if… then… else…
25
Exemple d’output RULES SET
Click droite surClick droite sur le Rule set puis:
BROWSE
26

Page 14
Comprendre le modèle C5.0 généré…
Par la création dune table de sortie des résultats
27
Ajouté au flux à partir de la modélisation
Table de sortie de l’arbre C5.0 2 nouvelles variables…
Prédiction
28Confiance prédiction0 aucune … 1 parfaite

Page 15
Comprendre l’arbre C5.0…
Ajouter une matrice pour effectuer la comparaison!!!
29
Résultat de la matrice de comparaison
Comparaison prédiction vs réalité
30
On se rend compte que ce modèle prédit correctement 67% des« good risk », environ 89% des « bad profit » et 41% des « bad loss ».
En comparaison avec le réseau de neurones, ce modèle parait donc légèrement supérieur

Page 16
Evaluer la performance des modèles et effectuer des comparaisons
• Il existe un outil très puissant dans la palette de Cl ti tt t d j d l fClementine permettant de juger de la performance d’un modèle
• Cet outil peut également être utilisé pour effectuer des comparaisons entre les modèles générés
31
Palette <Graphiques>…
Le flux pour effectuer la mesure
Ajout au flux
32

Page 17
Paramètres du nœud EVALUATION
Type de comparaison
Ligne du hasard Ligne modèle théorique parfait
33
Les options du nœud EVALUATION
Défi i t t é ifi ( l l d i kDéfinir groupe target spécifique (exemple: que les « good risk »
34

Page 18
Output du Nœud EVALUATION (Gain Chart)
Modèle parfait
35
Ligne du hasard
Output du Nœud EVALUATION (Lift Chart)
Modèle parfait
36
Ligne du hasard

Page 19
Comparer deux modèle avec le nœud EVALUATION… le flux
37
Créer une « chaine » d’évaluation
Comparaison entre C5.0 et Réseau neuronesGain Chart
Modèle parfait
38
Ligne du hasard

Page 20
Comparaison entre C5.0 et Réseau neuronesLift Chart
Modèle parfait
39
Ligne du hasard
Exercice:Application Marketing des Lift Charts
• On imagine une entreprise avec une base de li t d 200’000 li t t ti lclients de 200’000 clients potentiels
• On a effectué un envoi test de mailing pour proposer un nouveau produit
• Mailing: 2’000 clients tirés au hasard on reçu le courrier et 100 personnes ont donné un réponse positive (soit 5% de taux +)
40
positive (soit 5% de taux )
• On estime donc le marché potentiel à:
200’000 x 5% = 10’000 clients• A partir de ces données on a généré un modèle

Page 21
Exercice: Lift Charts et Marketing
Lift chart exercice Marketing
100
30
40
50
60
70
80
90
100Po
urce
ntag
e de
s ca
s +
HasardModèle
41
0
10
20
0 10 20 30 40 50 60 70 80 90 100Pourcentage de la base
Exercice Lift Charts suite
• Cas No 1:O di d’ b d t k ti l’ i dOn dispose d’un budget marketing pour l’envoi de 40’000 mailings. Quel serait le gain potentiel de l’utilisation du modèle pour le ciblage (calculer le gain en taux de réponse et la part du marché potentiel couverte)?
• Cas No 2:
42
L’objectif de la campagne est de gagner 5’000 nouveaux clients. Compte tenu du prix d’une lettre de CHF 3.40 quel serait le gain du modèle de Data Mining pour cette action?

Page 22
Performance d’un modèle avec le nœudANALYSE
• L’outil ANALYSE de Clementine peut être é l t ili é j d l ti d’également urilisé pour juger de la pertinence d’un modèle généré par le logiciel
• Fonctionne sur la base de la comparaison automatique des valeurs prédites et la réalité du jeu de données
43
Palette <Sortie>…
Paramètres du nœud ANALYSE
ARBRE C5.0
NEURONES
Sur ce jeu de données, le
C5.0 semble légèrement plus performant que le réseau de neurones.
44
Les 2 modèles

