Embed Size (px)
Citation preview
Computazione per l’interazione naturale: fondamenti probabilistici
Corso di Interazione Naturale
Prof. Giuseppe Boccignone
Dipartimento di InformaticaUniversità di Milano
[email protected]/IN_2017.html
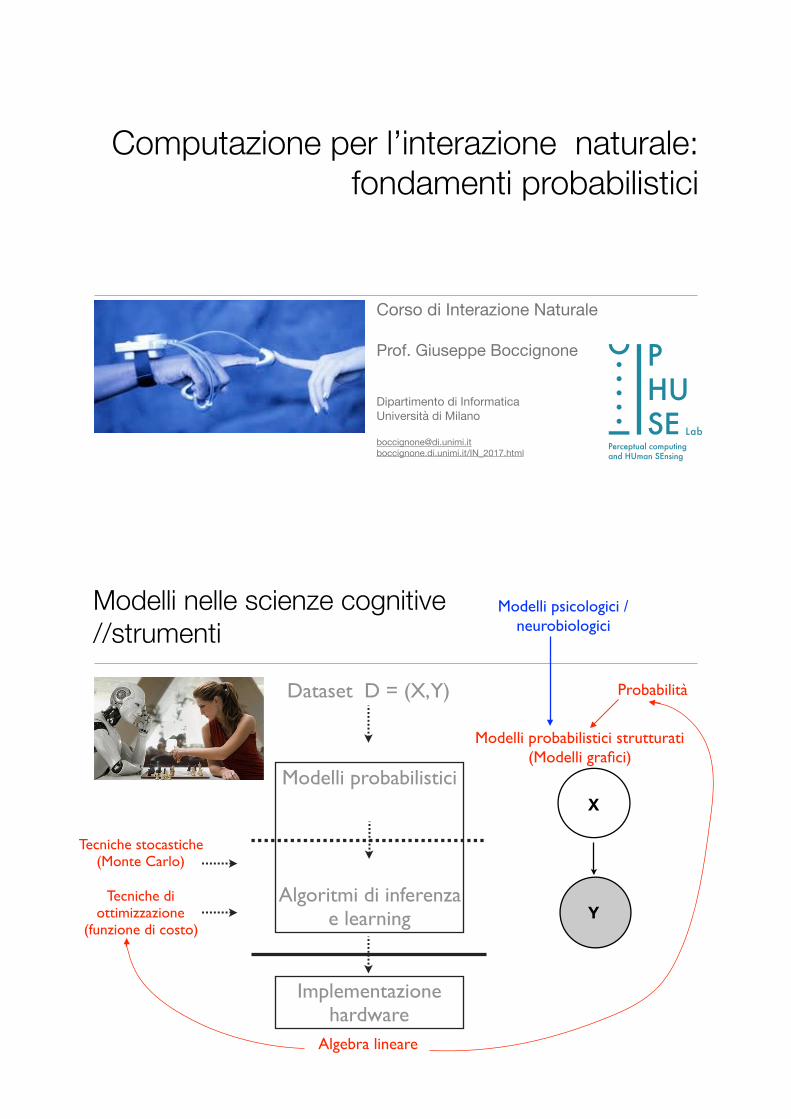
Modelli probabilistici
Algoritmi di inferenza e learning
Implementazione hardware
Modelli nelle scienze cognitive //strumenti
X
Y
Dataset D = (X, Y)
Tecniche stocastiche(Monte Carlo)
Tecniche di ottimizzazione
(funzione di costo)
Algebra lineare
Probabilità
Modelli probabilistici strutturati(Modelli grafici)
Modelli psicologici / neurobiologici
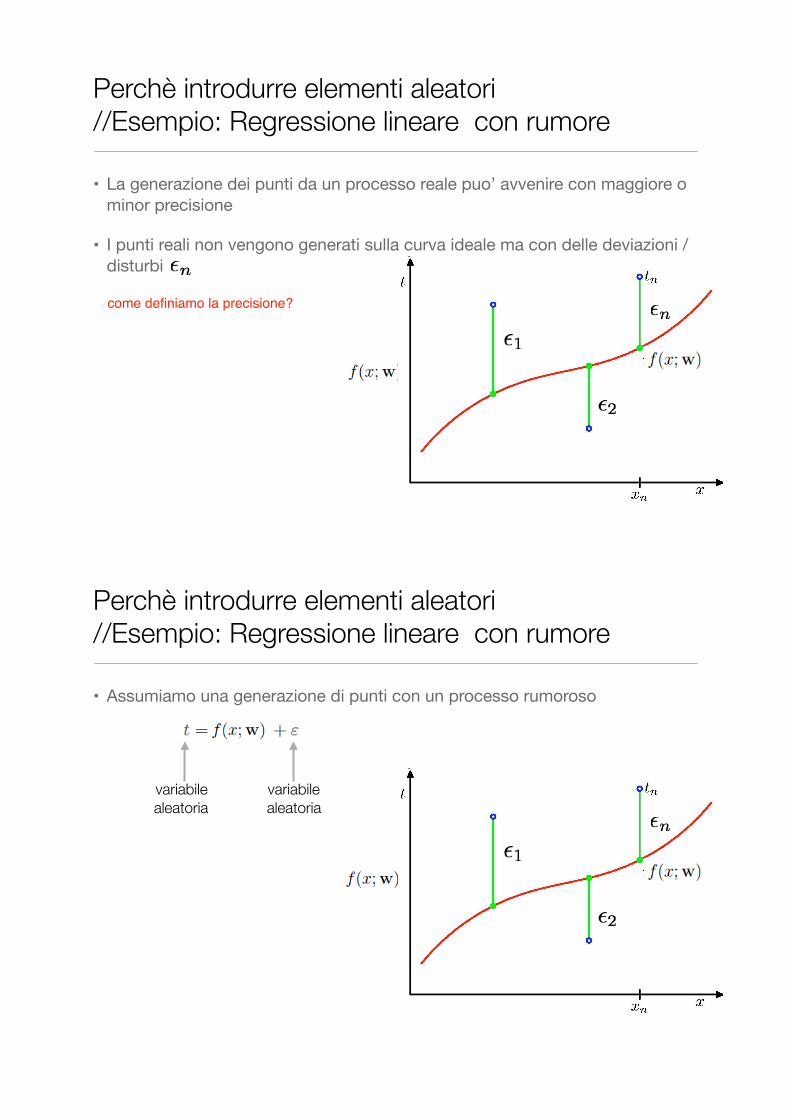
Perchè introdurre elementi aleatori //Esempio: Regressione lineare con rumore
• La generazione dei punti da un processo reale puo’ avvenire con maggiore o minor precisione
• I punti reali non vengono generati sulla curva ideale ma con delle deviazioni / disturbi
come definiamo la precisione?
• Assumiamo una generazione di punti con un processo rumoroso
Perchè introdurre elementi aleatori //Esempio: Regressione lineare con rumore
variabile aleatoria
variabile aleatoria
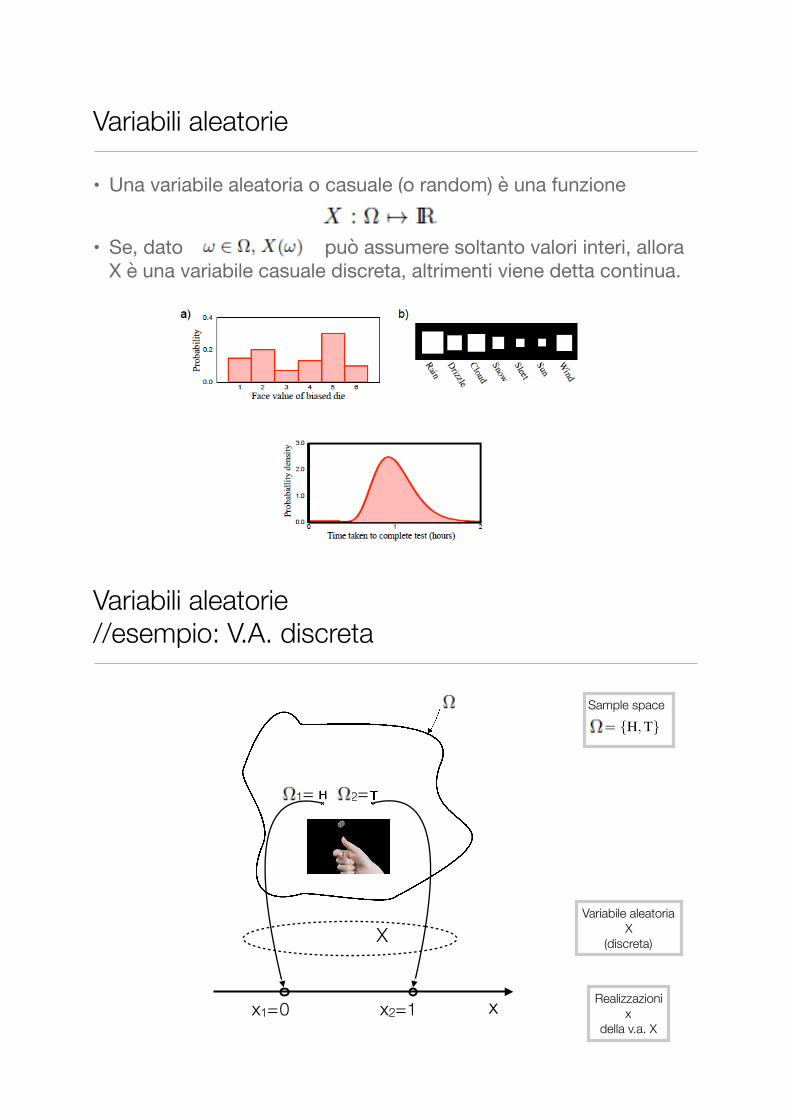
Variabili aleatorie
• Una variabile aleatoria o casuale (o random) è una funzione
• Se, dato può assumere soltanto valori interi, allora X è una variabile casuale discreta, altrimenti viene detta continua.
