Embed Size (px)
Citation preview

ù ÒʪË@IjJ. Ë @ ð úÍAªË@ Õæʪ
JË @ èP@ Pð
Université Badji Mokhtar - AnnabaBadji Mokhtar-Annaba University
éK. A J« - PAJ jÓ ù k. AK.éªÓAg.
Faculté des Sciences de l’IngénioratDépartement d’Electronique
Diagnostic et surveillance des procédés industrielset de leur environnement sur la base de l’analyse
de données
THÈSE
Présentée en vue de l’obtention du diplôme de DOCTORAT 3eme CYCLE
OptionAutomatique et Signaux
Par
CHAKOUR Chouaib
Directeur de Thèse : Pr. DJEGHABA Messaoud Univ. Badji MokhtarCo-directeur de Thèse : Pr. HARKAT Mohamed Faouzi Univ. Badji Mokhtar
Devant le jury composé de :
Président : Pr. ABBASSI Hadj Ahmed Univ. Badji Mokhtar-AnnabaExaminateurs : Pr. DEBBACHE Nasr Eddine Univ. Badji Mokhtar-Annaba
Pr. MANSOURI Nora Univ. Constantine1Pr. MOUSS Leila Hayet Univ. Batna
Année Universitaire : 2015/2016


dédicace
Je dédie ce modeste travail à toutes les personnes qui me sont très chères :
À mon très cher père, Mr CHAKOUR Ali : Aucune dédicace ne saurait exprimer l’amour,
l’estime, le dévouement et le respect que j’ai toujours eu pour vous. Rien au monde ne vaut les
efforts fournis jour et nuit pour mon éducation et mon bien être. Ce travail est le fruit de tes
sacrifices que tu as consentis pour mon éducation et ma formation. Je prie que Dieu, le tout-
puissant, soit à tes côtés et t’accorde une bonne santé (amine).
À ma très chère mère, Mme CHAKOUR Zohra : Tu représentes pour moi le symbole de
la bonté par excellence, la source de tendresse et l’exemple du dévouement qui n’a pas cessé
de m’encourager et de prier pour moi. Ta prière et ta bénédiction m’ont été d’un grand secours
pour mener à bien mes études. Aucune dédicace ne saurait être assez éloquente pour exprimer
ce que tu mérites pour tous les sacrifices que tu n’as cessé de me donner depuis ma naissance,
durant mon enfance et même à l’âge adulte. Je te dédie ce travail en témoignage de mon pro-
fond amour. Je prie que Dieu, le tout puissant, te préserver et t’accorder santé, longue vie et
bonheur (amine).
À ma très chère femme et à ma très chère soeur : je vous souhaite tout le bonheur du
monde.
À mes très chers frères.
À mes grands-parents.
À toute la famille Chakour, Ziounne et Krim.
À tous ceux que j’aime et qui m’aiment.
Chouaib.
i

Remerciements
L’aboutissement à la réalisation de ce travail est le fruit de toutes les années de formation, je
tiens donc à remercier tous les enseignants du département électronique.
Mes sincères remerciements vont en premier lieu à Pr. DJEGHABA Messaoud mon Directeur
de thèse, pour sa participation à ce travail et pour ses précieux conseils. Son ouverture d’esprit et
surtout son intérêt portez à la science font de lui une source intarissable à laquelle tout étudiant
devrait s’abreuver. Je tiens à lui exprimer ma profonde gratitude et reconnaissance. Mes sincères
remerciements vont également à Pr. HARKAT Mohamed Faouzi mon Co-directeur de thèse, que
j’apprécie sa qualité professionnelle et intellectuelle. Je tiens à lui témoigner ma profonde grati-
tude.
Je remercie particulièrement monsieur ABBASSI Hadj Ahmed, professeur à l’université Badji
Mokhtar Annaba, pour ses remarques qui ont permis d’améliorer la qualité de ce mémoire, qui
de plus m’a fait l’honneur de présider le Jury de cette thèse. J’adresse toute ma reconnaissance
à monsieur DEBBACHE Naser Eddine, professeur à l’université Badji Mokhtar Annaba, pour son
acceptation d’être rapporteur sur mes travaux et pour toutes ses remarques constructives. J’ex-
prime ma profonde gratitude à madame MANSOURI Nora, professeur à l’université de Constan-
tine 1, pour ses nombreuses remarques et suggestions à améliorer la qualité de ce mémoire. Je
remercie madame MOUSS Leila Hayet, professeur à l’université de Batna, pour l’intérêt qu’elle a
porté à mes travaux en examinant ce mémoire, et pour l’honneur qu’elle me fait en participant
à ce jury.
Un immense merci à mes amies et collèges de laboratoire d’automatique et signaux (LASA),
particulièrement Fethi, Tarek, Nasreddine, Mouad, Mahmoud, Djamel, Amine, Bilel, Seif ALLAH
Al Masloul et Wassim, pour les bons moments qu’on a passés ensembles.
ii

iii

Résumé
Les travaux présentés dans ce mémoire traitent de la modélisation et du diagnostic de dé-
fauts des systèmes industriels de nature variable dans le temps. L’une des méthodes couramment
employée pour répondre à cette question est l’analyse en composantes principales (ACP) dyna-
mique.
Afin de modéliser les systèmes variants dans le temps, plusieurs approches de l’ACP dyna-
mique linéaire ont été étudiés. Selon ces études, une réduction dans les exigences de stockage
ainsi que dans le retard de la prise de décision joue un rôle fondamental dans l’évaluation de
ces techniques. Un nouvel algorithme de l’ACP récursive linéaire a été développé.
Pour la modélisation des systèmes non-linéaires, l’analyse en composantes principales non-
linéaire à noyau est présentée. La contribution de cette thèse porte principalement sur l’adapta-
tion de l’ACP non-linéaire à noyau à la modélisation et au diagnostic de défauts des processus
non-linéaires dynamiques. Deux algorithmes de l’ACP non-linéaire à noyau dynamique ont été
proposés, où les questions relatives à la sensibilité de détection, à la robustesse, et à la com-
plexité de calcul ont été pris en compte.
Les approches développées ont été testées sur le benchmark TENNESSEE EASTMAN.
Mots-clés : ACP, ACP non-linéaire, ACP à noyau, Détection et localisation de défauts, Sys-
tèmes dynamiques.
iv

Abstract
The works presented in this thesis are devoted to modeling and fault diagnosis of time va-
rying industrial systems. For this, the dynamic principal component analysis method is used.
In order to adapt with the natural changes of industrial processes, several linear techniques
of dynamic PCA were studied. According to the study, a reduction in storage requirements and
the delay in decision-making plays a fundamental role in the evaluation of these techniques. In
this context, a new algorithm of the recursive PCA was developed in the second chapter.
In the framework of modeling non-linear systems, the nonlinear principal component analy-
sis, kernel PCA, was presented. The second contribution of this thesis focuses on the adaptation
of the kernel PCA method for modeling and time varying processes monitoring. Similarly to the
linear case of PCA, two algorithms of the adaptive kernel PCA have been proposed in the third
chapter, of which problems of detection sensitivity, robustness, complexity of computation are
considered.
Key-words : PCA, Nonlinear PCA, Kernel PCA, Fault detection and diagnosis, Dynamic sys-
tem.
v

Liste des abréviations
X ∈ ℜN×m Matrice de données représentant le fonctionnement normal du système,
X Estimation de X par le modèle ACP,
E Matrice des résidus d’estimation de X,
Σ ∈ ℜm×m Matrice de covariance de X,
N Nombre d’echantillons mesurées,
m Nombre de variables (dimension de l’espace des données mesurées),
l Nombre de composantes retenues dans le modèle ACP (dimension du sous-espace des compo-
santes principales),
k Indice du temps,
x ∈ ℜm Nouveau vecteur de mesure,
x Estimation du vecteur x par le modèle ACP,
xi La ième composante du vecteur x,
x Vecteur moyen de x,
x(i) ∈ ℜm−1 Le vecteur x sans la ième composante,
P ∈ ℜN×m Matrice des vecteurs propres de Σ,
P ∈ ℜN×l Matrice des l premiers vecteurs propres de Σ,
P ∈ ℜN×m−l Matrice des m− l derniers vecteurs propres de Σ,
t Vecteurs des l premières composantes principales,
t Vecteur des m− l dernières composantes principales,
C = P P T Matrice représentant le modèle ACP,
λi ième valeur propre de Σ,
pi ième vecteur propre de Σ correspondant à λi,
Sp Sous-espace des composantes principales,
Sr Sous-espace des résidus,
E Espérance mathématique,
var La variance mathématique,
vi

zi Valeur reconstruite de la mesure xi,
ui Variance de l’erreur de reconstruction de la ième variable,
ζi ième ligne d’une matrice identité Im,
ei Erreur d’estimation sur la ième variable,
e Vecteur des erreurs d’estimation,
α Facteur d’oubli pour le vecteur de la moyenne,
β Facteur d’oubli pour la matrice de corrélation,
r Vecteur de résidus structurés,
bk Estimation de la moyenne du vecteur de mesures x(k) à l’instant k,
σk Estimation de la variance du vecteur de mesures x(k) à l’instant k,
Rk Estimation de la matrice de corrélation ou de covariance à l’instant k,
L La longeur de la fenêtre glissante,
ϕ(xi) L’image du vecteur de données x(k) dans l’espace noyau,
X La matrice de données ϕ(xi) dans l’espace de caractéristique,
bϕk Estimation de la moyenne dans l’espace à noyau du vecteur de mesures ϕ(xi) à l’instant k,
K La matrice de noyau,
Rϕk Estimation de la matrice de corrélation ou de covariance dans l’espace à noyau à l’instant k,
SPE Erreur quadratique d’estimation (squared prediction error),
T2 Statistique de Hotteling.
φ Indice combiné.
vii

Table des figures
1.1 Structure générale d’une procédure de surveillance et diagnostic. . . . . . . . . . 9
1.2 La difficulté de localiser des défauts. . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3 Différents types de défauts d’un système physique. . . . . . . . . . . . . . . . . . 12
1.4 Etapes d’un projet de diagnostic. . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.5 Principe de base du diagnostic des défaut à base de données. . . . . . . . . . . . 18
2.1 La fonction d’adaptation du modèle . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.2 Procédure d’adaptation en ligne à base d’une fenêtre glissante (MWPCA). . . . . 42
2.3 Fenêtre glissante adaptative . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
2.4 Principe de la méthode ACP récursive . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.5 La variation récursive de la moyenne, la variance et de la corrélation des mesures
en cours du temps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.6 Les deux étapes d’adaptation pour construire une nouvelle fenêtre de données. . 56
3.1 La méthode ACP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
3.2 Principe de la modélisation par l’analyse en composantes principales. . . . . . . . 69
3.3 Projection des points sur la courbe. . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3.4 Réseau à cinq couches pour l’extraction d’une seule composante principale non
linéaire. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3.5 L’idée de base de l’ACP à noyau . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
3.6 Chaîne de traitements générique des méthodes à noyaux . . . . . . . . . . . . . . 77
3.7 Estimation de la pré-image. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
4.1 Organigramme de l’algorithme ACP à noyau adaptatif (AKPCA). . . . . . . . . . . 109
4.2 Procédure de structuration de résidus par ACP partielles. . . . . . . . . . . . . . . 117
4.3 Procédure de localisation par l’ACP partielle structurée. . . . . . . . . . . . . . . . 117
5.1 Evolution des différentes variables de simulation . . . . . . . . . . . . . . . . . . 123
viii

TABLE DES FIGURES
5.2 Evolution des composantes principales . . . . . . . . . . . . . . . . . . . . . . . . 125
5.3 Pourcentage cumulé de la Vartiance (PCV) . . . . . . . . . . . . . . . . . . . . . . 127
5.4 Critère Press . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
5.5 Variance Non Reconstruite (VNR) . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
5.6 Evolution des différentes mesures et leurs estimations . . . . . . . . . . . . . . . 128
5.7 Evolution des différentes mesures et leurs estimations avec un nombre de com-
posantes principale égale à 1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
5.8 Processus de Tennessee Eastman . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
5.9 L’indice SPE et T2 en utilisant le modèle ACP statique . . . . . . . . . . . . . . . . 133
5.10 Estimation en ligne des mesures x1, x2, x7 et x10 en utilisant la MWPCA. . . . . . 134
5.11 Evolution des indices de détection SPE et T2 de la méthode MWPCA. . . . . . . . 135
5.12 Evolution des indices de détection SPE et T2 de la méthode EWPCA. . . . . . . . 135
5.13 Evolution des indices de détection SPE et T2 de la méthode MWPCA. . . . . . . . 135
5.14 Evolution des indices de détection SPE et T2 de la méthode EWPCA. . . . . . . . 135
5.15 RBCSPE : contribution à l’indice SPE calculé par la méthode MWPCA en cas de
défaut. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
5.16 RBCSPE : contribution à l’indice SPE calculé par la méthode EWPCA en cas de
défaut. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
5.17 Evolution de l’indice SPE en utilisant la méthode KPCA statique . . . . . . . . . . 138
5.18 SPE de la méthode MWKPCA. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
5.19 SPE de la méthode AKPCA. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
5.20 SPE de la méthode AKPCA avec un facteur d’oubli fixe (α = 0.9). . . . . . . . . . 139
5.21 SPE de la méthode NKPCA. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
5.22 SPE de la méthode MWKPCA. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
5.23 SPE de la méthode AKPCA. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
5.24 SPE de la méthode AKPCA avec un facteur d’oubli fixe (α = 0.9). . . . . . . . . . 140
5.25 SPE de la méthode NKPCA. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
5.26 Evolutions des SPE correspondant aux huit premiers modèles AKPCA partielles. . 142
5.27 Evolutions des SPE correspondant aux huit deuxièmes modèles AKPCA partielles. 142
ix