Page 23
Exercice de modélisation
• Reprendre le flux du cours précédent pour obtenir fi hi S i t t tt éun fichier «Score_risque» correctement nettoyé
• Créer un modèle réseau de neurones et un modèle C5.0 avec pour cible la classe de risque
• Evaluer les performances des deux modèles générés
45
Prédiction: La régression linéaire
• La régression linéaire étant une technique plus h bit ll d i d t àhabituelle, nous passerons donc moins de temps à l’étudier
• Dans Clementine, on trouve l’algorithme de régression linéaire sous:
46
Palette <Modélisation>…

Page 24
Paramètres du nœud REGRESSION
Choix de la méthode de régression
47
Output du nœud REGRESSION
Détail de l’équation de régression
48

Page 25
Table de sortie de la régression1 nouvelle variable…
Valeur du revenu préditepar le modèle de régression
49
La segmentation:Réseau de Kohonen
• Pratique l’apprentissage non-supervisé
• Cherche des relations dans la structure des données de base
• L’output est un système de coordonnées (x, y) qui peuvent être utilisées pour visualiser les groupes (clusters ) résultats
B t Cl t diffé t t t h è à
50
• But: Clusters différents entre eux et homogène à l’intérieur des groupes

Page 26
Kohonen dans Clementine
• On trouve l’algorithme de réseau de Kohonen sous:
Palette <Modélisation>…
51
Exemple de flux de KOHONEN
52
ENTREE TRAITEMENT SORTIE