Variabili aleatorie //esempio: V.A. discreta
We assume here that coins and dice are fair and have no memory, i.e., eachoutcome is equally likely on each toss, regardless of the results of previous tosses.
It is helpful to give a geometric representation of events using a Venn diagram.This is a diagram in which sample space is presented using a closed-plane figureand sample points using the corresponding dots. The sample spaces (1.1) and (1.3)are shown in Fig. 1.1a, b, respectively.
The sample sets (1.1) and (1.3) are discrete and finite. The sample set can also bediscrete and infinite. If the elements of the sample set are continuous (i.e., notcountable) thus the sample set S is continuous. For example, in an experimentwhich measures voltage over time T, the sample set (Fig. 1.2) is:
S ¼ fsjV1 < s < V2g: (1.4)
In most situations, we are not interested in the occurrence of specific outcomes,but rather in certain characteristics of the outcomes. For example, in the voltagemeasurement experiment we might be interested if the voltage is positive or lessthan some desired value V. To handle such situations it is useful to introduce theconcept of an event.
Fig. 1.1 Sample spaces for coin tossing and die rolling. (a) Coin tossing. (b) Die rolling
V1 V2
S
Fig. 1.2 Example of continuous space
2 1 Introduction to Sample Space and Probability
Sample space
Chapter 1Introduction to Sample Space and Probability
1.1 Sample Space and Events
Probability theory is the mathematical analysis of random experiments [KLI86,p. 11]. An experiment is a procedure we perform that produces some result oroutcome [MIL04, p. 8].
An experiment is considered random if the result of the experiment cannot bedetermined exactly. Although the particular outcome of the experiment is notknown in advance, let us suppose that all possible outcomes are known.
The mathematical description of the random experiment is given in terms of:
• Sample space• Events• Probability
The set of all possible outcomes is called sample space and it is given the symbolS. For example, in the experiment of a coin-tossing we cannot predict exactly if“head,” or “tail” will appear; but we know that all possible outcomes are the“heads,” or “tails,” shortly abbreviated as H and T, respectively. Thus, the samplespace for this random experiment is:
S ¼ fH;Tg: (1.1)
Each element in S is called a sample point, si. Each outcome is represented by acorresponding sample point. For example, the sample points in (1.1) are:
s1 ¼ H; s2 ¼ T: (1.2)
When rolling a die, the outcomes correspond to the numbers of dots (1–6).Consequently, the sample set in this experiment is:
S ¼ f1; 2; 3; 4; 5; 6g: (1.3)
G.J. Dolecek, Random Signals and Processes Primer with MATLAB,DOI 10.1007/978-1-4614-2386-7_1, # Springer Science+Business Media New York 2013
1
s1= s2=
0 1
XVariabile aleatoria
X (discreta)
xRealizzazioni
x della v.a. X
x1= x2=
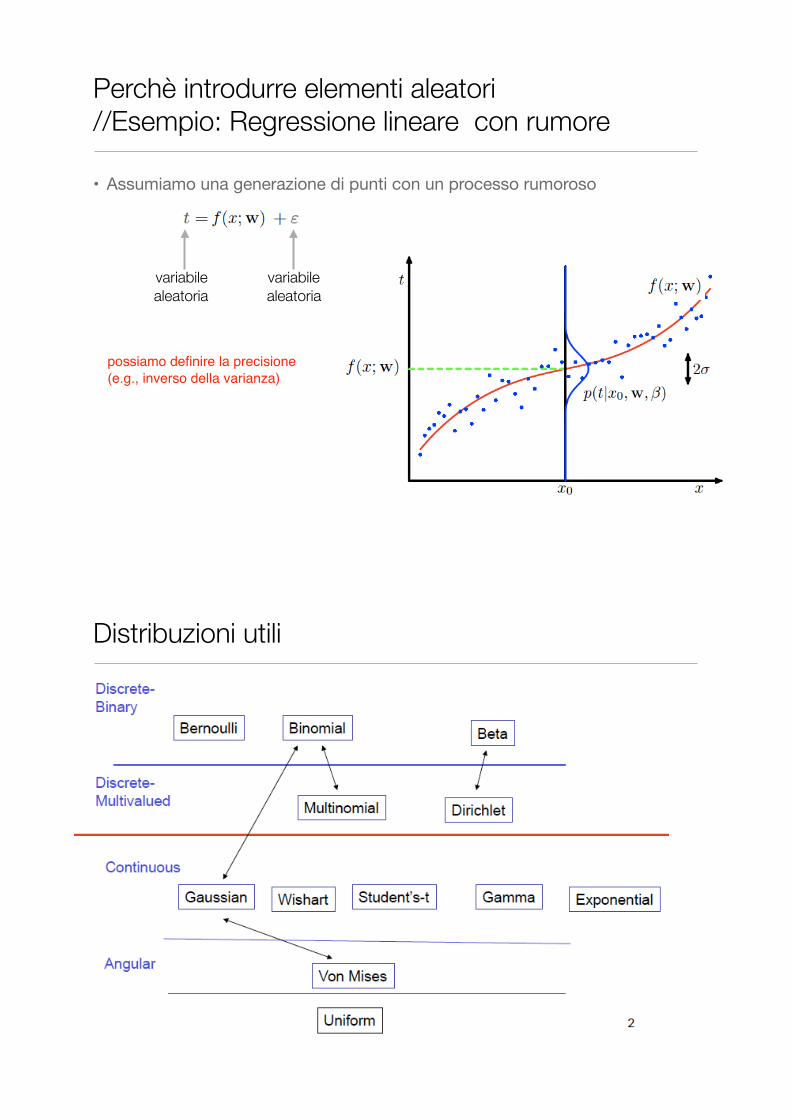
• Assumiamo una generazione di punti con un processo rumoroso
Perchè introdurre elementi aleatori //Esempio: Regressione lineare con rumore
possiamo definire la precisione (e.g., inverso della varianza)
variabile aleatoria
variabile aleatoria
Distribuzioni utili
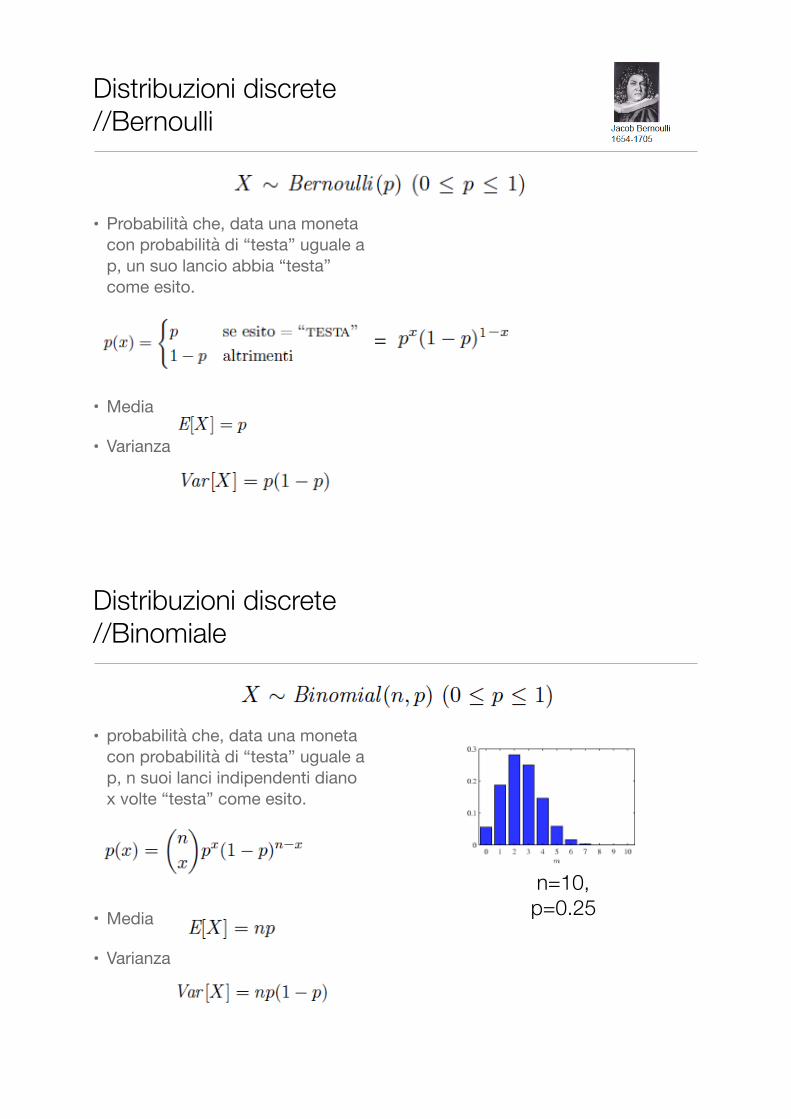
Distribuzioni discrete //Bernoulli
• Probabilità che, data una moneta con probabilità di “testa” uguale a p, un suo lancio abbia “testa” come esito.