Liste des tableaux
2.1 Efficacité des méthodes d’adaptation. . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.1 Modèles et modes de traitement de l’ACP. . . . . . . . . . . . . . . . . . . . . . . 96
5.1 Les variables sélectionnées pour l’application . . . . . . . . . . . . . . . . . . . . 132
5.2 Performance des algorithmes MWPCA et EWPCA dans le cas de l’indice SPE. . . . 137
5.3 Performance des algorithmes MWKPCA, AKPCA et NKPCA en utilisant l’indice de
détection SPE. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
5.4 Performance des algorithmes MWKPCA, AKPCA et NKPCA en utilisant l’indice de
détection SPE. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
5.5 Signatures théoriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
x

Table des matières
1 Introduction au diagnostic 5
1.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.1.1 Objectif de la supervision . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.1.2 Terminologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2 Surveillance et diagnostic . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3 Typologie de défauts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3.1 Défauts capteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3.2 Défauts actionneurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.3.3 Défauts composants (Défauts système) . . . . . . . . . . . . . . . . . . . . 12
1.3.4 Caractérisation de défauts . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.4 Différentes méthodes de diagnostic . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.4.1 Les approches analytiques . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.4.2 Les approches à base de connaissances . . . . . . . . . . . . . . . . . . . . 16
1.4.3 Les approches à base de traitement de données (Data-Driven Approaches) 17
1.5 Les performances d’un système de diagnostic . . . . . . . . . . . . . . . . . . . . 19
1.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2 Modélisation à base de l’analyse en composantes principales (ACP) 22
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.2 Principe de l’analyse en composantes principales . . . . . . . . . . . . . . . . . . 24
2.3 Identification du modèle ACP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.3.1 Pourcentage cumulé de la variance totale (PCV) . . . . . . . . . . . . . . . 33
2.3.2 Critère de validation croisée . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.3.3 Minimisation de la variance d’erreur de reconstruction (VER) . . . . . . . 35
2.4 Analyse en Composantes Principales Adaptative (APCA) . . . . . . . . . . . . . . 38
2.4.1 Les concepts de l’adaptation . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.4.2 L’ACP à base de fenêtre glissante (Moving Window PCA, MWPCA) . . . . 42
xi

TABLE DES MATIÈRES
2.4.3 L’ACP Récursive (RPCA) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
2.4.4 L’ACP à base de fenêtre glissante rapide (Fast Moving Window PCA) . . . 54
2.4.5 L’ACP Incrémentale (IPCA) . . . . . . . . . . . . . . . . . . . . . . . . . . 58
2.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3 Analyse en composantes principales non linéaire à noyau (Kernel PCA) 66
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
3.2 Principe de l’ACP non linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
3.3 ACP non linéaire à noyau (kernel PCA) . . . . . . . . . . . . . . . . . . . . . . . . 72
3.3.1 Principe de la méthode ACP à noyau . . . . . . . . . . . . . . . . . . . . . 72
3.3.2 L’astuce du noyau (kernel trick) . . . . . . . . . . . . . . . . . . . . . . . . 73
3.3.3 Les fonctions noyaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
3.3.4 Modèle ACP à noyau (KPCA) . . . . . . . . . . . . . . . . . . . . . . . . . 79
3.3.5 Centrage des données dans l’espace à noyau . . . . . . . . . . . . . . . . 81
3.4 Reconstruction de données (Problème de Pré-image) . . . . . . . . . . . . . . . . 82
3.5 ACP à noyau adaptative (Adaptive KPCA, AKPCA) . . . . . . . . . . . . . . . . . . 85
3.5.1 ACP à noyau à base de fenêtre glissante (MWKPCA) . . . . . . . . . . . . 87
3.5.2 ACP à noyau récursive (RKPCA) . . . . . . . . . . . . . . . . . . . . . . . . 89
3.5.3 ACP à noyau neuronale (NKPCA) . . . . . . . . . . . . . . . . . . . . . . . 95
3.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
4 Détection et localisation de défauts 101
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
4.2 Détection de défauts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
4.2.1 L’erreur de Prédiction Quadratique, SPE . . . . . . . . . . . . . . . . . . . 103
4.2.2 Statistique T2 de Hotelling . . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.2.3 Indice combiné . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.3 Détection de défauts dans l’espace à noyau . . . . . . . . . . . . . . . . . . . . . . 105
4.3.1 Indice SPE dans H . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
4.3.2 Indice T2 dans H . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
4.3.3 Indice combiné dans H . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
4.4 Procédure de surveillance des systèmes dynamiques . . . . . . . . . . . . . . . . 107
4.5 Localisation de défauts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
4.5.1 Localisation par calcul des contributions . . . . . . . . . . . . . . . . . . . 112
4.5.2 Localisation par contributions à base de reconstruction (RBC) . . . . . . . 113
4.5.3 Localisation par ACP partielle . . . . . . . . . . . . . . . . . . . . . . . . . 115
4.6 Localisation dans le cas du noyau par RBC-KPCA . . . . . . . . . . . . . . . . . . 118
4.6.1 Algorithme itératif du point fixe . . . . . . . . . . . . . . . . . . . . . . . 119
xii

TABLE DES MATIÈRES
4.6.2 Méthode d’optimisation de Newton . . . . . . . . . . . . . . . . . . . . . . 119
4.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
5 Application 122
5.1 Exemple illustratif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
5.2 Application au processus de Tennessee Eastman (TE) . . . . . . . . . . . . . . . . 131
5.2.1 Description du TE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
5.2.2 Résultats de simulation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
5.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
xiii

Introduction générale
Les enjeux économiques en constante évolution amènent à produire toujours plus. La moindre
défaillance sur un processus est néfaste dans un environnement où le rendement est primordial.
Il est donc nécessaire de s’assurer en permanence du bon fonctionnement du processus vis-à-vis
des objectifs qui lui ont été assignés. Les informations délivrées par les mesures des capteurs
permettent de traduire le comportement d’un système donné. La qualité des ces mesures est un
élément essentiel pour permettre la surveillance et l’évaluation des performances d’un proces-
sus. Elle peut être accrue en améliorant la précision de l’instrumentation et en multipliant le
nombre de capteurs. Pour des raisons techniques ou financières, cette solution, où une même
grandeur est mesurée par plusieurs capteurs est réservée aux industries de haute technologie ou
à celle présentant de hauts risques.
Le diagnostic peut être vu comme une tentative pour expliquer un comportement anormal du
système en analysant ses caractéristiques pertinentes. C’est un raisonnement menant à l’iden-
tification de la cause d’une anomalie à partir des informations révélées par des observations
(mesure, signe, symptôme). Effectuer le diagnostic de fonctionnement sur un système consiste
donc à détecter et localiser les défauts internes (affectant le processus lui même), les défauts ex-
ternes (affectant les actionneurs, et les capteurs), puis à estimer les caractéristiques principales
des défauts mis en évidence (leurs amplitudes). Il s’agit de mettre en place des fonctions per-
mettant de détecter et de localiser les composants défaillants incapables de remplir totalement
les missions pour lesquelles ils ont été choisis. En effet, ils contribuent, par une détection rapide
et précoce, à faire gagner des points de disponibilité et de production aux capitaux investis dans
l’outil de production. Afin d’atteindre ces objectifs, il est nécessaire de pouvoir modéliser le com-
portement du système selon sa nature (continu, ou discret) et le niveau d’abstraction souhaité.
Il existe plusieurs approches pour aborder et traiter cette question. Deux grandes familles se
distinguent, celles qui se basent sur les modèles des processus et les autres qui s’appuient sur
l’analyse des données.
Les procédés industriels modernes sont toujours équipés de systèmes de contrôle. Ils per-
mettent la régulation du processus autour de l’objectif désiré et d’assurer son bon fonctionne-
1

TABLE DES MATIÈRES
ment. Les données collectées sur leur fonctionnement sont stockées dans une base de données.
Leur traitement permet d’élaborer des méthodes de modélisation, et d’observation du compor-
tement du système. L’analyse en composantes principales (ACP) s’avère être l’outil le plus utilisé
pour extraire les caractéristiques de ces données. L’ACP permet de générer un modèle du pro-
cessus basé sur la connaissance issue du système sans avoir une forme canonique et explicite
d’un modèle entrées/sorties. Elle consiste à étudier les relations linéaires entre les variables à
surveiller. Comme c’est une opération de projection linéaire, seules les dépendances linéaires
entre les variables peuvent être représentées. Les systèmes réels sont non linéaires. Leur prise
en charge par l’ACP classique n’est pas du tout adaptée. C’est pourquoi, beaucoup d’études sur
son extension ont vu le jour. Parmi elles, l’ACP couplée aux méthodes à noyaux. Ces dernières
exploitent la théorie des noyaux. L’idée principale consiste à transformer les données via une
application non linéaire, dans un espace de dimension élevée, où l’ACP classique est appliquée.
Dans ce mémoire, l’ACP à noyaux est utilisée pour la modélisation et le diagnostic de fonction-
nement des processus non-linéaires.
Un autre facteur important caractérise les processus industriels. Il s’agit de leur dynamique.
En effet, leur comportements et leurs caratéristiques statistiques changent dans le temps. La
surveillance de ces processus à partir d’un modèle statique, construit sur l’historique de données,
pauvre en information, ne serait pas fiable. Afin de remédier à ce problème, il apparait alors
nécessaire de rechercher une version adaptative du modèle ACP et du modèle ACP à noyau,
qui tienne compte de cette dynamique. La surveillance et le diagnostic de défauts des systèmes
dynamiques font partie du travail élaboré dans cette thèse.
La surveillance et le diagnostic des défaillances nécessite des stratégies ou des procédures
permettant l’interprétation du comportement observé. Les stratégies de surveillance ou de dé-
tection de défaut comprennent une étape de génération de résidus ou d’indicateurs de défauts,
qui caractérise un écart par rapport aux conditions de fonctionnement normales. Pour le cas
de l’ACP et l’ACP à noyau deux indices de détections sont utilisés, la statistique SPE (Squared
Prediction Error) et la statistique de Hotelling T2. L’évaluation de ces indices conduit à la prise
de décision. Après la détection de défaut, le diagnostic consiste à le localiser et l’identifier. Une
étude détaillée sur les différentes techniques fréquemment rencontrées dans la littérature pour
la localisation des défauts, est menée dans ce travail pour le cas de l’ACP et l’ACP non-linéaire à
noyau. La présente thèse se compose de cinq chapitres organisés de la manière suivante :
– Chapitre 01 :
Dans ce chapitre, et à partir de la littérature, nous avons rappelé quelques définitions rela-
tives à la surveillance et au diagnostic, pour ensuite présenter les méthodes utilisées. Pour
ces dernières, deux grandes familles se distinguent, celle dite avec modèle analytique et
celle dite sans modèle. L’objectif de ce chapitre étant d’éclaircir l’intérêt de l’utilisation des
méthodes dites sans modèle, notament les méthodes statistiques comme l’analyse en com-
2