Page 27
Paramètres du nœud KOHONEN
Choix des variables à analyseren sortie de modèle
53
Options du nœud KOHONEN
Choix du nom du modèle
Continuer apprentissage précédent
Critères de stop
54
Page 28
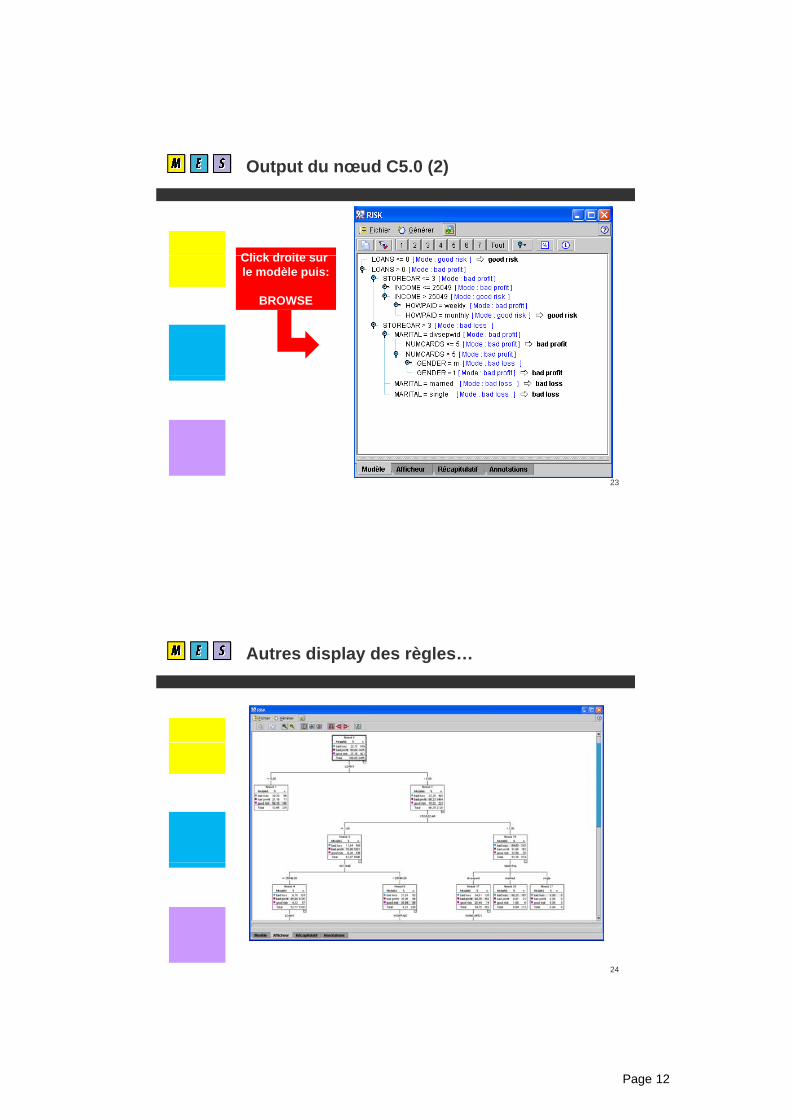
Le mode expert du nœud KOHONEN
Dimension de la carte de sortie
55
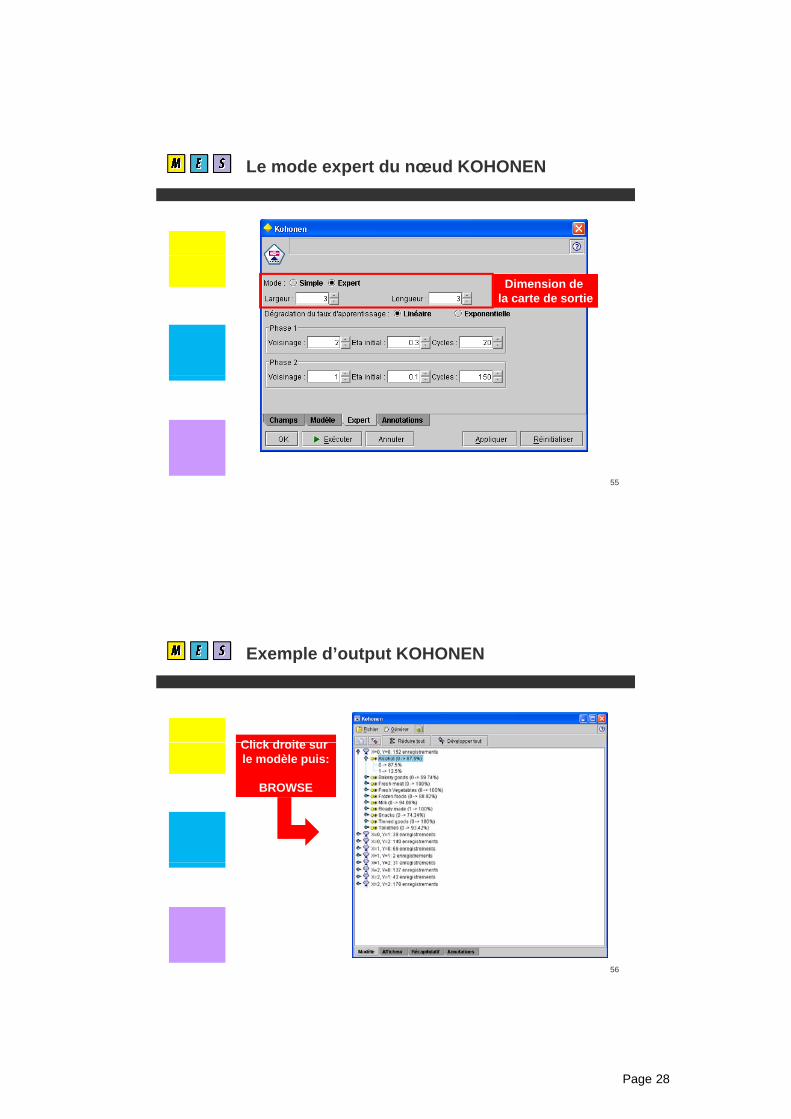
Exemple d’output KOHONEN
Click droite surClick droite sur le modèle puis:
BROWSE
56
Page 29
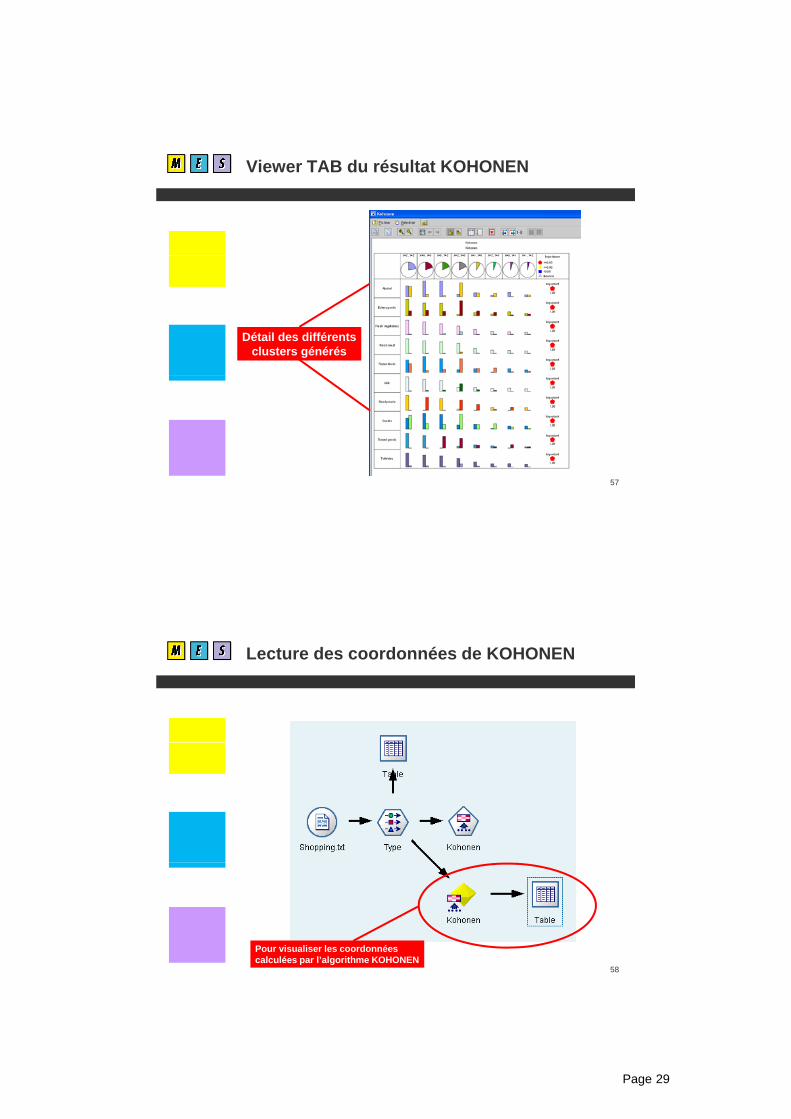
Viewer TAB du résultat KOHONEN
Détail des différentsclusters générés
57
Lecture des coordonnées de KOHONEN
58
Pour visualiser les coordonnéescalculées par l’algorithme KOHONEN