• Media
• Varianza
=
Distribuzioni discrete //Binomiale
• probabilità che, data una moneta con probabilità di “testa” uguale a p, n suoi lanci indipendenti diano x volte “testa” come esito.
• Media
• Varianza
n=10, p=0.25
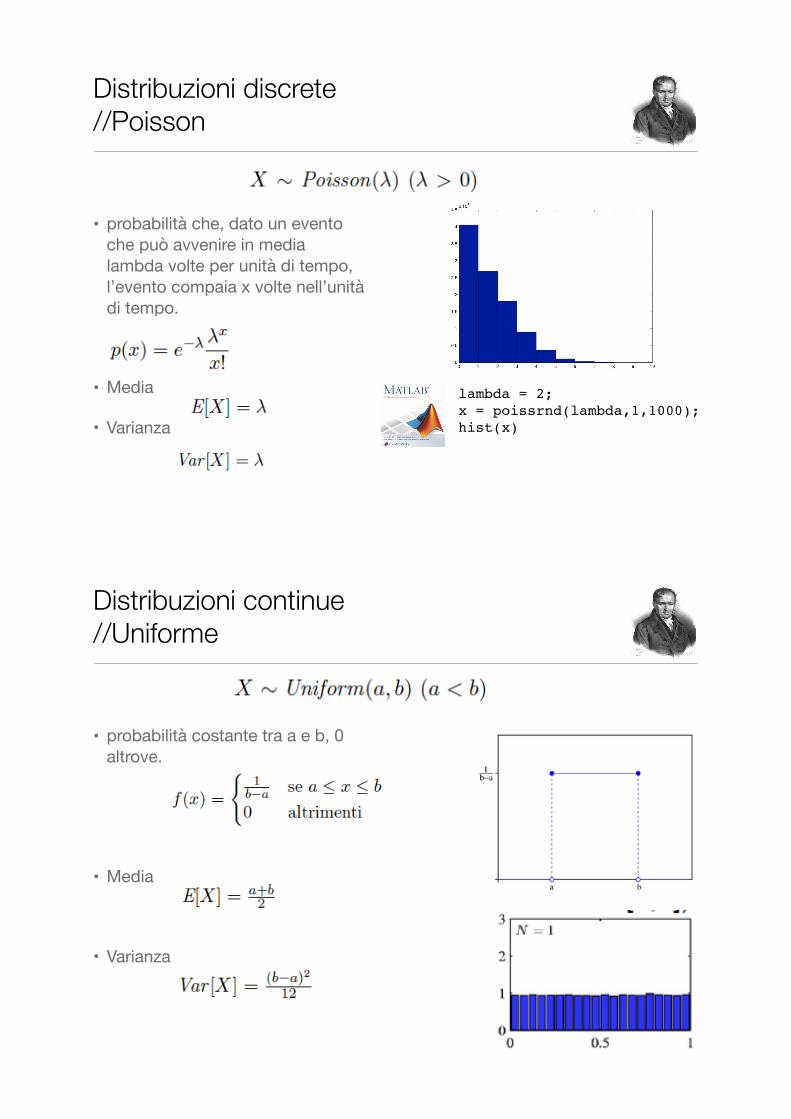
Distribuzioni discrete //Poisson
• probabilità che, dato un evento che può avvenire in media lambda volte per unità di tempo, l’evento compaia x volte nell’unità di tempo.
• Media
• Varianza
lambda = 2;x = poissrnd(lambda,1,1000);hist(x)
Distribuzioni continue //Uniforme
• probabilità costante tra a e b, 0 altrove.
• Media
• Varianza
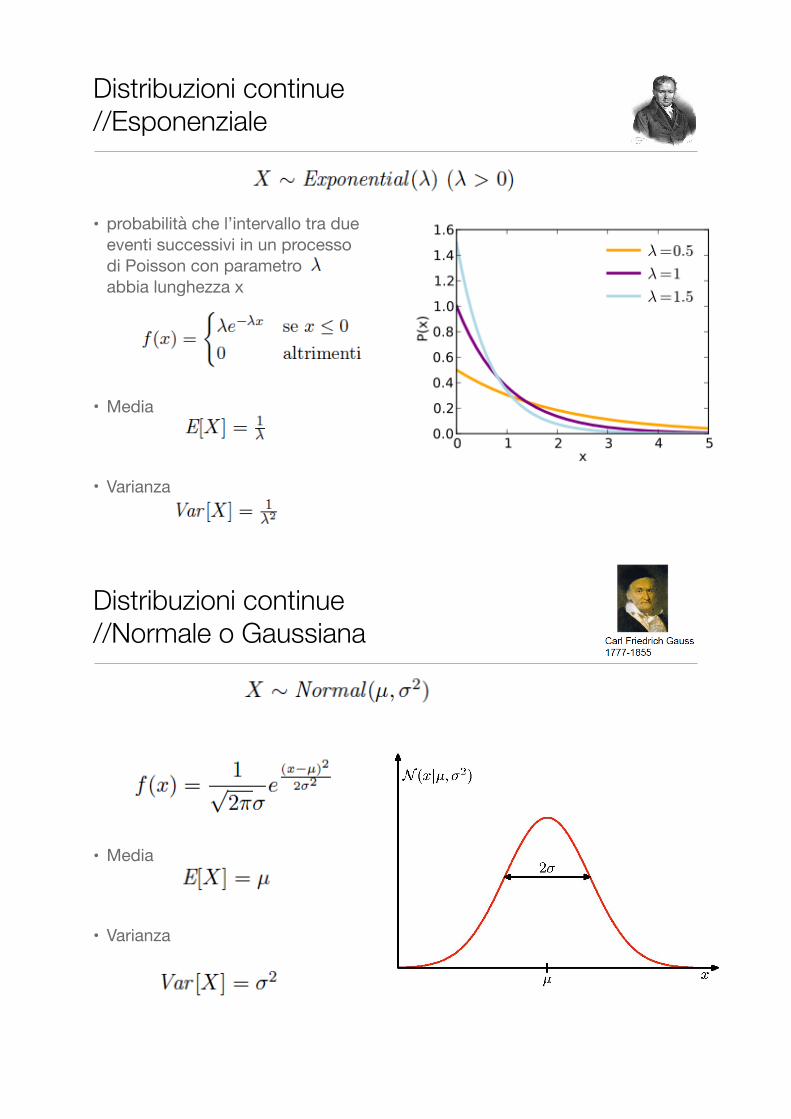
Distribuzioni continue //Esponenziale
• probabilità che l’intervallo tra due eventi successivi in un processo di Poisson con parametro abbia lunghezza x
• Media
• Varianza
Distribuzioni continue //Normale o Gaussiana
• Media
• Varianza
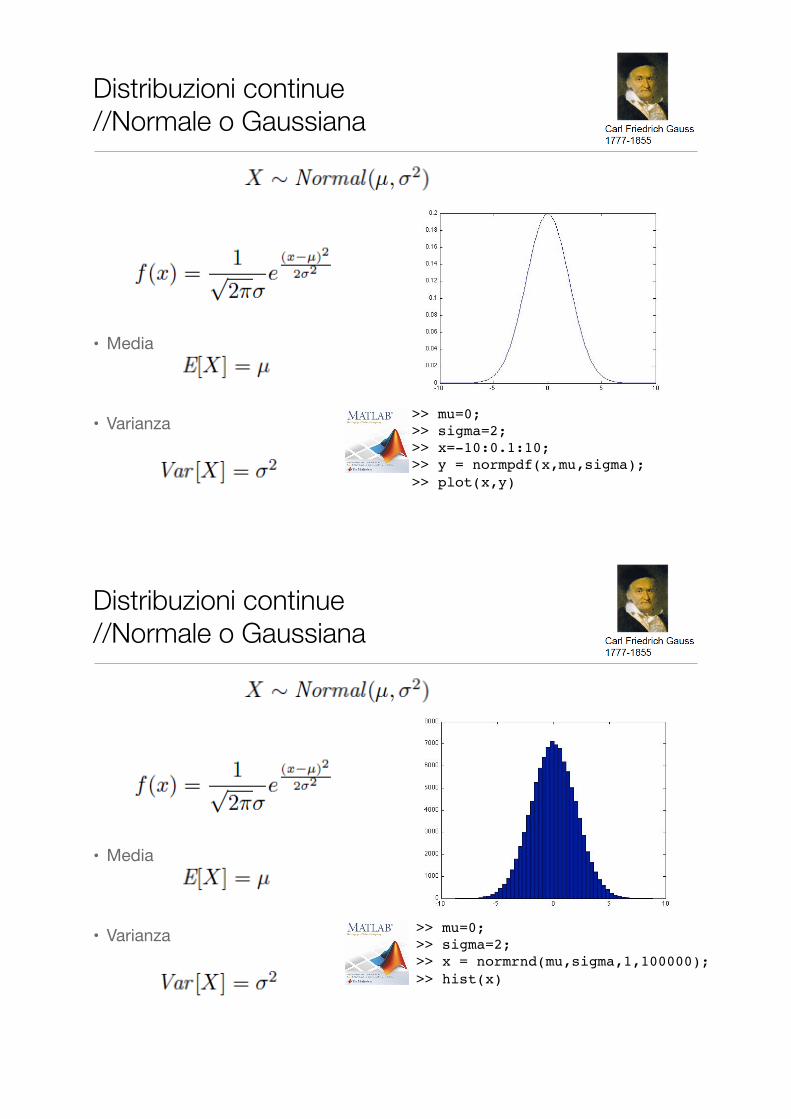
Distribuzioni continue //Normale o Gaussiana
• Media
• Varianza >> mu=0;>> sigma=2;>> x=-10:0.1:10;>> y = normpdf(x,mu,sigma);>> plot(x,y)
Distribuzioni continue //Normale o Gaussiana
• Media
• Varianza >> mu=0;>> sigma=2;>> x = normrnd(mu,sigma,1,100000);>> hist(x)
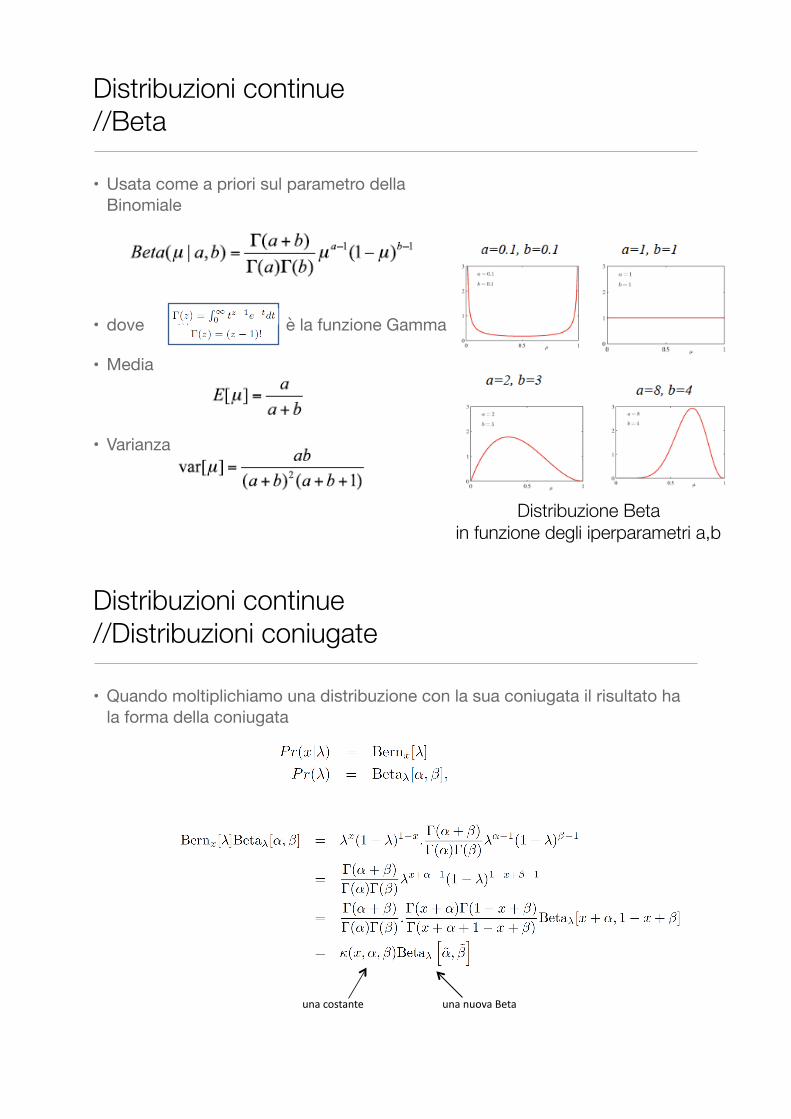
• Usata come a priori sul parametro della Binomiale
• dove è la funzione Gamma
• Media
• Varianza
Distribuzioni continue //Beta
Distribuzione Beta in funzione degli iperparametri a,b
Distribuzioni continue //Distribuzioni coniugate
• Quando moltiplichiamo una distribuzione con la sua coniugata il risultato ha la forma della coniugata
una$costante una$nuova$Beta
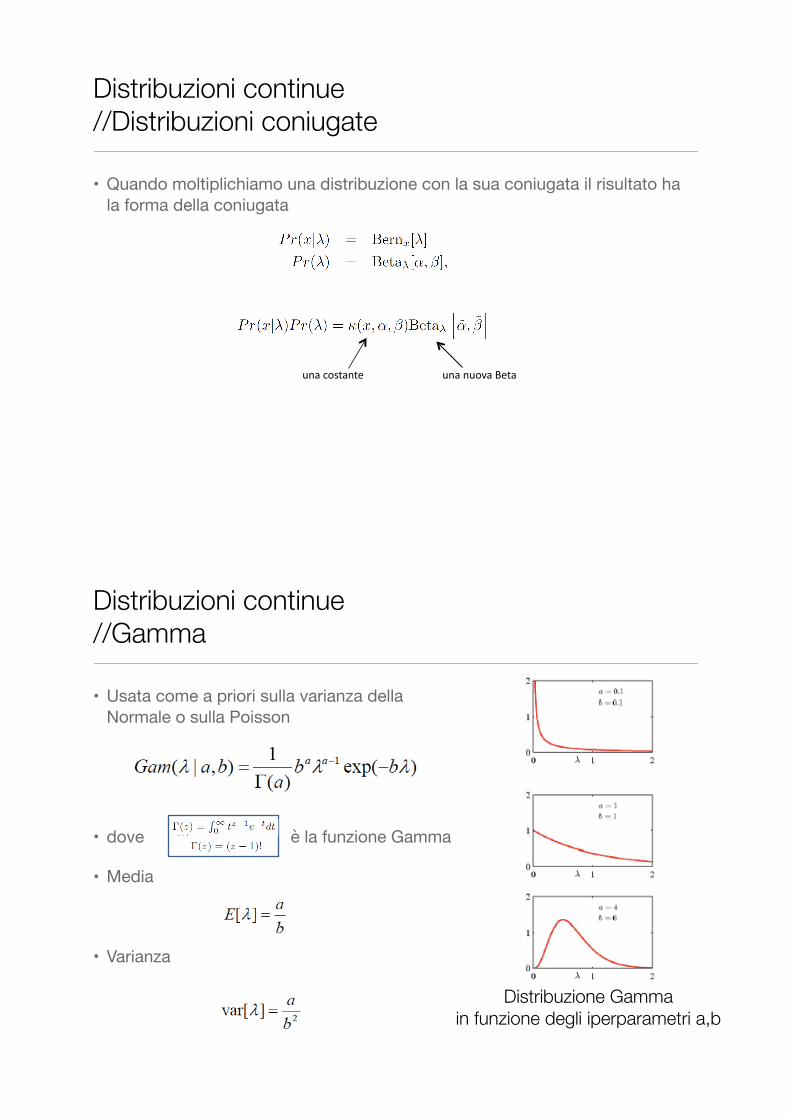
Distribuzioni continue //Distribuzioni coniugate