TABLE DES MATIÈRES
posantes principales et ses extensions pour la détection et la localisation et l’identification
des défauts de processus.
– Chapitre 02 :
Le deuxième chapitre est décomposé en deux parties. Dans la première partie, le principe
de la modélisation à base de la méthode ACP est présenté. Les différentes démarches à
suivre pour avoir un modèle ACP statique adéquat sont discutés. L’identification du modèle
ACP nécessite la détermination du nombre de composantes à retenir ainsi que l’estimation
des paramètres de ce dernier. Plusieurs approches sont présentées pour identifer le nombre
optimal de composantes principales à retenir dans le modèle ACP. Dans la seconde partie,
la version dynamique de la méthode ACP est abordée afin de surmonter les limitations
de l’ACP statique à modéliser le comportement des systèmes dynamiques. Les différents
mécanismes de mise à jour du modèle ACP sont discutés.
– Chapitre 03 :
Le troisième chapitre traite de l’ACP non linéaire. Un état de lieu est fait pour les diffé-
rentes extensions de l’ACP dans le cas non-linéaire. Plusieurs approches se distinguent.
Celles qui reposent sur les réseaux de neurones, sur les courbes principales et sur les fonc-
tions à noyaux. Dans ce chapitre, on s’est focalisé sur la méthode ACP à noyau. Dans une
deuxième partie, l’ACP non-linéaire à noyau dynamique est explicitée pour modéliser les
systèmes non-linéaires dynamiques. Les différents mécanismes permettant l’adaptation du
modèle ACP à noyau sont présentés. Nous présentons deux nouveaux mécanismes d’adap-
tation sont proposés.
– Chapitre 04 :
Ce chapitre est consacré à la détection et localisation de défauts par analyse en compo-
santes principales. La statistique T2 de Hotelling calculée à partir des premières compo-
santes principales et l’erreur quadratique d’estimation SPE sont les deux indices le plus
souvent utilisés.
Pour la localisation de défauts, plusieurs approches sont exposées. La première se base
sur le même principe que les approches classiques utilisant des bancs de modèles, comme
l’approche par ACP partielle qui utilise des ACP avec des ensembles réduits de variables.
La seconde est basée sur le calcul des contributions des variables à l’indice de détection.
La dernière fait la combinaison entre la méthode de calcul des contributions et celle qui
repose sur le principe de la reconstruction, appelée méthode de reconstruction à base de
contribution (RBC). Comme pour le cas linéaire, les méthodes de détection et localisation
de défauts par ACP à noyau seront présentées.
– Chapitre 05 :
Le dernier chapitre de cette thèse sera consacré à l’application de l’analyse en composantes
principales à noyau pour la détection et la localisation de défauts de capteurs du bench-
3

TABLE DES MATIÈRES
mark Tennesses Eastman. Le simulateur du processus chimique Tennessee Eastman Chal-
lange Process (TE), est considéré comme une installation pilote de l’industrie chimique
développée par Eastman company. Il est beaucoup utilisé par la communauté scientifique
pour évaluer les performances des algorithmes de commande et de diagnostic.
Enfin, une synthèse des résultats développés dans cette thèse, est présentée en conclusion.
4

Chapitre 1Introduction au diagnostic
Sommaire1.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.1.1 Objectif de la supervision . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.1.2 Terminologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2 Surveillance et diagnostic . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3 Typologie de défauts . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3.1 Défauts capteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3.2 Défauts actionneurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.3.3 Défauts composants (Défauts système) . . . . . . . . . . . . . . . . . . . 12
1.3.4 Caractérisation de défauts . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.4 Différentes méthodes de diagnostic . . . . . . . . . . . . . . . . . . . . 13
1.4.1 Les approches analytiques . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.4.2 Les approches à base de connaissances . . . . . . . . . . . . . . . . . . . 16
1.4.3 Les approches à base de traitement de données (Data-Driven Approaches) 17
1.5 Les performances d’un système de diagnostic . . . . . . . . . . . . . 19
1.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.1 Introduction
La complexité des systèmes industriels s’accroît continuellement. Elle est en rapport avec la
technologie employée, aux processus de management et de gestion de la production, utilisé, et
surtout avec la quantité énorme d’informations exploitées. L’objectif reste bien sûr la recherche
du meilleur fonctionnement possible, le plus performant et répondant aux exigences techniques
de la production mais aussi aux impératifs de sûreté et de sécurité pour les équipements et
les personnes. Cet aspect, devenu un élément fondamental dans la conduite des systèmes de
5

Introduction
production, est rajouté de plus en plus dans le schéma global de l’automatisation des proces-
sus. On parle aujourd’hui d’automatisation intégrée. Ce rajout se décline en deux couches, l’une
concerne la surveillance des systèmes (Détection et localisation de défauts) et la seconde de
niveau supérieur, traite de la supervision (Décision). Cette intégration n’est pas encore géné-
ralisée. L’intervention des opérateurs dans les salles de contrôle continue et continuera certai-
nement même avec des systèmes de surveillance beaucoup plus élaborés. Mais l’avantage de
l’intégration de ces systèmes de supervision est leur capacité d’analyse d’un nombre important
d’informations et l’aide qu’il procure à l’opérateur pour la prise de décision.
"L’homme et sa sécurité doivent constituer la première préoccupation de toute aventure techno-
logique ." - Albert Einstein-
1.1.1 Objectif de la supervision
La recherche croissante d’une meilleure compétitivité (productivité, qualité, . . .) pousse les
entreprises à reproduire des machines et des instruments de mesures ayant une grande fiabilité
et disponibilité. Cependant, un système quelle que soit sa modernité et sa robustesse, est affecté
par des dysfonctionnements qui peuvent compromettre son bon fonctionnement. Les systèmes
de supervision qui intègrent plusieurs activités (surveiller, visualiser, analyser, piloter, agir, . . .)
permettent de rapporter les fonctionnements normaux et anormaux des systèmes, afin de four-
nir à l’opérateur des critères suffisants pour la prise de décisions.
La supervision correspond à l’action de surveiller le fonctionnement du système afin de
prendre des décisions adéquates lorsque le système est hors de l’objectif désiré. Le système de
surveillance observe en continu l’évolution de l’équipement à travers des données quantifiables
et/ou qualifiables collectées à partir du système surveillé. Ces données permettent de signaler
à l’opérateur les écarts détectés par apport au comportement nominal prévu. Ceci permettra de
mettre en œuvre les actions de maintenance préventives et correctives. D’une façon générale,
le but de la surveillance est de détecter le mode de fonctionnement du système, tandis que le
but du diagnostic est d’identifier le dysfonctionnement du système une fois le mode défaillant
détecté.
1.1.2 Terminologie
Partant du fait que le diagnostic de défaut est réparti sur plusieurs domaines technologiques,
un comité technique SAFEPROCESS de la Fédération internationale de contrôle automatique
IFAC a essayé de proposer une terminologie unifiée (Isermann and Ballé 1997, Isermann 1997,
Patton 1999, Frank et al. 2000). Nous présentons quelques définitions de ce comité extraites des
6

Introduction
références suivantes (Derbel 2009, Laouti 2012, Fragkoulis 2008) :
– La surveillance : C’est une tâche continue en temps réel déterminant les conditions pos-
sibles d’un système physique, tout en reconnaissant et en indiquant des anomalies du
comportement.
– Défaut : C’est une déviation du système par rapport à son comportement normal, qui ne
l’empêche pas de remplir sa fonction. Un défaut est donc une anomalie qui concerne une
ou plusieurs propriétés du système, pouvant aboutir à une défaillance et parfois même à
une panne.
– Dysfonctionnement : est l’irrégularité intermittente dans l’accomplissement de la fonction
souhaitée du système.
– Dégradation : Tout état qui se caractérise par une évolution irréversible des caractéristiques
d’un système est une dégradation. La dégradation peut être liée à des facteurs directs, tels
que l’usage, le temps, . . ., ou à des facteurs indirects, tels que l’humidité, la température,
. . . etc. La dégradation peut aboutir à une défaillance quand les performances du système
sont en dessous d’un seuil d’arrêt défini par les spécifications fonctionnelles.
– Défaillance : Une défaillance est une anomalie altérant ou empêchant l’aptitude d’une unité
fonctionnelle à accomplir la fonction souhaitée. Une défaillance correspond à un passage
d’un état à un autre, par opposition à une panne qui est un état. Par abus de langage, cet
état de panne pourrait être appelé mode de défaillance.
– Panne : La conséquence d’une défaillance, c’est l’interruption permanente d’une capacité
du système pour effectuer une fonction requise dans des conditions de fonctionnement
spécifiées et pouvant provoquer son arrêt complet.
– Résidu : Les signaux portants de l’information, basés sur l’écart entre les mesures et leur
estimation.
– Seuil : C’est la valeur limite de l’écart d’un résidu avec le zéro. Ainsi s’il est dépassé, un
défaut est déclaré comme détecté.
– Symptôme : correspond à une ou plusieurs observations qui révèlent un dysfonctionne-
ment. Il s’agit d’un effet qui est la conséquence d’un comportement anormal.
– Observation : est une information obtenue à partir du comportement ou du fonctionne-
ment réel du système.
– Mesure : est une observation élémentaire du fait qu’elle reflète une et une seule grandeur
physique. Elle est représentée par une variable dont le contenu est l’image d’une grandeur
physique. Son obtention s’effectue par l’intermédiaire de capteurs.
– Mode de fonctionnement : Un système présente généralement plusieurs modes de fonction-
nement. On peut observer des modes de plusieurs types parmi lesquels :
1. Mode de fonctionnement nominal : c’est le mode où l’équipement ou le système in-
7

Surveillance et diagnostic
dustriel remplit sa mission dans les conditions de fonctionnement requises par le
constructeur et avec les exigences attendues de l’exploitant.
2. Mode de fonctionnement dégradé : qui correspond soit à l’accomplissement partiel de
la mission, soit à l’accomplissement de celle-ci avec des performances moindres. En
d’autres termes, il y a une dégradation dans l’équipement ou le système, mais pas de
défaillance.
3. Mode de défaillance : qui correspond à des mauvais fonctionnements du système, c’est-
à-dire qu’il y a une défaillance, soit après dégradation soit après défaillance brusque.
1.2 Surveillance et diagnostic
La complexité croissante des systèmes automatisés s’accompagne d’une demande toujours
plus forte de la disponibilité et de la sécurité des installation industrielles. Il est en effet finan-
cièrement inutile de concevoir des installations sans cesse plus complexes, si celles-ci doivent
régulièrement tomber en panne et présenter un danger pour les personnes, l’environnement et
les biens. L’accroissement de la disponibilité peut être obtenu par une amélioration de la fiabi-
lité des unités fonctionnelles mais aussi par la mise en œuvre d’une stratégie de maintenance
adaptée à l’installation (R. Toscano 2004).
La surveillance est la détection d’une anomalie. Le diagnostic consiste en la détermination
des composants défaillants au sein d’un système physique. Il est effectué à travers la localisation
et l’identification des défauts, afin de maintenir le fonctionnement nominal du système malgré
l’apparition de défauts. La détection a pour objectif de signaler les comportements qui diffèrent
d’un fonctionnement normal. Elle se fait à travers l’enregistrement des informations pouvant
indiquer la survenue d’éventuelles anomalies dans le comportement du système. Cette tâche est
ensuite complétée par celle de localisation qui doit indiquer quel organe ou quel composant
est affecté par le défaut. Enfin, la tâche d’identification a pour objet de caractériser le défaut
en durée et en amplitude afin d’en déduire la sévérité. Le diagnostic constitue donc une étape
d’une procédure plus complète que nous désignons sous le nom de surveillance. La figure (1.1)
montre la structure générale d’un système de surveillance.
La détection de défauts
Un système de surveillance a comme première vocation d’émettre à partir des information
générées par les capteurs, des alarmes dont l’objectif est d’attirer l’attention de l’opérateur de
supervision sur l’apparition d’un ou plusieurs événements susceptibles d’affecter le bon fonction-
nement de l’installation. Le concept de base des systèmes de surveillance est la vérification de la
cohérence des diverses informations disponibles sur le système. La fonction de détection permet
8

Surveillance et diagnostic
FIGURE 1.1 – Structure générale d’une procédure de surveillance et diagnostic.
de discerner tout écart du système par rapport à son état de fonctionnement normal (Marzat
2011). Ceci n’est possible que s’il existe un certain degré de redondance entre ces informations.
Les premières techniques de détection de défauts consistent à dupliquer les composants
d’instruments de mesure pour augmenter la fiabilité des systèmes. Cela nous permet de choisir
la mesure saine à partir des mesures disponibles. Cette approche s’appelle la redondance maté-
rielle. Elle a pour avantage d’être relativement fiable et simple à mettre en œuvre. Par contre,
elle s’avère très coûteuse et peut poser des problèmes de surcharge et d’encombrement matériel
(Fellouah 2007). En outre, le champ d’application de la redondance matérielle se limite essen-
tiellement aux défauts de capteurs ; très peu d’applications pratiques autorisent la redondance
matérielle d’actionneurs.
Il est donc souvent plus judicieux de faire appel à la redondance analytique, qui est très
intéressante à la fois sur le plan financier et technique puisqu’elle se base uniquement sur l’ex-
ploitation des relations existantes entre les différentes variables mesurées ou estimées. Celles-ci
peuvent être issues de l’expression mathématique de lois physiques ou peuvent être déduites
d’une analyse statistique des mesures. Ainsi, elle permet de réduire le degré de redondance phy-
sique. Son champ d’application ne se limite donc pas aux pannes de capteurs mais s’étend aux
pannes des actionneurs ou à celles du procédé lui-même (D. Maquin 2005). Le processus de
détection de défauts proprement dit est donc composé essentiellement de deux phases (Chow
et al., 1984) :
1. Génération des résidus : Cette étape consiste à créer un signal (résidu) qui vérifie la co-
hérence entre un comportement observé et un comportement attendu. En absence de dé-
faillance, le résidu r(t) doit avoir une valeur nulle. En présence de défaut f(t) le résidu
aura une valeur non nulle.
r(t) = 0 si f(t) = 0
r(t) = 0 si f(t) = 0
9