Page 30
Exercice Réseau de KOHONEN
• Recréer le flux à partir de: shopping.txt
• Utiliser le nœud CALCULER pour créer une nouvelle variable pour « rattacher » chaque enregistrement à son cluster correspondant(Passer de x,y à une variable d’ensemble)
• Utiliser cette nouvelle variable pour analyser plus finement les clusters (socio-demo,…)
59
finement les clusters (socio demo,…)
• Préparer une description sommaire de chaque cluster à partir de ces résultats
Visualiser les clusters de KOHONEN
• Pour visualiser les clusters il suffit de créer un graphique NUAGE DE POINTS à partir desgraphique NUAGE DE POINTS à partir des coordonnées X, Y de sortie du modèle KOHONEN
Choix des variablesde KOHONEN
60

Page 31
Visualisation des clusters KOHONEN
61
La segmentation:K-Means
• Principale différence avec Kohonen est que dans l éth d d K M l’ tili t dét i àla méthode de K-Means, l’utilisateurs détermine à l’avance le nombre de clusters qu’il veut générer avec le modèle
• Indicateur de dispersion intra et extra clusters
62

Page 32
Les K-Means dans Clementine
• On trouve l’algorithme de réseau de Kohonen sous:
Palette <Modélisation>…
63
Exemple de flux K-MEANS
64
ENTREE TRAITEMENT SORTIE

Page 33
Paramètres du nœud K-MEANS
Choix des variables à analyser
65
Options du nœud K-MEANS
Choix du nombrede classes
Indicateurs en sortie
66

Page 34
Exemple d’output du nœud K-MEANS
Click droite surClick droite sur le modèle puis:
BROWSE
67
Viewer TAB du résultat K-MEANS
Détail des différentsclusters générés
68

Page 35
Lecture du résulat de K-MEANS
69
Pour visualiser les coordonnéescalculées par l’algorithme K-MEANS
Table d’output de K-MEANS
Dispersion intra-classe
Classe attribuée
70

Page 36
Exercice Réseau de K-MEANS
• Recréer le flux à partir de: shopping.txt
• Lancer la création de 3 classes avec l’outil K-MEANS de Clementine
• Préparer une description sommaire de chaque cluster à partir de classes attribués par K-MEANS
71