• Quando moltiplichiamo una distribuzione con la sua coniugata il risultato ha la forma della coniugata
una$costante una$nuova$Beta
• Usata come a priori sulla varianza della Normale o sulla Poisson
• dove è la funzione Gamma
• Media
• Varianza
Distribuzioni continue //Gamma
Distribuzione Gamma in funzione degli iperparametri a,b

Estensione a due variabili casuali //distribuzioni cumulative congiunte e marginali
• Date due variabili casuali continue X, Y , la distribuzione di probabilità cumulativa congiunta è definita come
• Valgono le seguenti
• Data la distribuzione cumulativa di probabilità congiunta FXY (x, y) le distribuzioni cumulative marginali di probabilità FX e FY sono definite come
Estensione a due variabili casuali //distribuzioni di probabilità congiunte e marginali
• Date due variabili casuali discrete X, Y
• valgono le seguenti
• Data la distribuzione di probabilità pXY (x, y) le distribuzioni marginali di probabilità pX e pY sono definite come
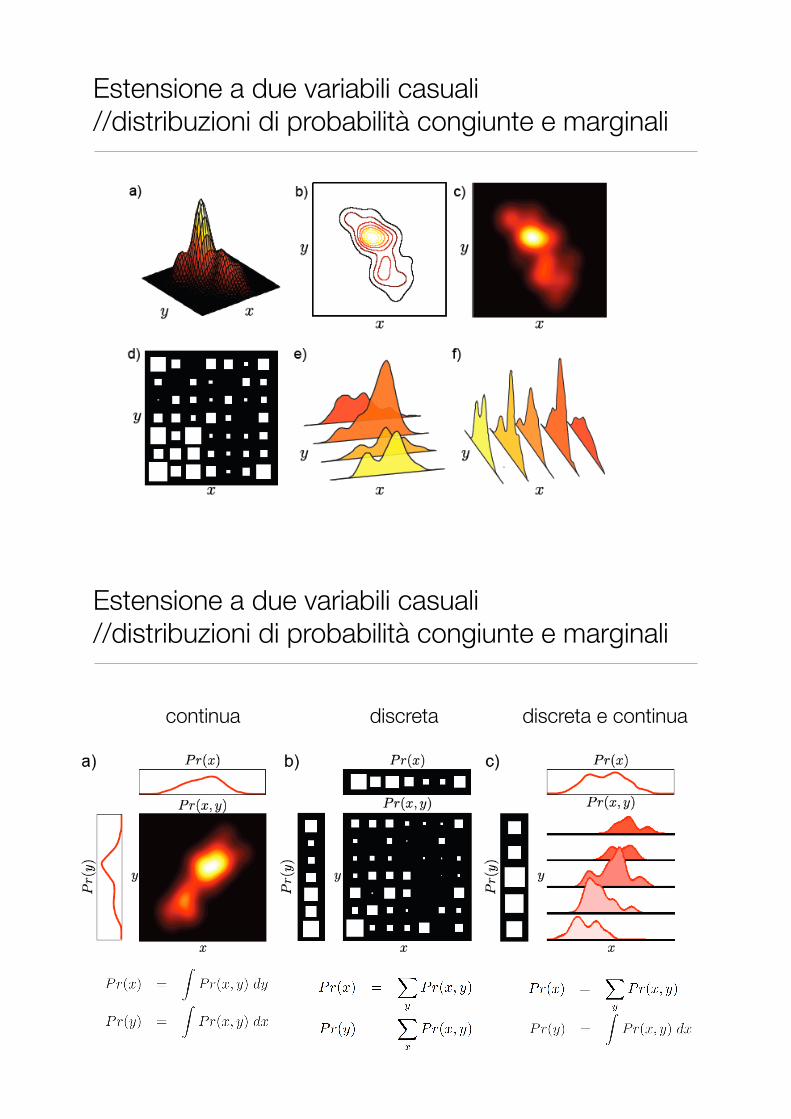
Estensione a due variabili casuali //distribuzioni di probabilità congiunte e marginali
Estensione a due variabili casuali //distribuzioni di probabilità congiunte e marginali
continua discreta discreta e continua

• Se FXY (x, y) è dovunque derivabile rispetto sia a x che a y, allora la densità di probabilità congiunta è definita come
• vale
• Data la densità di probabilità cumulativa fXY (x, y) le densità marginali di probabilità fX e fY sono definite come
Estensione a due variabili casuali //densità di probabilità congiunte e marginali
• Date due variabili casuali X, Y discrete , la probabilità condizionata di X rispetto a Y è definita come