Surveillance et diagnostic
2. Evaluation des résidus : Cette phase permet d’analyser les indicateurs de défaut générés,
et mettre une règle de décision, définir un seuil T (fixe, adaptatif, ou statistique) qui va
déterminer l’instant de changement d’état de fonctionnement du système. La détection de
défaut s’opère alors de la façon suivante :
| r(t) |≤ T si f(t) = 0
| r(t) |> T si f(t) = 0
La localisation de défauts
Le mot diagnostic peut avoir plusieurs interprétations. On note qu’un diagnostic est mieux
connu et établi dans les cas des maladies humaines plutôt que dans les défauts des systèmes
(Fortuna et al., 2006). Le diagnostic peut être vu comme une tentative pour expliquer un mau-
vais comportement du système en analysant ses caractéristiques pertinentes qui sont souvent
appelées symptômes ou parfois indicateurs de défauts. Le diagnostic des systèmes a pour ob-
jectif de localiser la cause d’une défaillance ou d’un défaut. Afin d’établir un diagnostic, c’est à
dire une localisation, nommée égalemment isolation de défaut, il faut être capable de décrire
une situation, de l’analyser puis de l’interpréter à l’aide d’un raisonnement logique fondé sur un
ensemble d’informations provenant d’une inspection, d’un contrôle ou d’un test.
Cette démarche peut se décliner en trois étapes. La première consiste à définir les caracté-
ristiques ou les symptômes du processus. La description d’une situation consiste en l’acquisition
d’informations renseignant sur l’état du système. La deuxième étape représente une descrip-
tion des situations types. Ces situations sont les états ou les modes que peut avoir un système
tels que les modes normaux, anormaux ou évolutifs. La dernière étape consiste à établir des
liens entre les symptômes et les situations types (Benchimol et al., 1986). La localisation ou
l’isolation d’une défaillance consiste à remonter les symptômes pour retrouver l’ensemble des
éléments défaillants. Ce problème est difficile à résoudre. En effet, il est possible de déterminer
une défaillance, ou une panne résultant d’un défaut. Par contre, le problème inverse est plus
difficile à résoudre, puisque une panne peut résulter d’un ou plusieurs défauts (Fig.1.2).
Pour détecter un défaut, un seul résidu r(t) est à la limite nécessaire. Cependant plusieurs
résidus sont souvent requis pour l’isolation des défauts. Pour pouvoir localiser efficacement un
ou plusieurs défauts, le vecteur résidu doit avoir un certain nombre de propriétés permettant
de caractériser de manière unique chaque défaut (Gertler 1992). Deux types de génération de
résidus peuvent se distinguer pour localiser un défaut (Patton et al., 1994, Gertler 1998) : les
résidus directionnels et résidus structurés.
– Les résidus directionnels : L’idée de cette approche est de générer un résidu sous la
forme d’un vecteur. En présense d’un défaut donné, le vecteur résidu est orienté suivant
10

Typologie de défauts
FIGURE 1.2 – La difficulté de localiser des défauts.
une direction privilégiée de l’espace des résidus. L’étape de localisation de défauts consiste
alors à déterminer, parmi les différentes directions prédéfinies, laquelle est la plus proche
de celle engendrée par le vecteur de résidus.
– Les résidus structurés : Un résidu structuré est caractérisé par la propriété suivante :
le résidu répond seulement à un sous-ensemble de défauts spécifiques, et un seul sous-
ensemble de résidus réagit, lorsqu’un défaut est apparaît (Gertler 1998). Autrement dit,
un résidu structuré est sensible à un sous ensemble de défauts et insensible aux autres.
L’identification de défauts
L’identification ou l’estimation du défaut est une tâche plus délicate qui nécessite une mo-
dèlisation du comportement du système et des connaissances sur les défaillances. Obtenir une
estimation du défaut, permet bien entendu de donner une image beaucoup plus précise de l’état
du système (Methnani 2012).
1.3 Typologie de défauts
Un défaut est défini comme étant un écart non permis entre la valeur réelle d’une caractéris-
tique du système et sa valeur nominale. Trois types de défauts sont distingués, comme illustré
sur la Figure 1.3 : défaut actionneur, défaut capteur et défaut système (ou défaut composant).
1.3.1 Défauts capteurs
Un capteur est un dispositif transformant l’état d’une grandeur physique observée en une
grandeur utilisable. Les capteurs se distinguent de l’instrument de mesure par le fait qu’ils ne
s’agit que d’une simple interface entre un processus physique et une information manipulable.
Ils permettent de communiquer les informations concernant l’état et le comportement interne
11

Typologie de défauts
FIGURE 1.3 – Différents types de défauts d’un système physique.
du processus. Ainsi, un défaut capteur caractérise une mauvaise image de la grandeur phy-
sique à mesurer. Pour les systèmes en boucle fermée, les mesures issues de ces capteurs sont
utilisées pour la génération du signal de commande. Par conséquent, l’élaboration du signal de
commande est en effet inefficace, si les informations prises en compte par l’algorithme de com-
mande sont erronées et/ou incohérentes. Par conséquent, la présence d’un défaut capteur donne
un signal de commande inexact et inefficace.
1.3.2 Défauts actionneurs
L’actionneur est un élément de la partie opérative capable de produire un phénomène phy-
sique (déplacement, dégagement de chaleur, émission de lumière . . .) à partir de l’énergie qu’il
reçoit. Le plus souvent, les actionneurs transforment un type d’énergie en un autre (à titre
d’exemple, le cas d’un moteur qui transforme de l’énergie électrique en énergie mécanique).
En conséquence, les défauts actionneurs agissent au niveau de la partie opérative. Ils s’addi-
tionnent aux signaux de commandes du système, et engendrent des problèmes liés aux organes
qui agissent sur l’état du système.
1.3.3 Défauts composants (Défauts système)
Les défauts composants sont des défauts qui affectent les composants du système lui même.
Ce sont les défauts qui ne peuvent pas être classifiés ni parmi les défauts actionneurs ni parmi
les défauts capteurs. Ce type de défauts correspond à une dégradation des composants du sys-
tème par un changement des paramètres internes. La représentation mathématique des défauts
composants est souvent difficile à déterminer et demande des essais expérimentaux extensifs.
Ces défaillances sont dues à des modifications de la structure ou des paramètres du modèle, et
en général, elles se traduisent par un changement dans l’équation d’états. Ces défauts induisent
une instabilité du système.
12

Différentes méthodes de diagnostic
1.3.4 Caractérisation de défauts
Les défauts sont caractérisés d’une part, par leur modélisation mathématique et d’autre part
par leur comportement dans le temps. Les défauts peuvent être classés selon leurs évolutions
temporelles. Ils peuvent être brusques, intermittents ou graduels, additifs ou multiplicatifs (Frag-
koulis 2008, Fellouah 2007, Methnani 2012, Sallem 2013).
– Brusque : ce type de défaut se caractérise par un comportement temporel discontinu.
Cette évolution, si elle ne correspond pas aux évolutions dynamiques normales attendues
pour la variable (changement de consigne), est caractéristique d’une panne brutale de
l’élément en question : arrêt total ou partiel de connexion.
– Intermittent : c’est un défaut caractéristique de faux contact ou de panne intermittente
des capteurs. Ce type de défaut est un cas particulier de défaut abrupt avec la propriété
particulière qu’il revient de façon aléatoire à sa valeur normale.
– Graduel : c’est un défaut caractéristique de l’usure d’une pièce. Il est très difficile à dé-
tecter à cause de son évolution temporelle qui peut être confondue avec une modification
paramétrique lente représentant la non-stationnarité du procédé.
1.4 Différentes méthodes de diagnostic
Le contrôle des processus joue un rôle très important dans le domaine de la gestion des uni-
tés de production. Malgré l’immense progrès dans le domaine de l’automatisation des processus
ces trois dernières décennies, le contrôle ou la supervision restent largement une activité ma-
nuelle, effectuée par des opérateurs humains. Cette dépendance aux opérateurs humains pour
faire face en urgence à des événements anormaux est devenue de plus en plus difficile en rai-
son de plusieurs facteurs. Le contrôle est compliqué en raison de la taille et la complexité des
installations industrielles modernes. Il est difficile en raison de la vaste portée de l’activité de
supervision qui englobe une variété de tâches à résoudre. Il s’agit de détecter en temps opportun
un événement anormal, diagnostiquer ses origines, puis prendre des décisions de contrôle et de
surveillance, appropriés.
A l’heure actuelle, il existe plusieurs communautés de recherche, telles que la communauté
de l’automatique, de la productique, de l’intelligence artificielle qui s’intéressent au domaine
de la supervision, et plus particulièrement au diagnostic, dans le but principal d’assister les
opérateurs dans la gestion des événements anormaux. En raison du grand intérêt donné aux
problèmes rencontrés dans le domaine du diagnostic, différentes approches ont été développées
au cours des ces dernières années. Les différentes techniques de diagnostic ont pour objectif la
comparaison du fonctionnement du système réel à une référence illustrant son fonctionnement
13
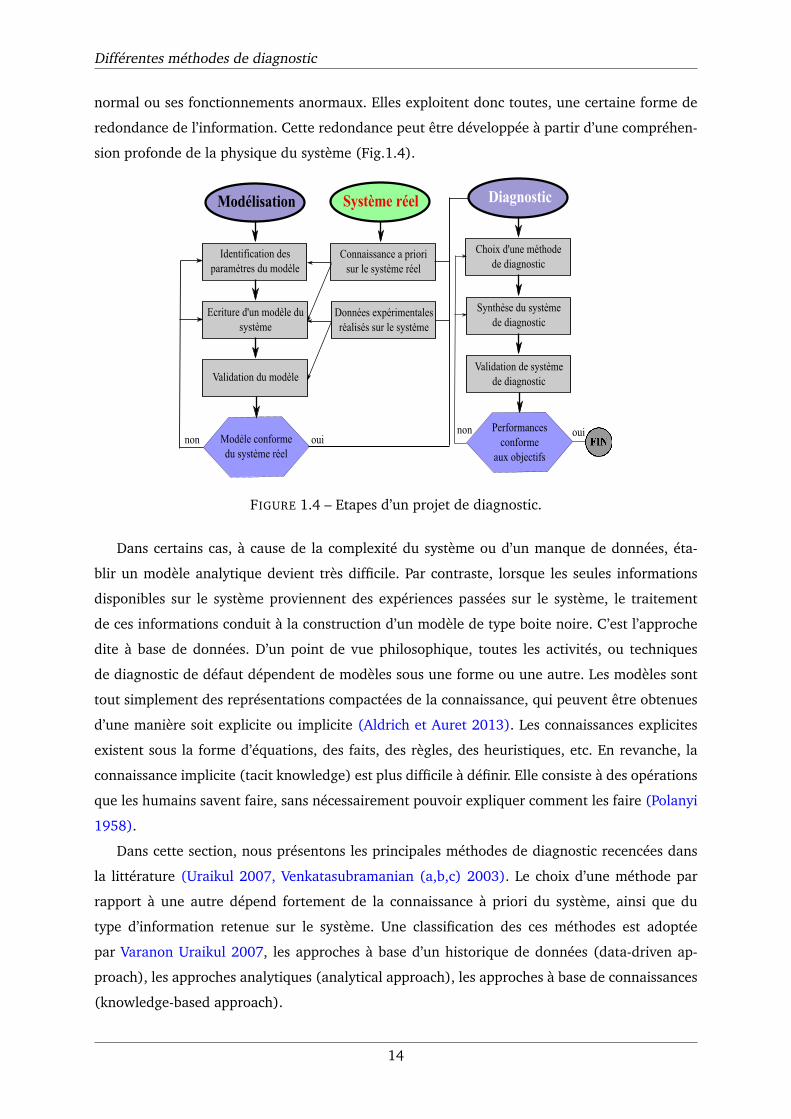
Différentes méthodes de diagnostic
normal ou ses fonctionnements anormaux. Elles exploitent donc toutes, une certaine forme de
redondance de l’information. Cette redondance peut être développée à partir d’une compréhen-
sion profonde de la physique du système (Fig.1.4).
FIGURE 1.4 – Etapes d’un projet de diagnostic.
Dans certains cas, à cause de la complexité du système ou d’un manque de données, éta-
blir un modèle analytique devient très difficile. Par contraste, lorsque les seules informations
disponibles sur le système proviennent des expériences passées sur le système, le traitement
de ces informations conduit à la construction d’un modèle de type boite noire. C’est l’approche
dite à base de données. D’un point de vue philosophique, toutes les activités, ou techniques
de diagnostic de défaut dépendent de modèles sous une forme ou une autre. Les modèles sont
tout simplement des représentations compactées de la connaissance, qui peuvent être obtenues
d’une manière soit explicite ou implicite (Aldrich et Auret 2013). Les connaissances explicites
existent sous la forme d’équations, des faits, des règles, des heuristiques, etc. En revanche, la
connaissance implicite (tacit knowledge) est plus difficile à définir. Elle consiste à des opérations
que les humains savent faire, sans nécessairement pouvoir expliquer comment les faire (Polanyi
1958).
Dans cette section, nous présentons les principales méthodes de diagnostic recencées dans
la littérature (Uraikul 2007, Venkatasubramanian (a,b,c) 2003). Le choix d’une méthode par
rapport à une autre dépend fortement de la connaissance à priori du système, ainsi que du
type d’information retenue sur le système. Une classification des ces méthodes est adoptée
par Varanon Uraikul 2007, les approches à base d’un historique de données (data-driven ap-
proach), les approches analytiques (analytical approach), les approches à base de connaissances
(knowledge-based approach).
14