• X, Y continue
Estensione a due variabili casuali //probabilità condizionate
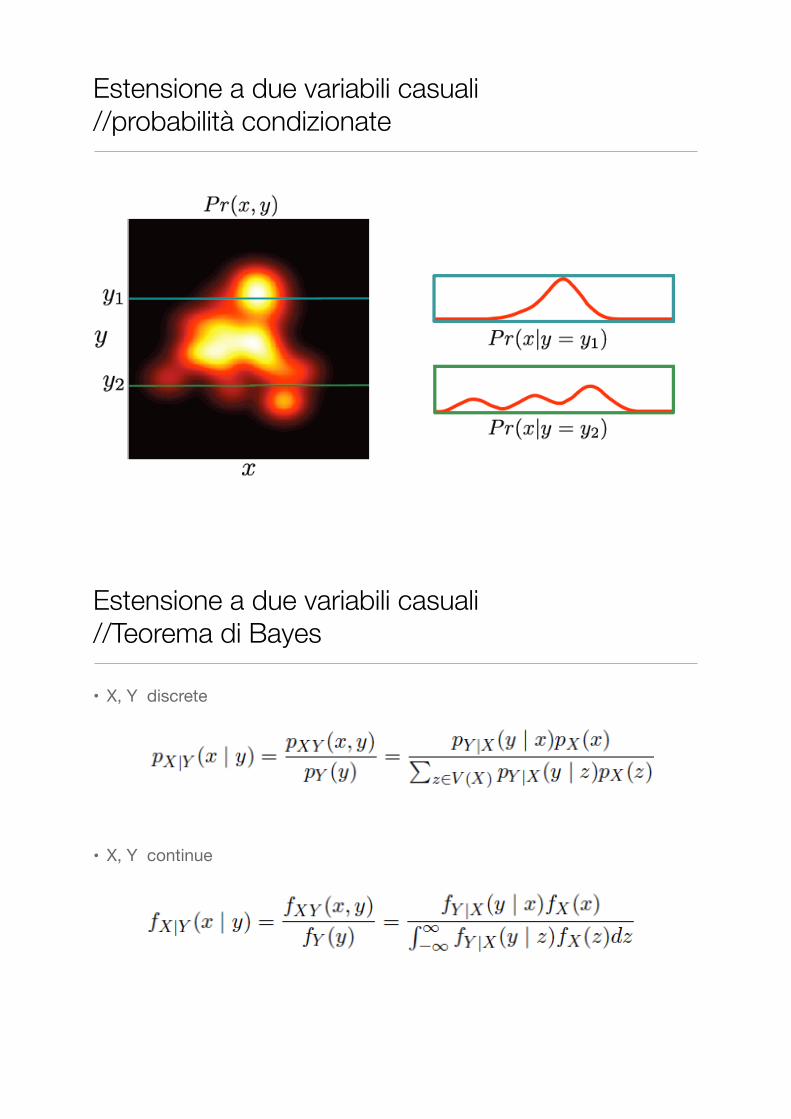
Estensione a due variabili casuali //probabilità condizionate
• X, Y discrete
• X, Y continue
Estensione a due variabili casuali //Teorema di Bayes

Estensione a due variabili casuali //Teorema di Bayes
Posterior$–$cosa$sappiamo$di$y$dopo$aver$osservato$x
Prior$–$cosa$sappiamo$di$$y$prima$di$osservare$x
Likelihood$–$propensione$ad$osservare$un$certo$valore$x$dato$un$valore$y
Evidence$–una$costante$di$normalizzazione$
• Quando moltiplichiamo una distribuzione con la sua coniugata il risultato ha la forma della coniugata
una$costante una$nuova$Beta
Estensione a due variabili casuali //Teorema di Bayes e coniugate

Posterior$–$è$una$nuova
Prior$–$uso$la$coniugataLikelihood$–$Bernoulli
Evidence$–$è$la$costante$di$normalizzazione$
• Utilizziamo le coniugate e Bayes per il learning dei parametri
Estensione a due variabili casuali //Teorema di Bayes e coniugate
• Due variabili casuali sono indipendenti se
• ovvero
Estensione a due variabili casuali //indipendenza

Estensione a due variabili casuali //indipendenza
estrae la slice e normalizza
• Date due variabili casuali X, Y discrete e una funzione il valore atteso di g è
• X, Y continue
• Valgono le seguenti
Estensione a due variabili casuali //valore atteso

• Date due variabili casuali X, Y , la loro covarianza è definita
• come nel caso della varianza:
• Valgono inoltre:
Estensione a due variabili casuali //covarianze
• Date n variabili causali X1,X2, . . . ,Xn
• valgono
• Per ogni Xi è definita la marginale
Estensione a n variabili casuali

• Date n variabili casuali discrete, la distribuzione di probabilità congiunta
• per la quale valgono:
• La distribuzione di probabilità marginale è
Estensione a n variabili casuali //caso discreto
La$v.a.$può$essere$pensata$come$un$vettore$di$indicatori$dove$solo$il$ksimo$elemento$è$diverso$da$zero,$e.g.$$e4$=$[0,0,0,1,0]
Descrive$una$situazione$dove$vi$sono$sono$K$possibili$risultati$y=1… y=k.$(e.g.,$il$lancio$di$un$dado$con$k=6)$
Prende$$K$parametri$$$$$$$$$$$$$$$$$$$$$$$$$$con$
A$volte$viene$detta$$Multinoulli,$perché$è$una$generalizzazione$della$Bernoulli
Estensione a n variabili casuali //caso discreto: la distribuzione categorica

• Se la F è derivabile, la densità di probabilità congiunta è definita
• quindi
• La densità marginale di probabilità è
Estensione a n variabili casuali //caso continuo
• Dalla definizione di probabilità condizionate:
Estensione a n variabili casuali //regola del prodotto

• Date una distribuzione f(x1, x2, . . . , xn) e una funzione
Estensione a n variabili casuali //valore atteso
• Dato un insieme X1,X2, . . . ,Xn di variabili casuali, è possibile definire il vettore aleatorio
• Anche una funzione è rappresentabile come vettore
Estensione a n variabili casuali //covarianza

• Dato il vettore la sua matrice di covarianza è la matrice n x n tale che, per ogni coppia i, j
• ovvero:
Estensione a n variabili casuali //covarianza
• è matrice simmetrica:
• per definizione di covarianza
• è semi-definita positiva:
• per qualunque vettore z:
• ma
Estensione a n variabili casuali //covarianza
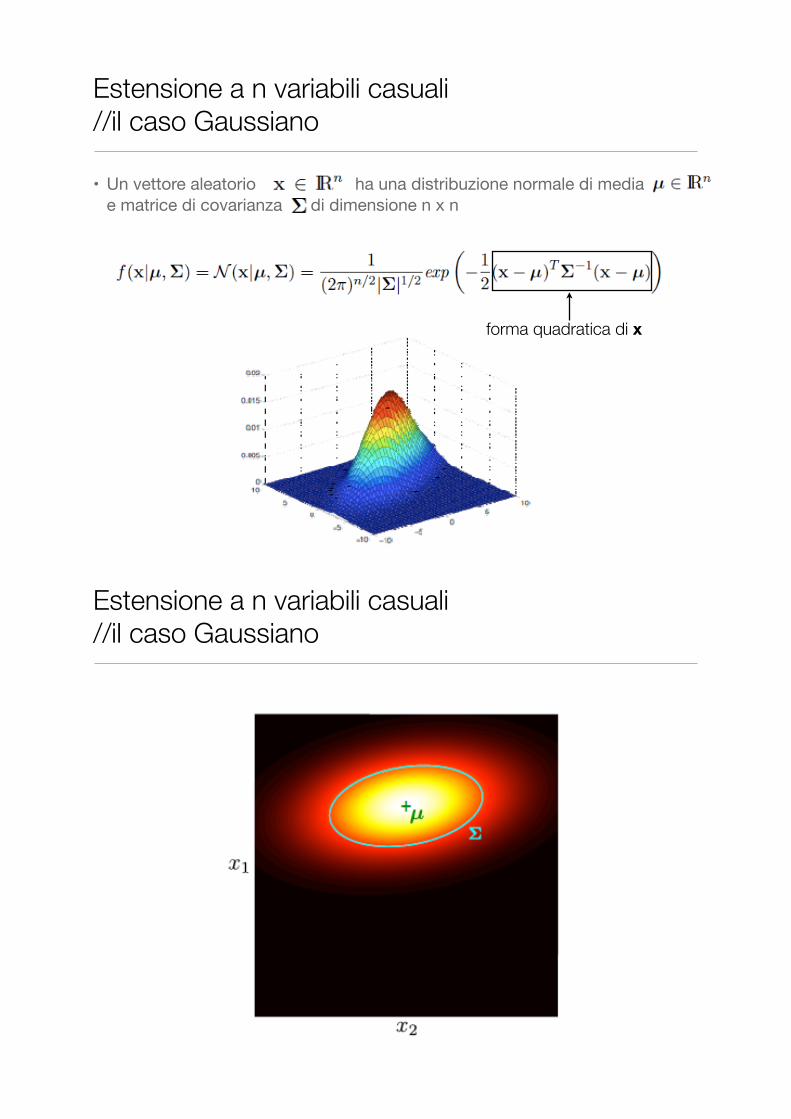
• Un vettore aleatorio ha una distribuzione normale di media e matrice di covarianza di dimensione n x n