Différentes méthodes de diagnostic
1.4.1 Les approches analytiques
Les modèles analytiques sont une représentation mathématique des lois d’évolution des va-
riables du système. En fait, le système est décrit par un ensemble d’équations issues des lois
de la physique, de la chimie, etc, selon la nature du système étudié. Les approches analytiques
concernent la construction d’un modèle qui représente le bon fonctionnement du système. Celui-
ci est utilisé comme une référence afin d’être comparé au comportement observé sur le système,
dont leur variations estimées à partir du modèle sont comparées à celles provenant du sys-
tème réel. Tout écart entre les deux informations est alors considéré comme synonyme d’une
défaillance. Parmi les approches analytiques, on trouve les méthodes par estimation de para-
mètres, par estimation d’état, ou par espace de parité.
La méthode d’estimation paramétrique
Partant de l’idée qu’un défaut se reflète dans les paramètres physiques du système, cette
méthode suppose l’existence d’un modèle paramétrique qui décrit le comportement du système,
et que les valeurs de ces paramètres en fonctionnement nominal sont connues. Le principe
de base est d’estimer en continu ces paramètres en utilisant les mesures (entrées/sorties) du
système. La différence entre cette estimation et la référence est ainsi considérée comme résidu.
La méthode d’espace de parité
La méthode de l’espace de parité est une des premières méthodes employées dans le do-
maine du diagnostic de défauts (Chow et Wilsky 1984, Gertler et Singer, 1990). Le principe
de cette approche est de vérifier la cohérence (la parité) entre les relations mathématiques du
système et les mesures issue des capteurs et des entrées. L’idée de base est d’avoir la possibilité
d’exprimer une mesure (variable du système) en fonction des autres variables par une relation
mathématique connue. Deux types de relations analytiques se distingue (Toscano 2004) :
1. La redondance statique : qui est un ensemble de relations algébriques entre les mesures
fournies par les différents capteurs.
2. La redondance dynamique : qui est un ensemble d’équations différentielles ou récurrentes
entre les sorties et les entrées du système.
La méthode à base d’observateurs
L’observateur d’état est une des techniques les plus employées dans le domaine de l’auto-
matique, d’une part pour l’élaboration d’une loi de commande, et d’autre part pour la mise en
œuvre d’une stratégie de diagnostic. La redondance analytique est obtenue grâce aux états es-
timés à partir d’un modèle adéquat et d’un ensemble de mesures appropriées. Le principe de
15

Différentes méthodes de diagnostic
base du diagnostic par observateur consiste à estimer la sortie du système à partir des grandeurs
accessible à la mesure (entrées et sorties). Un observateur d’état, appelé aussi reconstructeur
d’état ou estimateur, est un système dynamique ayant comme entrées, les entrées et les sorties
du processus réel, et dont la sortie est une estimation de l’état du système. Le vecteur résidu est
ainsi construit comme l’écart entre la sortie estimée par l’observateur et la sortie mesurée sur le
processus physique. Ce résidu est un indicateur fiable de défauts.
1.4.2 Les approches à base de connaissances
Dans plusieurs cas dans la pratique, il devient très difficile d’avoir des connaissances com-
plètes d’un processus réel pour faire un modèle analytique, à cause de sa complexité structu-
relle ou de son comportement. Ainsi, il est bien démontré que l’opérateur humain peut fournir
une meilleure supervision en utilisant sa propre connaissance et son expérience pour assurer le
fonctionnement normal du système. Pour traiter les connaissance incomplètes des systèmes,
une autre alternative est de faire des abstractions selon le principe de raisonnement et les
connaissances de l’expert sur la structure et le comportement du processus. Les technologies
de l’intelligence artificielle comprenant les systèmes experts, la logique floue, et les réseaux de
neurones peuvent être adoptés dans cette situation. L’objectif de l’intelligence artificielle est de
tenter d’imiter les processus cognitifs humains. En effet, le diagnostic consiste en la relation
d’un problème inverse de type cause 7→ effet. Il s’agit de remonter des effets constatés, que nous
appellerons les symptômes observables, au défaut, c’est-à-dire à l’élément défaillant.
Les systèmes experts
Les experts humains sont capables d’effectuer un niveau élevé de raisonnement à cause de
leur grande expérience et de leurs connaissances dans leur domaine d’expertise. Un système
expert est un outil qui utilise la connaissance correspondante à un domaine spécifique afin de
reproduire les mécanismes cognitifs d’un expert humain. Plus précisément, un système expert
est un logiciel capable de répondre à des questions, en effectuant un raisonnement à partir de
faits et de règles connus. Il peut servir notamment comme un outil d’aide à la décision basé
sur un moteur d’inférence et sur une base de connaissances. Un système expert fait l’objet de la
transcription logicielle de la réflexion d’un expert dans un domaine donnée.
Les réseaux de neurones
Les réseaux de neurones artificiels ont comme objectif de reproduire les caractéristiques
les plus importantes du comportement biologique, à savoir l’apprentissage et la généralisation.
L’apprentissage des réseaux de neurones est une phase qui permet de déterminer ou de modi-
fier les paramètres du réseau, afin d’adopter un comportement désiré. Deux type d’algorithmes
16

Différentes méthodes de diagnostic
d’apprentissage se distinguent : supervisé et non supervisé. Dans l’apprentissage supervisé, un
superviseur (ou expert humain) fournit une valeur ou un vecteur (y) de sortie (appelé cible ou
sortie désirée) que le réseau de neurones doit associer au vecteur d’entrée (x). L’apprentissage
consiste dans ce cas à modifier les paramètres du réseau de neurones afin de minimiser l’erreur
entre la sortie cible et la sortie réelle du réseau de neurones. Dans l’apprentissage non supervisé,
les données ne contiennent pas d’informations sur la sortie désirée. Il n’y a pas de superviseur.
Il s’agit de déterminer les paramètres du réseau de neurones suivant un critère de convergence
prédéfini. La généralisation d’un réseaux de neurones est la capacité d’élargir ces connaissances
acquises après apprentissage à des données nouvellement rencontrées (phase de validation du
réseaux). Le principe de base d’une telle technique de surveillance à base de réseaux de neu-
rones est de trouver une relation entre les variables d’entrée et les variables de sortie. Selon les
variables d’entrées, le réseau de neurones donne une réponse caractérisée par les variables de
sortie. Les variables de sortie caractérisent l’état de fonctionnement du système (fonctionnement
normal ou pas).
1.4.3 Les approches à base de traitement de données (Data-Driven Approaches)
La détection et le diagnostic d’un événement anormal en temps opportun dans un procédé in-
dustriel joue un rôle très important pour minimiser les temps d’arrêt des installations, augmenter
la sécurité des opérateurs, et aussi pour assurer la disponibilité des unités de production. Dans
la plupart des procédures de modélisation, des incertitudes persistent entre le comportement
du système réel et l’évolution du modèle. Ces incertitudes sont dûes, d’un côté, au manque de
connaissances exhaustives sur le fonctionnement de l’équipement et, d’un autre côté, le modèle
ne prend en compte qu’une partie des paramètres qui influent sur l’évolution de la sortie. Par
ailleurs, dans certains cas pratique, ce modèle est quasiment impossible à obtenir. Comme les
processus industriels sont généralement assez complexes à modéliser, une modélisation avec
une approche théorique rigoureuse est souvent impraticable. Ceci, réduit considérablement le
champ d’application des ces techniques.
Les techniques de surveillance les plus efficaces dans la pratique sont celles qui sont basées
sur des modèles implicites, construits presque entièrement à partir d’un historique de données
de processus. Pour les méthodes à base de données, seulement la disponibilité d’une grande
quantité d’informations sur l’historique de fonctionnement des différents capteurs et actionneurs
du système est nécessaire. En effet, plusieurs techniques se distinguent afin de transformer cette
base de données en une connaissance sur le système. Ces techniques sont largement utilisées
dans l’industrie pour des raisons de surveillance et de diagnostic des procédés industriels en
raison de leur simplicité et leur efficacité dans le traitement d’une grande quantité d’information.
Le principe de base de modélisation de ces approches est résumé sur la figure 1.5, (Aldrich et
Auret 2013).
17

Différentes méthodes de diagnostic
FIGURE 1.5 – Principe de base du diagnostic des défaut à base de données.
On note que, X est une matrice de données qui regroupe l’historique de l’ensemble de don-
nées à surveiller. F est une matrice des caractéristiques extraites à partir de l’historique de
données X. F est une matrice d’information qui représente toute information pertinente sur
le fonctionnement processus. La matrice F est un modèle implicitement établi à partir de don-
nées historiques d’entrées et de sorties du système. X est la la matrice estimée. E est la matrice
résiduelle, considérée aussi comme une matrice d’évaluation des résidus, qui aide à la décision.
Parmi les approches nombreuse à base de données, on trouve l’Analyse en Composantes Prin-
cipales (ACP). La méthode d’analyse en composantes principales (ACP) peut faciliter le contrôle
de processus, en projetant les données dans un espace de dimension inférieure qui caractérise
l’état du processus. L’ACP est une technique de réduction de dimension qui produit une re-
présentation réduite de l’information, tout en préservant la structure de corrélation entre les
variables de processus ; elle est ainsi optimale en terme d’extraction de la variation pertinente
dans les données (Chiang et al., 2001). La méthode ACP a été proposée par Karl Pearson en
1901, et développé par Hotelling en 1947 (Venkatasubramanian et al., 2003), dans le but de
définir un ensemble de composantes principales constituées d’une combinaison linéaire des va-
riables originales. Les premières composantes principales prennent en compte la variance la plus
pertinente de l’ensemble de données, et les dernières composantes principales représentent la
variance résiduelle. Les composantes principales sont orthogonales, et conservent la corrélation
entre les variables du processus. Comme dans l’approche statistique T2 de Hotelling, les com-
posantes principales sont calculées en utilisant la décomposition en valeurs et vecteurs propres
(eigen-decomposition) de la matrice de covariance des données représentant les conditions nor-
males du fonctionnement de processus. Les composantes principales représentent les valeurs
des variables originales mesurées et transformées dans le nouvel espace de dimension réduite.
L’ACP cherche l’axe qui va maximiser la capture de variabilité ou variance (information) des
nuages de données. Les vecteurs obtenus à partir de la projection des mesures sur les compo-
sants principales peuvent être considérés comme une caractéristique extraite du fonctionnement
18