Estensione a n variabili casuali //il caso Gaussiano
forma quadratica di x
Estensione a n variabili casuali //il caso Gaussiano
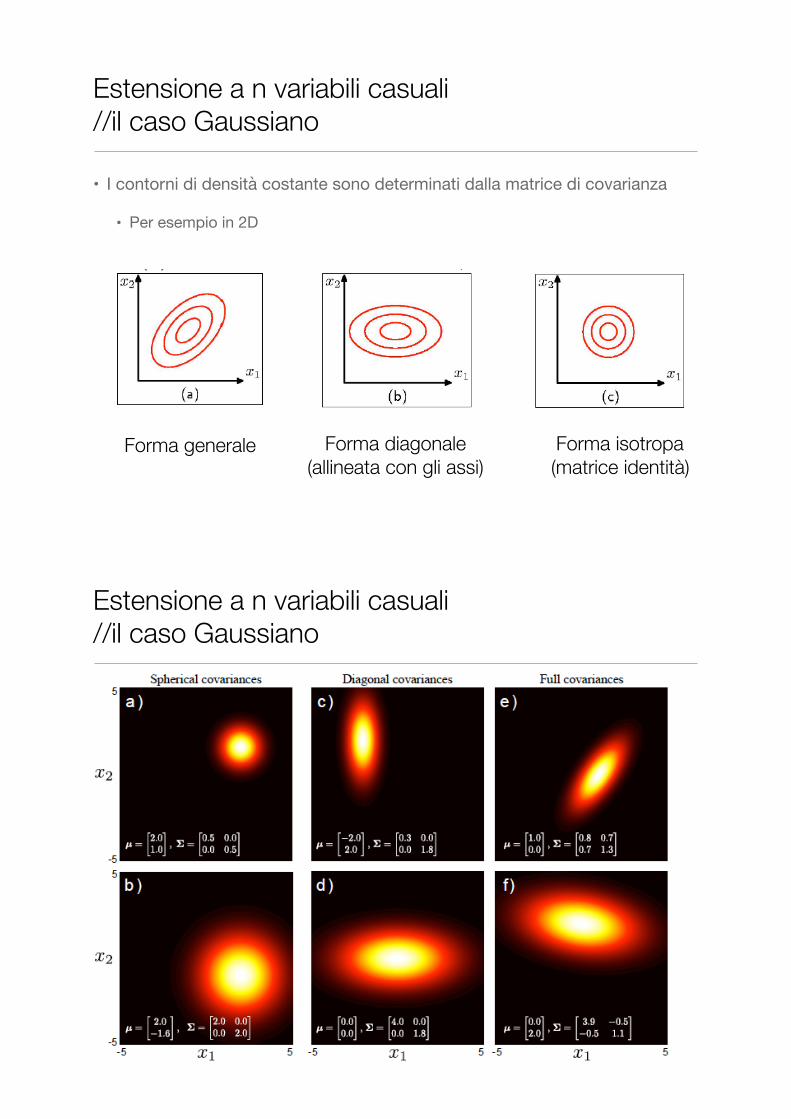
• I contorni di densità costante sono determinati dalla matrice di covarianza
• Per esempio in 2D
Estensione a n variabili casuali //il caso Gaussiano
Forma generale Forma diagonale (allineata con gli assi)
Forma isotropa (matrice identità)
Estensione a n variabili casuali //il caso Gaussiano
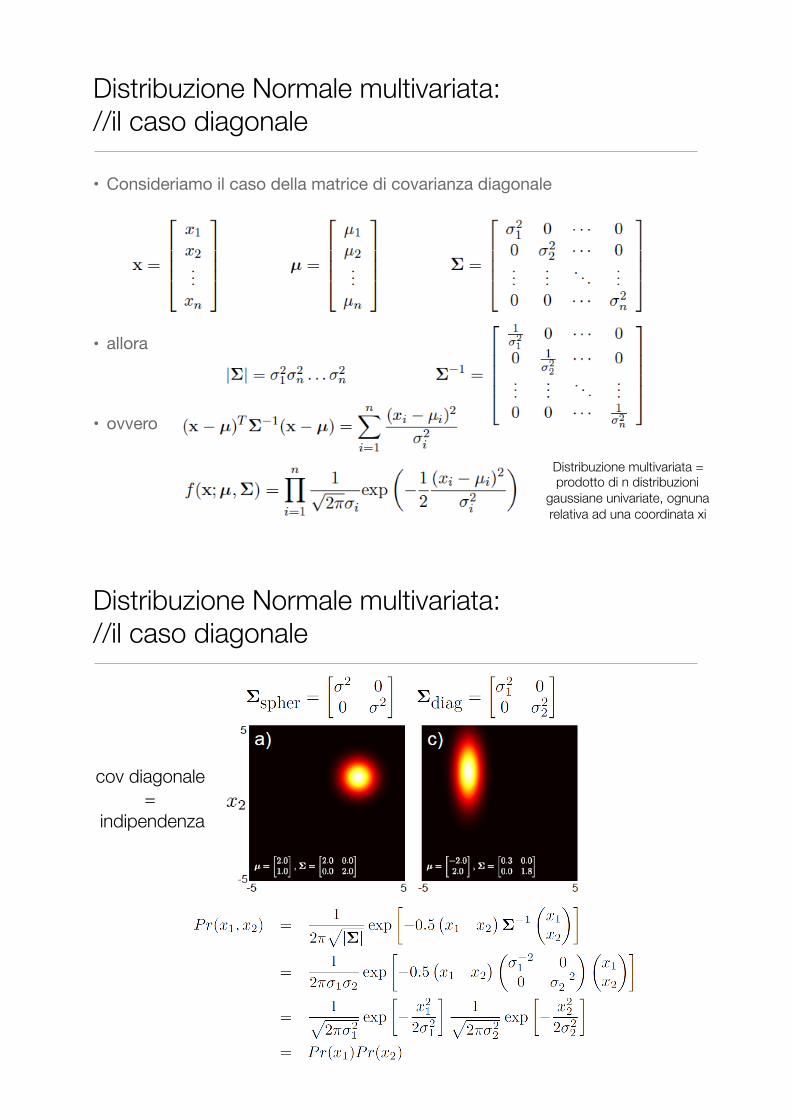
• Consideriamo il caso della matrice di covarianza diagonale
• allora
• ovvero
Distribuzione multivariata = prodotto di n distribuzioni
gaussiane univariate, ognuna relativa ad una coordinata xi
Distribuzione Normale multivariata: //il caso diagonale
Distribuzione Normale multivariata: //il caso diagonale
cov diagonale =
indipendenza

Distribuzione Normale multivariata: //decomposizione della covarianza
Nel$sistema$di$riferimento$verde:
Relazione$fra$i$due$SR:
Sostituendo:
Conclusione
Posso$decomporre$la$matrice$di$covarianza$in$una$matrice$di$rotazione$e$una$diagonale
• Valgono le seguenti come nel caso univariato
Distribuzione Normale multivariata: //medie e covarianze

• Siano
• La somma è ancora distribuita normalmente
• Si noti che la distribuzione di z = x + y è cosa diversa dalla somma delle distribuzioni di x e y (che in generale non è gaussiana).
Distribuzione Normale multivariata: //somma di variabili gaussiane indipendenti
• Sia con
• La distribuzione di x è la congiunta
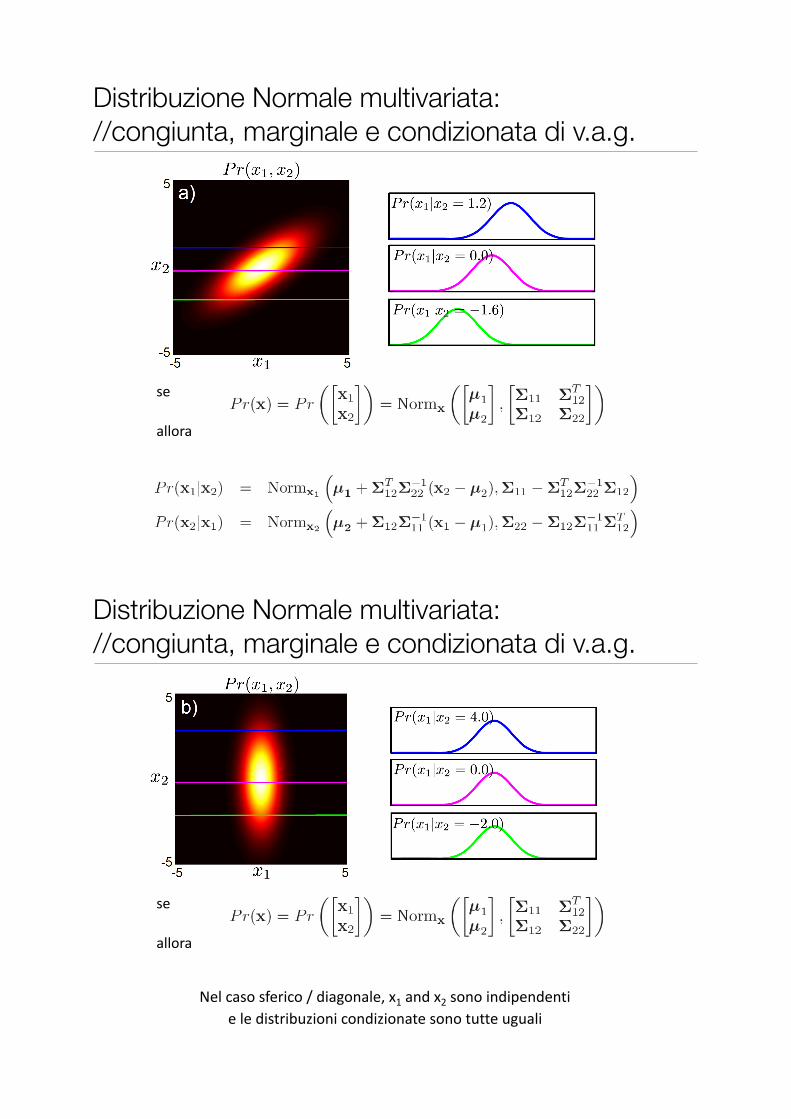
Distribuzione Normale multivariata: //congiunta, marginale e condizionata di v.a.g.