Les performances d’un système de diagnostic
du système. Le champ d’application de cette méthode est très varié allant de la réduction de
dimension, réduction et suppression de bruit, compression de données, détection des défauts
(Dunia et al., 1998, Qin 2012).
1.5 Les performances d’un système de diagnostic
Le développement d’une stratégie de surveillance et de diagnostic avec une méthode choisie
reste relativement une question importante. Le choix d’une méthode par rapport à une autre
dépend de la nature et des connaissances à priori du système étudié. Une comparaison entre ces
différentes méthodes est très difficile. Avant de définir une comparaison, il est plus utile de s’as-
surer que le système de diagnostic développé est le plus performant possible. Il convient alors de
définir certains critères de performance pour lesquels on peut évaluer n’importe quelle stratégie
de surveillance. Il y a un ensemble commun de critères d’évaluation pour toute approche de
surveillance et de diagnostic de défauts. Ces critères incluent les erreurs de détection, le temps
de détection, et les exigences de calcul.
Pour ce qui est du premier critère de l’erreur de détection, dans toute procédure de modéli-
sation, un modèle parfaitement précis et exact d’un système physique n’est jamais obtenu. Ceci
peut être le résultat de plusieurs causes comme par exemple la variabilité des paramètres du
système dans le temps, ou la méconnaissance de la nature des bruits. Par conséquent, en aucun
cas de défaut, il ya toujours un décalage entre le comportement observé sur le processus réel et
son comportement prédit par le modèle construit. Cette incertitude peut causer à la fois soit de
fausses alarmes ou des alarmes manquées. D’une manière générale, une réduction de la sensibi-
lité aux incertitudes de modélisation influt sur les résidus, i.e. il peut être associé une réduction
de la sensibilité à la détection de défauts (Chen and Patton 1999, Gertler 1998). En fait, la for-
mulation la plus significative de ce problème est d’augmenter l’insensibilité aux incertitudes de
modélisation afin de fournir plus de sensibilité aux défauts.
La sensisibilité à la détection est une tâche trés importante dans la surveillance et le diagnos-
tic de défauts. Généralement, l’apparition d’un défaut de grande amplitude sur le fonctionne-
ment d’un système est facile à détecter. Parce que leur effet sur la variation des résidus est plus
grand que celui des incertitudes de modélisation. Un seuil fixe est suffisant pour diagnostiquer
leur survenance sur les résidus. Pour le cas de défaut d’une faible amplitude, leur effet est faible
sur le changement des résidus, ainsi il peut être noyé dans les perturbations indésirables du sys-
tème. Sa présence ne signifie pas forcément une dégradation dans les performance du système,
mais elle peut indiquer qu’ il est préférable de remplacer l’élément défaillant par un autre avant
que la probabilité de sa gravité augmente.
Le deuxième critère est le temps de retard dans la détection de défauts. Il faut que les sys-
tèmes de surveillance répondent rapidement à la détection de défauts. Les techniques de diag-
19

Conclusion
nostic les plus rapides dans la prise de décision sont les plus souhaitables. Enfin, réduire les
exigences de stockage et de calcul joue également un rôle important dans l’évaluation des per-
formances d’une méthode de surveillance et de diagnostic, et spécialement dans le cas de la
surveillance des processus en temps réel. Il est donc souhaitable d’employer la procédure de
surveillance en temps réel parce qu’elle offre un équilibre raisonnable entre les exigences de
calcul par rapport aux obligations de stockage de données.
D’une manière générale, nous pouvons regrouper les différents critères de performance du
système de détection de la manière suivante : détectabilité, isolabilité, sensibilité, et robustesse.
– La détectabilité est l’aptitude du système de diagnostic à pouvoir déceler la présence d’une
défaillance sur le processus. Elle est fortement liée à la notion d’indicateurs de défauts (ré-
sidus). Le générateur de résidu doit, d’une certaine manière, être sensible à la défaillance
que l’on souhaite détecter.
– L’isolabilité est la capacité du système de diagnostic à remonter directement à l’origine du
défaut. Une défaillance engendre souvent une cascade d’alarmes et il peut être difficile de
remonter à l’organe défaillant. Le degré d’isolabilité des défaillances est lié à la structure
des résidus rendus disponibles et à la procédure de détection mise en œuvre.
– La sensibilité caractérise l’aptitude du système de diagnostic à détecter et localiser des
défauts d’une certaine amplitude correctement. Elle dépend non seulement de la structure
des résidus mais aussi du rapport entre le bruit de mesure et le défaut.
– La robustesse est l’insensibilité du système de diagnostic aux bruits, erreurs de modélisa-
tion, et aux autres incertitudes (sensibilité du résidu aux défauts et insensibilité vis-à-vis
des perturbations).
1.6 Conclusion
Dans ce chapitre, nous avons démontré la nécessité de la mise en œuvre d’une stratégie de
surveillance et le diagnostic dans une installation industrielle. Les principales fonctions d’une
telle technique de surveillance ont été présentées. Plusieurs types de défauts ont été présentés,
tels que les défauts capteurs, actionneurs et défauts de système. Dans cette thèse, seulement les
défauts capteurs et actionneurs sont étudiés.
Une synthèse non exhaustive des différentes techniques utilisées dans le domaine du diag-
20

Conclusion
nostic a été présentée. Parmi ces techniques nous nous sommes intéressés en particulier aux
méthodes à base de traitement de données, et plus précisément, la méthode statistique d’ana-
lyse en composantes principales. Un ensemble de critères d’évaluation de performances et leur
impact sur les principales fonctions de la surveillance et du diagnostic ont été discutés. Dans
le chapitre suivant, la méthode d’analyse en composantes principales (ACP) sera plus détaillée,
notamment par rapport à la modélisation des systèmes.
21

Chapitre 2Modélisation à base de l’analyse en
composantes principales (ACP)
Sommaire2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.2 Principe de l’analyse en composantes principales . . . . . . . . . . . 24
2.3 Identification du modèle ACP . . . . . . . . . . . . . . . . . . . . . . . 32
2.3.1 Pourcentage cumulé de la variance totale (PCV) . . . . . . . . . . . . . 33
2.3.2 Critère de validation croisée . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.3.3 Minimisation de la variance d’erreur de reconstruction (VER) . . . . . . 35
2.4 Analyse en Composantes Principales Adaptative (APCA) . . . . . 38
2.4.1 Les concepts de l’adaptation . . . . . . . . . . . . . . . . . . . . . . . . 39
2.4.2 L’ACP à base de fenêtre glissante (Moving Window PCA, MWPCA) . . 42
2.4.3 L’ACP Récursive (RPCA) . . . . . . . . . . . . . . . . . . . . . . . . . . 47
2.4.4 L’ACP à base de fenêtre glissante rapide (Fast Moving Window PCA) . 54
2.4.5 L’ACP Incrémentale (IPCA) . . . . . . . . . . . . . . . . . . . . . . . . 58
2.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
2.1 Introduction
L’Analyse en Composantes Principales (ACP) est également connue sous le nom de la dé-
composition de Karhunen-Loève (KL) ou la décomposition orthogonale. Elle joue un rôle fon-
damental dans l’analyse statistique. Elle a été introduite par Karl Pearson en 1901 pour décrire
et résumer l’information contenue dans un ensemble de données. Par la suite, dans les années
1930, elle a été de nouveau développée par Harold Hotelling comme une méthode d’analyse
22

Introduction
des relations existantes entre les variables. L’idée de base consiste à remplacer l’ensemble des
variables inter-corrélées par un nombre réduit de variables de synthèse qui retiennent l’essentiel
de l’information. Cette nouvelle représentation réduite, facilite l’interprétation du contenu de
ces variables. En fait, d’un point de vue géométrique, l’ACP peut être vue comme une méthode
de rotation des données afin de permettre à l’observateur de mieux comprendre les relations
entre les données.
L’ACP est une transformation algébrique, qui permet de mettre en évidence des compo-
santes, en tenant compte de la variance totale de toutes les variables à étudier. Cette trans-
formation effectue un changement de base qui permet de projeter des variables liées entre elles
(inter-corrélées) dans un nouvel espace orthonormé où un autre nombre réduit, de variables dé-
corrélées, est obtenu. Ces nouvelles variables, appelées composantes principales, expliquent au
mieux la variabilité des données originales. En plus de sa principale utilisation comme un outil
de réduction de dimension, l’analyse en composantes principales est reconnue comme un outil
statistique performant et très puissant dans de divers domaines d’application, tel que, la recon-
naissance des formes (pattern recognition), la visualisation, la détection des valeurs aberrantes,
la classification, et notamment la surveillance et le diagnostic des processus industriels.
Depuis un certain nombre d’années, de nombreux travaux ont proposé d’utiliser l’ACP comme
un outil de modélisation de processus à partir duquel, un modèle ACP peut être obtenu (Kresta
et al., 1991, MacGregor et Kourti 1995, Jolliffe 2002). Bien que généralement classée parmi
les méthodes sans modèle, comme cela a été exposé dans le chapitre précédent, l’ACP élabore
implicitement un modèle à partir de données expérimentales prélevées sur le système lorsque
il est considéré en bon fonctionnement. En effet, les directions ou les composantes principales,
fournissent les coefficients et la structure du modèle ACP. Ainsi, ce dernier permet d’estimer les
variables ou les paramètres du processus à surveiller. L’objectif principal de cette méthode est
de décomposer les données prélevées sur le fonctionnement d’un processus en deux parties :
la première, décrivant la dynamique du processus, en tenant compte d’une perte d’information
minimale, la seconde représentant les bruits. Mathématiquement, l’ACP est une transformation
algébrique. Elle transforme une matrice de données en un nouvel ensemble de variables in-
dépendantes appelées composantes principales, en effectuant une transformation linéaire. Les
vecteurs de transformation peuvent être obtenus par décomposition en valeurs et en vecteurs
propres de la matrice de covariance, ou la matrice de corrélation de données. Une étape cru-
ciale dans la méthode ACP, concerne la sélection du nombre de composantes principales qui
doivent conserver l’information des données originales. Il existe dans la littérature, différentes
méthodes pour déterminer ce nombre de composantes principales, qui permet de définir la di-
mension optimale du modèle ACP (Jackson, 1991, Valle et al., 1999, Jolliffe, 2002, Dunia et al.
1998).
Le modèle ACP est exploité dans la détection des disfonctionnements, en comparant le com-
23

Principe de l’analyse en composantes principales
portement observé sur le processus et celui estimé par le modèle. L’ACP est largement utilisée à
la fois pour la détection de défauts de capteurs (Dunia et al., 1996, Lee et al., 2004), comme pour
la détection de changements de modes de fonctionnement (Kano et al., 2001), ainsi que pour
la surveillance et le diagnostic des processus continus (McAuley and MacGregor, 1991). Une
limitation importante liée à la méthode ACP dans sa version classique, est l’invariance du mo-
dèle (statique), alors que la nature de la plupart des processus industriels est dynamique. Leurs
comportements et/ou leurs caractéristiques statistiques changent dans le temps (time-varying
behavior), et ne sont pas préalablement connus ou entièrement compris, en raison des incerti-
tudes sur le système, et des changements dans les conditions de fonctionnement (exemple, dans
le vol d’un avion, la masse diminuera lentement en relation avec la consommation de carbu-
rant, d’où la nécessité d’une loi de commande qui s’adapte avec ces conditions changeantes ),
. . . etc. Par conséquent, le suivi et la surveillance en temps réel de ce type de processus avec
un modèle ACP statique, construit à partir d’un historique de données prélevées sur seulement
une partie de la plage globale du fonctionnement normal du processus, ne seront pas fiables.
Ils engendreraient des interprétations erronées de l’état actuel du système, et augmenteraient le
taux de fausses alarmes, ou de non détection de défauts. Ce problème peut être résolu à travers
une mise à jour continue de tous les paramètres qui définissent la dynamique du système. Il
apparait ainsi nécessaire de rechercher pour les cas qui nous intéressent, une version adaptative
du modèle ACP, qui tienne compte de cette dynamique. Cette dernière se traduit généralement
pour les variables du processus, par : un changement de la moyenne, de la variance, et de la
structure de corrélation entre les variables, qui peut induire un changement du nombre de com-
posantes principales. L’utilisation d’un algorithme récursif pour la mise à jour du modèle ACP
statique est une alternative dans les approches dynamiques de modélisation. Plusieurs travaux
lui sont consacrés dans la littérature et qui permettent l’utilisation de l’analyse en composantes
principales récursive pour la surveillance et le diagnostic des processus dynamiques (Li et al.
2000, Wang et al. 2005, Choi et al. 2006, Kruger et al. 2009).
Dans ce chapitre, nous présentons d’abord le principe de base de la modélisation par l’ana-
lyse en composantes principales. Les différentes étapes à suivre pour obtenir un modèle ACP
sont explicitées. Le choix de la dimension optimale du modèle ACP dépend du nombre de com-
posantes principales à retenir dans ce modèle. Pour cela, plusieurs critères de sélection sont
proposés. Ensuite, la version dynamique de la méthode ACP est abordée. Enfin, les différentes
approches de l’ACP adaptative qui contournent les limitations de l’ACP statique sont discutées.
2.2 Principe de l’analyse en composantes principales
L’Analyse en Composantes Principales a comme objectif général d’étudier les structures de
liaisons linéaires entre les variables qui définissent le système étudié. Dans le cas où ces va-
24