• La distribuzione di x è la congiunta Gaussiana
• Marginali Gaussiane:
• Condizionate Gaussiane:
Distribuzione Normale multivariata: //congiunta, marginale e condizionata di v.a.g.
Distribuzione Normale multivariata: //congiunta, marginale e condizionata di v.a.g.
allora
Distribuzione Normale multivariata: //congiunta, marginale e condizionata di v.a.g.
se
allora
Distribuzione Normale multivariata: //congiunta, marginale e condizionata di v.a.g.
se
allora
Nel$caso$sferico$/$diagonale,$x1$and$x2$sono$indipendenti$e$le$distribuzioni$condizionate$sono$tutte$uguali

Distribuzione Normale multivariata: //proprietà affine
Trasformazione$di$variabili:
• Siano
• La probabilità a posteriori vale:
• Inoltre:
Distribuzione Normale multivariata: //formula di Bayes
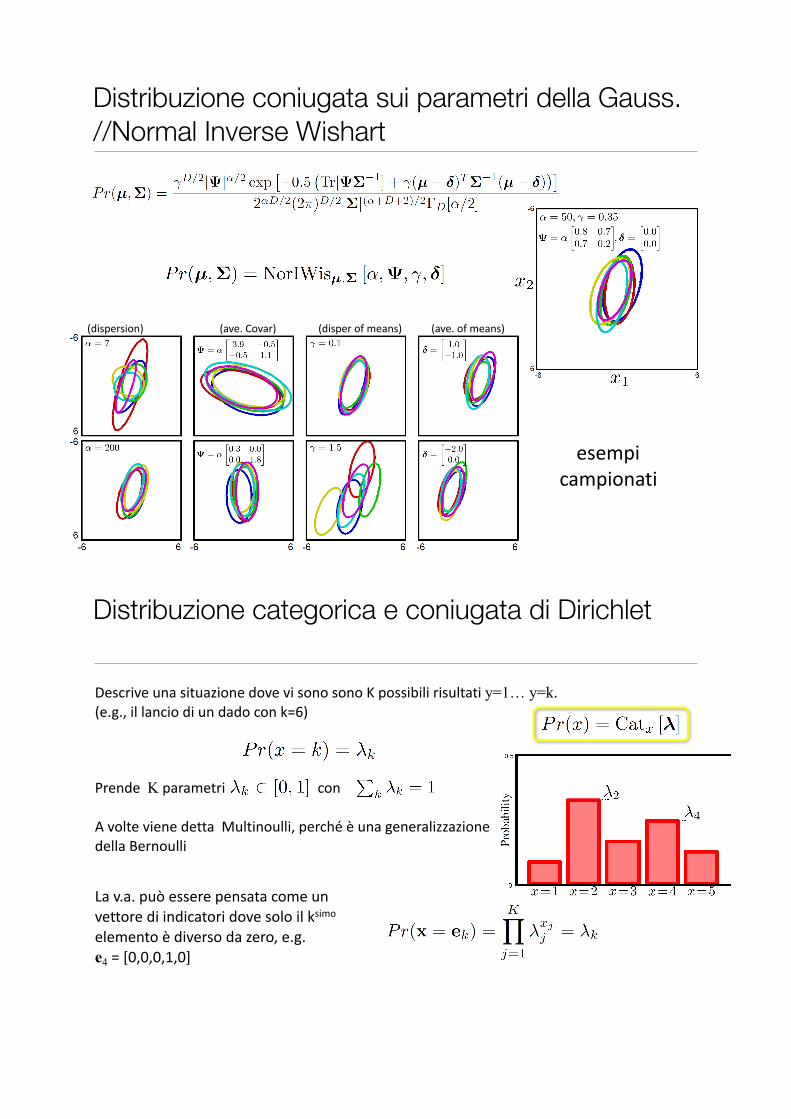
Distribuzione coniugata sui parametri della Gauss. //Normal Inverse Wishart
Computer$vision:$models,$learning$and$inference.$$©2011$Simon$J.D.$Prince
(dispersion) (ave.$Covar) (disper$of$means) (ave.$of$means)
esempi$$campionati
Distribuzione categorica e coniugata di Dirichlet
La$v.a.$può$essere$pensata$come$un$vettore$di$indicatori$dove$solo$il$ksimo$elemento$è$diverso$da$zero,$e.g.$$e4$=$[0,0,0,1,0]
Descrive$una$situazione$dove$vi$sono$sono$K$possibili$risultati$y=1… y=k.$(e.g.,$il$lancio$di$un$dado$con$k=6)$
Prende$$K$parametri$$$$$$$$$$$$$$$$$$$$$$$$$$con$
A$volte$viene$detta$$Multinoulli,$perché$è$una$generalizzazione$della$Bernoulli
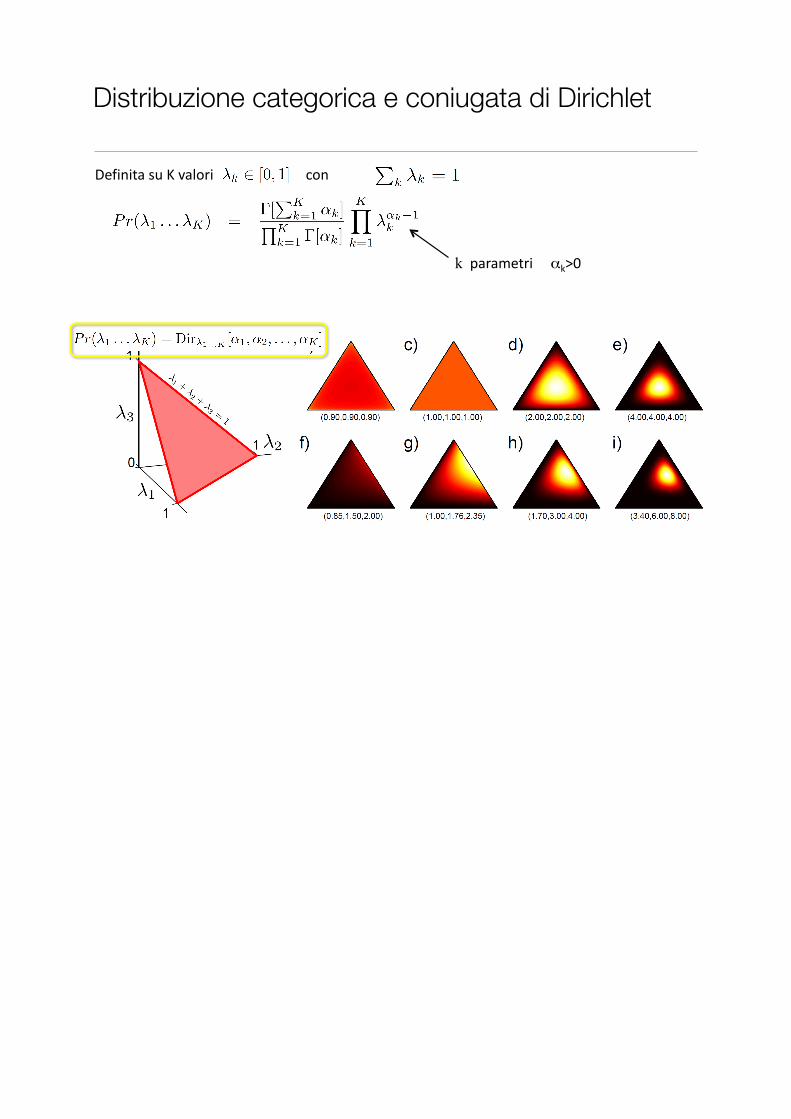
Distribuzione categorica e coniugata di Dirichlet
Definita$su$K$valori$$$$$$$$$$$$$$$$$$$$$$$$$$con
k$$parametri$$$$$αk>0





