Principe de l’analyse en composantes principales
riables sont fortement corrélées, cela signifie que les informations contenues dans ces dernières
sont fortement redondantes. De ce fait, l’ACP consiste à déterminer un nombre réduit de nou-
velles variables indépendantes, appelées composantes principales (PCs), et représentant la va-
riation la plus pertinente des données initiales. Ces nouvelles variables réduites, fournissent les
coefficients et la structure du modèle ACP. En effet, l’identification de ce modèle débute par la
construction d’une matrice contenant un ensemble de données d’entrées/sorties, recueillies sur
le système en fonctionnement normal (données saines). La matrice de données X est construite
comme suit :
X = [x(1), x(2), ..., x(N)]T ∈ ℜN×m (2.1)
où N représente le nombre d’observations, et m représente le nombre de variables mesurées. A
chaque instant k, une observation sur le fonctionnement du système est collectée. Ainsi, un vec-
teur de mesures x(k) = [x1(k), x2(k), ..., xm(k)]T ∈ ℜm est obtenu, où xj(k) avec j = 1, ...,m
représente la mesure de la jeme variable à l’instant k. Ce vecteur de mesures est considéré centré,
de moyenne nulle Ex(k) = 0, et de matrice de covariance Σ = ExxT ∈ ℜm×m.
Généralement, toutes les composantes xj du vecteur de mesures x sont exprimées par des
unités et des échelles différentes. Afin de rendre les résultats indépendants des unités de me-
sures, et que les variables les plus dispersées ne seront pas les plus avantagées dans la construc-
tion du modèle ACP, on réduit ces dernières par rapport à leur variance respective (avoir des
variables avec une variance unitaire, varx = E(x − Ex)2 = 1).
Le but de l’ACP est de trouver une meilleure base de représentation des données, obtenue
par combinaison linéaire de la base originale. C’est pourquoi, la recherche d’un sous-espace de
dimension l ≤ m qui permet d’avoir une représentation réduite et optimale de données initiales,
est nécessaire. En fait, l’ACP projette le vecteur de mesure x ∈ ℜm vers un sous-espace réduit
orthonormé ℜl, où un nouveau vecteur caractéristique t ∈ ℜl est obtenu.
Le vecteur caractéristique t, appelé vecteur des composantes principales, est associé à chaque
vecteur de données x à travers une transformation linéaire définie par P ∈ Rm,l. On a donc,
t(k) = P T x(k), où P ∈ ℜm×l est une matrice de changement de base ou de transformation
qui vérifie la condition d’orthogonalité P TP = Il, avec P = p1, ..., pl et pi ∈ ℜm. Les pi sont
les directions (axes) de la nouvelle base orthonormée du sous-espace ℜl. Ces directions sont
orthogonales 2 à 2, c’est-à-dire, pTj pi = 0 ∀ i = j. Les composantes tj(k) avec j = 1, 2, ..., l du
vecteur t(k) sont les coordonnées des projections des éléments du vecteur de données x(k) sur
les axes du sous-espace. Pour obtenir ces coordonnées, on écrit que chaque composante prin-
cipale est une combinaison linéaire des variables initiales. La première composante est donnée
comme suit :
25

Principe de l’analyse en composantes principales
t1(k) = p11x1(k) + p12x2(k) + ...+ p1mxm(k) =m∑
j=1
p1jxj(k) (2.2)
L’optimisation de la représentation est basée sur la matrice de projection P . On cherche
à construire la matrice P de sorte que la représentation réduite de données minimise l’erreur
d’estimation du vecteur x. Il convient de noter que la reconstruction, ou l’estimation du vecteur
de données x est représentée dans sa variation maximale retenue (modélisée) à partir de l’espace
réduit. L’approximation de ce vecteur est défini comme suit : x(k) = P t(k), ou x(k) = PP T x(k).
Et donc, le vecteur P est construit de sorte que l’erreur quadratique ∥x−x∥2 entre le vrai x et son
estimation x soit minimale, et ceci pour tous les points x(k) avec k = 1, ..., N. Ce problème
d’optimisation s’exprime par :
Popt = arg min Je(P )
P(2.3)
où Je(P ) représente le critère à minimiser, de l’erreur d’estimation de l’ACP. Sous la contrainte
d’orthogonalité de la matrice de projection P , ce critère aura la forme :
Je(P ) =1N
N∑k=1
∥x(k) − x(k)∥2 =1N
N∑k=1
∥x(k) − PP T x(k)∥2
=1N
N∑k=1
(x(k) − PP T x(k)
)T (x(k) − PP T x(k)
)=
1N
N∑k=1
(xT (k)x(k) − 2xTPP T x(k) + xTPP TPP T x(k)
)=
1N
N∑k=1
xT (k)x(k) − 1N
N∑k=1
xT (k)PP T x(k) =1N
N∑k=1
xT (k)x(k) − 1N
N∑k=1
tT (k)t(k)
= trace
(1N
N∑k=1
x(k)xT (k) − 1N
N∑k=1
t(k)tT (k)
)
= trace
(1N
N∑k=1
x(k)xT (k) − 1N
N∑k=1
P T x(k)xT (k)P
)Je(P ) = trace (Σ) − trace
(P T ΣP
).
Notons que la trace d’une matrice carrée est définie par la somme de ses éléments diagonaux. Du
fait que la matrice de covariance Σ est indépendante de la matrice des paramètres P , minimiser
Je revient à maximiser par rapport à P , la variance du second terme de son expression. Par
conséquent, le critère d’optimisation Je devient comme suit :
26

Principe de l’analyse en composantes principales
Je(P ) = trace (Σ) − trace(P T ΣP
)= trace (Σ) − Jv(P ).
De ce fait, le problème d’optimisation est reformulé ainsi :
Popt = arg min Je(P ) = arg max Jv(P )
P P(2.4)
Le problème Je est équivalent à la maximisation de la variance de la représentation réduite
t, dont il revient à trouver des composantes principales restituant le maximum de la variance de
données initiales sur les axes du sous-espace orthonormé ℜl. Notons que Jv(P ) est donné par la
formulation suivante :
Jv(P ) =1N
N∑k=1
tT (k)t(k) =1N
N∑k=1
l∑j=1
t2j (2.5)
=l∑
j=1
Et2j =l∑
j=1
vartj (2.6)
Sous l’hypothèse de nullité de la moyenne du vecteur de données x, la valeur moyenne
de la projection t est également nulle, Et = P TEx = 0. En conséquence, la variance de
la projection, vart, s’identifie à sa valeur quadratique : vart = E(t− Et)2 = Et2. En
conséquence :
vartj = Et2j = E(pTj x)(xT pj) (2.7)
= pTj ExxT pj (2.8)
= pTj Σpj . (2.9)
D’après l’expression mathématique, on voit que la méthode ACP consiste à projeter les points
x(k) sur une droite, plutôt un plan, ou un sous-espace engendré par plusieurs directions pj choi-
sies de façon à maximiser le critère Jv. Pour éviter d’avoir la même information dans plusieurs
composantes tj , ces directions doivent être unitaires ∥p∥2 = pT p = 1, et orthogonales 2 à 2,
c’est-à-dire, pTj pi = 0 ∀ i = j. Intuitivement, l’ACP vise à trouver les directions de plus grande
dispersion possible des données x(k) dans le sous-espace choisi. L’idée étant que les directions
de plus grande dispersion soient les directions les plus intéressantes. Si le premier axe restitue
le maximum possible de la variance des projections, le deuxième axe apporte le plus possible de
27

Principe de l’analyse en composantes principales
variance non prise en compte par le premier, et ainsi de suite.
La problématique se présente donc comme suit : choisir le premier axe p1 du sous-espace ℜl
de façon à maximiser leur variance de projection t1. Juste après, chercher le 2ime axe qui est le
vecteur unitaire p2 tel que la variance de t2 = xp2 soit maximale et que p2 soit orthogonal à p1.
Et ainsi de suite jusqu’à le jime axe qui est le vecteur unitaire pj tel que la variance de tj = xpj
soit maximale et que pj soit orthogonal aux j − 1 premiers axes. Il s’agit donc d’un problème
classique d’optimisation sous contrainte que l’on peut solutionner par la méthode de Lagrange.
Le vecteur unitaire p1 est la solution du problème d’optimisation sous contrainte suivant : max pT1 Σp1
pT1 p1 = 1
(2.10)
et donc le Lagrangien s’écrit sous la forme suivante :
L(p1, λ1) = Jv(p1) − λ1(pT1 p1 − 1) = pT
1 Σp1 − λ1(pT1 p1 − 1) (2.11)
où λ1 ∈ ℜ désigne le multiplicateur de Lagrange. En tenant compte de la symétrie de la matrice
Σ, on dérive le Lagrangien par rapport au vecteur p1 ainsi que par rapport au multiplicateur de
Lagrange (λ1) et on pose les dérivées partielles égales à zéro. Le vecteur p1 minimisant le critère
d’optimisation (2.10) est alors solution du système d’équations suivant : ∂L(p1, λ1)/∂p1 = Σp1 − λ1p1 = 0
∂L(p1, λ1)/∂λ1 = pT1 p1 − 1 = 0
(2.12)
La résolution de ce système d’équations s’identifie à la résolution d’un problème d’estimation
de valeur propre et de vecteur propre de la matrice de covariance sous contrainte de normalisa-
tion du vecteur propre. Un tel système d’équations admet des solutions réelles de la variables λ
obtenues par résolution de l’équation caractéristique suivante :
DetΣ − λIm = 0. (2.13)
où Det. représente le déterminant d’une matrice carrée. Im est la matrice identité d’ordre m.
Les solutions de l’équation précédente représentent les valeurs propres de la matrice Σ. A ces
valeurs propres λ sont associés m vecteurs caractéristiques p appelés vecteurs propres vérifiant
DetΣ − λImp = 0. Notons par λ1, ..., λm les m valeurs propres de la matrice de covariance
Σ et par p1 ∈ ℜm, ..., pm ∈ ℜm les m vecteurs propres qui leurs sont associés, et qui vérifient
ainsi la relation Σpi = piλi, avec i = 1, ...,m. Ceci permet de dire que (λ1, p1) représente la paire
(valeur propre, vecteur propre) de la matrice de covariance Σ. Le premier axe p1 pour lequel la
28

Principe de l’analyse en composantes principales
variance des projections est maximal, est le vecteur propre le plus riche en information, et est
associé à la plus grande valeur propre de la matrice Σ.
Lemme : Le sous-espace de dimension l minimisant l’erreur quadratique d’estimation des
données x contient nécessairement le sous-espace de dimension l − 1.
Maintenant pour le cas des m axes suivants, on cherche cette fois un vecteur unitaire p2,
orthogonal au précédent p1 (sachant que p1 est connu), et qui maximise la variance t2. Le vecteur
unitaire p2 est la solution du problème d’optimisation sous contrainte, suivant :
max pT
2 Σp2
pT2 p2 = 1
pT2 p1 = 0
(2.14)
et donc, le Lagrangien est :
L(p2, λ2) = Jv(p2) − λ2(pT2 p2 − 1) − µ(pT
2 p1) = pT2 Σp2 − λ2(pT
2 p2 − 1) − µ(pT2 p1) (2.15)
où (λ2 et µ) ∈ ℜ désignent les multiplicateurs de Lagrange. Dérivant le Lagrangien par rapport
à chacune des composantes du vecteur p2, λ2 et par rapport à µ, puis simplifiant, on trouve :
∂L(p2, λ2, µ2)/∂p1 = Σp2 − λ2p2 = 0
∂L(p2, λ2, µ)/∂λ2 = pT2 p2 − 1 = 0
∂L(p2, λ2, µ)/∂µ = pT1 p2 = 0
(2.16)
Par analogie avec le cas précédent, la direction orthogonale à p1, qui en même temps maximise
la variance projetée, correspond au vecteur propre p2 associé à la seconde plus grande valeur
propre λ2 de la matrice variances-covariances Σ. Sa variance λ2 est moins importante que celle
qui correspond à la première direction, et ainsi de suite. Ces résultats se généralisent et nous
pouvons écrire sous une forme matricielle, ce qui suit :
ΣP = PΛ (2.17)
où P = [p1, ..., pm] ∈ ℜm×m représente la matrice de projection de données, ses colonnes sont
orthogonales (P TP = PP T = Im) et elles correspondent aux vecteurs propres de Σ. La matrice
Λ = diag(λ1, ..., λm) représente la matrice diagonale constituée en éléments diagonaux des
valeurs propres de Σ, arrangées dans l’ordre décroissant : λ1 ≥ ... ≥ λm. En conséquence, la
forme matricielle (2.17) admet la forme équivalente suivante :
29

Principe de l’analyse en composantes principales
P T ΣP = Λ (2.18)
et qui s’écrit sous forme développée :
pTi Σpj =
λi si j = i
0 si j = i(2.19)
En revenant au critère de maximisation Jv, le vecteur de données x(k) peut se transformer sans
aucune perte d’informations en un vecteur de composantes principales et t(k) = P T x(k), où la
variance de ces dernières est maximale. Par comparaison des relations (2.9) et (2.19), il résulte
Etitj = E(pTi x)(xT pj) = pT
i Σpj =
varti = λi si j = i
0 si j = i(2.20)
Cette expression mathématique montre que les valeurs propres de la matrice de covariance Σ
donnent directement les variances des projections ti sur chacune des directions pi(i = 1, ...,m)
que nous cherchons. Ces nouvelles composantes ti obtenues sont statistiquement non corrélées
ou indépendantes. En conclusion, la direction suivant laquelle la variance de la projection du
vecteur de données x est maximale, est représentée par le vecteur propre pi correspondant à la
valeur propre maximale λi.
La représentation réduite des données est d’un intérêt indispensable de la méthode ACP. Son
objectif est de choisir un sous-espace de dimension réduite qui fournisse le maximum d’informa-
tion sur les données initiales. Tandis que les vecteurs propres donnent les directions de variance
maximale, que nous appelons les axes factoriels du sous-espace choisi. Sur ces directions se pro-
jettent les données, obtenant ce que nous appelons les composantes principales tj , sachant que
leur variance est égale à leur valeur propre. La direction de l’espace matérialisée par le vecteur
propre p1 associée à la plus grande valeur propre λ1 est la plus riche en information. Dans le cas
contraire, la direction du vecteur propre pm associée à la plus petite valeur propre λm est celle
qui capture le minimum d’information.
L’analyse en composantes principales consiste donc à passer des m variables d’origine à m
nouvelles variables combinaisons linéaires de celles d’origine, chacune avec une importance
mesurée par sa variance, égale à sa valeur propre. En effet, la réduction de la dimension est
réalisée à travers les (l) premières composantes principales ayant les plus grandes variances. Par
conséquent, le sous-espace vectoriel réduit ℜl (avec l ≤ m) portant la variance maximale, est
engendré par les (l) premiers vecteurs propres associés aux l plus grandes valeurs propres de la
matrice de variance-covariance Σ. Et donc, l’estimation ou la reconstruction x d’un vecteur de
30

Principe de l’analyse en composantes principales
données x est alors décrite par l’expression réduite :
x(k) =l∑
j=1
pjtj(k) =l∑
j=1
pj
(pT
j x(k))
(2.21)
x(k) = P P T x(k) = Cx(k) (2.22)
où la matrice optimale de transformation ou de représentation exprimée dans l’équation (2.4)
est définie comme suit :
P = [p1, ..., pl] ∈ ℜm×l (2.23)
La matrice P constitue l’espace principal de données. Le vecteur des l premières composantes
principale est représenté par t(k) = P T x(k) ∈ ℜl, et que la matrice C = P P T ∈ ℜm×m caracté-
rise le modèle ACP.
La perte d’informations induite par la réduction de dimension de la représentation de don-
nées est mesurée par la différence entre la vraie mesure x(k) et son estimation x(k). Elle est
aussi évaluée par les (m− l) composantes principales tj avec j = l + 1, ...,m associées aux plus
faibles valeurs propres λl+1, ..., λm.
e(k) = x(k) − x(k) =m∑
i=l+1
piti(k) =m∑
i=l+1
pi
(pT
i x(k))
(2.24)
e(k) = x(k) = P P T x(k) = Cx(k) (2.25)
où la matrice P = [pl+1, ..., pm] ∈ ℜm×m−l constitue l’espace résiduel. La matrice C = P P T =
Im − C ∈ ℜm×m décrit le modèle résiduel.
L’interprétation du principe de modélisation par l’ACP, représente un partitionnement de
l’espace ℜm des mesures x(k) en un sous-espace principal Sp et un sous-espace résiduel Sr. Par
conséquent, le vecteur de mesures x(k) est décomposé comme suit :
x(k) = x(k) + e(k) = x(k) + x(k) (2.26)
L’analyse en composantes principales élabore implicitement un modèle à partir d’un histo-
rique de données prélevées sur le système en bon fonctionnement. Elle peut donc être considérée
comme une approche de modélisation. Une transformation linéaire des variables est effectuée
sur de nouveaux axes contenant le maximum possible de leur variabilité. Ces nouvelles direc-
tions sont les entités mathématiques qui peuvent représenter, après un choix intelligent d’un
31

Identification du modèle ACP
ensemble représentatif, les données x. Tandis que les directions de plus grandes dispersions sont
les directions les plus intéressantes, et que la variabilité associée avec ces directions correspond
à de l’information. La quantité de variance contenue dans chaque composante principale est
proportionnelle à sa valeur propre. En fait, l’identification du modèle ACP, consiste à estimer
ses paramètres par une décomposition en valeurs et vecteurs propres de la matrice de variance-
covariance (corrélation) Σ et à déterminer le nombre de composantes principales (l) à retenir.
L’idée étant que les l premières directions choisies de plus grandes valeurs propres sont les
directions les plus intéressantes qui caractérisent le modèle ACP. Les autres (m− l) directions
qui correspondent aux valeurs propres plus faibles sont normalement interprétées comme des
bruits de mesure, bien que généralement, elles sont très utiles pour par exemple, le diagnostic
de défauts.
Dans le cas où les valeurs propres de la matrice Σ sont égales à zéro, cela signifie que les
relations entre les différentes composantes xi sont fortement linéairement corrélées. Et comme
en pratique, la présence de bruit de mesure dans les données est inévitable, des valeurs propres
égales à zéro sont rarement rencontrées. Ainsi, des petites valeurs propres de la matrice Σ qui
définissent le sous-espace résiduel P , indiquent l’existence de relations quasi-linéaires entre les
variables. Li et Qin (2001) ont montré que l’ACP fournit un modèle sans biais, uniquement dans
le cas très particulier où les variables sont entachées d’erreurs de mesure de même variance.
Donc, il est nécessaire de déterminer le nombre de composantes principales (l), représentant le
nombre de vecteurs propres correspondant aux valeurs propres dominantes, définissant le sous-
espace principale P . Ici, on entrevoit le rôle important de ce paramètre dans la détermination des
relations de redondances entre les variables, ainsi que dans le choix de la dimension optimale du
modèle ACP. Les principales méthodes d’identification du nombre de composantes principales
vont être présentées dans la partie suivante.
2.3 Identification du modèle ACP
L’objectif majeur de la méthode ACP est de produire une représentation réduite et opti-
male de l’information. L’idée étant de remplacer m variable de la matrice de données X par un
autre nombre réduit l de nouvelles variables appelées composantes principales (PCs). En fait, le
nombre de composantes principales dépend de la corrélation existante entre les variables. La dé-
termination du nombre de composantes principales l à conserver est donc une étape primordiale
dans la méthode ACP. Elle permet de définir la dimension réduite du nouvel sous-espace obtenu
qui porte de l’information. Un choix optimal de ce nombre, permet au modèle de capturer et de
retenir le maximum possible de variation de données en laissant les changements non corrélés
de ces dernières et les bruits dans la partie résiduelle.
Plusieurs méthodes ont été proposées permettant le choix du nombre de composantes prin-
32

Identification du modèle ACP
cipales à retenir dans le sous-espace réduit. La plupart de ces méthodes sont heuristiques et
donnent un nombre de composantes subjectif qui privilégient l’approximation de données x(k).
La difficulté inhérente à l’utilisation de ces méthodes, est l’absence d’un minimum du critère uti-
lisé afin de déterminer le nombre de composantes principales. Ceci rend la solution non unique
et ambigüe. Dans ce cadre on peut citer par exemple la méthode du pourcentage cumulé de la
variance totale (CPV) (Malinowski, 1991), ainsi que la méthode de validation croisée (PRESS)
(Wold, 1978).
Dans le cas d’application de la méthode ACP au diagnostic, on ne cherche pas seulement à
déterminer une meilleure approximation des données, mais on cherche aussi un modèle qui as-
sure la détection et la localisation de défauts. Cependant le nombre de composantes principales
a un impact significatif direct sur la richesse du modèle ACP, et indirect sur les procédures de
détection et localisation de défauts. En effet, dans le cas où peu de composantes sont retenues
dans le sous-espace principal, certaines d’entre elles qui portent de l’information seront proje-
tées dans le sous-espace résiduel. Le modèle ACP sera, alors pauvre en information. Il ne sera
pas précis, et la variance des données ne sera pas maximale. Ce qui produit ainsi des erreurs de
modélisation entachant les résidus et provoquant des fausses alarmes. Dans le cas contraire, si
on utilise beaucoup de composantes, on risque de conserver celles correspondantes aux valeurs
propres plus faibles, porteuses de bruit. Et donc, plus de composantes retenues dans le sous-
espace principal, réduit la dimension de l’espace résiduel, et ce qui peut évidemment causer la
non détection de certains défauts. Dans ce contexte, et d’après la littérature, on distingue deux
approches. Dans la première approche, développée par Tamura et Tsujita (2007), pour chaque
défaut, on cherche le nombre de composantes principales afin d’obtenir le modèle ACP le plus
sensible à ce défaut. Cependant cette méthode nécessite une connaissance à priori sur les dé-
fauts. Dans la seconde approche, Qin et Dunia (1998) ont proposé une technique basée sur la
minimisation de la variance de l’erreur de reconstruction (VER). Ce critère permet de prendre
en compte la notion de redondance entre les variables. L’erreur de reconstruction correspond
à la différence entre une variable et son estimation obtenue en utilisant l’ensemble des autres
variables et du modèle ACP. Ce critère permet de déterminer à la fois le nombre de composantes
principales l et les variables possédant une projection significative dans l’espace résiduel. Plu-
sieurs études comparatives ont été menées entre ces différentes méthodes et ont conclut que le
critère (VER) est le plus pertinent (Valle, Li, and Qin 1999).
2.3.1 Pourcentage cumulé de la variance totale (PCV)
Sur la base du principe que chaque composante principale représente une portion de la
variance totale des données initiales, et sachant que la variance de chaque composante est me-
surée directement par sa valeur propre respective λj de la matrice de corrélation Σ, alors l’idée
consiste à cumuler les portions de cette variance jusqu’à ce qu’elles atteignent ou dépassent un
33

Identification du modèle ACP
pourcentage de variance maximale, prédéfini ou préalablement choisi. Généralement, on essaie
de retenir un nombre de composantes principales ayant un pourcentage cumulée de variance
maximale compris entre 90% et 95% de la variance totale des données. Le pourcentage de la
variance cumulée est écrit comme suit :
PCV (l) = 100
(∑lj=1 λj∑mj=1 λj
)% (2.27)
La variance du bruit est inconnue à priori, alors que la capacité de cette approche à fournir le
nombre optimal de composantes principales dépend fortement du rapport signal sur bruit. La
règle de décision basée sur un tel critère reste donc imparfaite, car il s’agit d’une réalisation d’un
compromis entre une variance maximale et un nombre minimal de composantes retenues.
2.3.2 Critère de validation croisée
L’idée de base de cette méthode est d’avoir une estimation sur les mesures xi(k) d’un jeu de
données de validation à partir d’un modèle qui a été calculé via un jeu de données d’identifi-
cation. La comparaison entre les valeurs mesurées et leurs estimations par un modèle obtenu
à partir d’un jeu d’identification différent, est évaluée. D’après Wold (1978), Eastment et Krza-
nowski (1982), le nombre des composantes principales retenues est optimal si la moyenne de
l’estimation globale des mesures xi(k) n’est plus significativement améliorée par l’ajout d’une
autre composante supplémentaire. La procédure de validation croisée est basée sur un critère
appelé PRESS et qui consiste en la minimisation de la somme des carrés des erreurs d’estimation.
PRESS (l) =1Nm
N∑k=1
m∑i=1
(x
(l)i (k) − xi(k)
)2(2.28)
où m étant le nombre de variables et N la taille du jeu de validation. Ainsi, x(l)i représente l’es-
timation de xi en utilisant un modèle ACP constitué de l composantes principales (PCs).
L’algorithme simplifié de cette méthode, permettant le calcul du nombre l de composantes
principales (PCs) se présente comme suit :
1. Diviser les données en un jeu d’identification et un jeu de validation.
2. Réaliser une ACP avec l composantes sur le jeu d’identification, avec l = 1, ..., m, et
calculer les critères correspondant sur le jeu de validation PRESS(1), ..., PRESS(m).
3. La l ème composante pour laquelle le minimum de PRESS apparaît sera le nombre de
composantes principales retenu.
Malgré la célébrité de la méthode de validation croisée, cette dernière n’est plus considérée
avantageuse par rapport au reste des critères heuristiques. Besse et Ferré (1993) ont montré
34

Identification du modèle ACP
théoriquement que, malgré un coût de calcul important, l’usage de la validation croisée en ACP
n’apporte pas une règle de décision plus objective que les techniques usuelles heuristiques.
2.3.3 Minimisation de la variance d’erreur de reconstruction (VER)
D’après les travaux présentés par Dunia et Qin (1998b,c,a), ainsi que Qin et Dunia (2000),
un nouveau critère de sélection du nombre de composantes principales basé sur la minimisa-
tion de la variance de l’erreur de reconstruction, appelée aussi variance non reconstruite (VNR),
a été proposé. L’idée de base de cette technique repose particulièrement sur l’astuce de la re-
construction. Le principe consiste à estimer une des variables du vecteur de données x(k) à un
instant donné, notée xi(k), en utilisant toutes les autres variables xj(k) au même instant sauf
la ieme, i.e. avec j = i. Pour le cas de toute variable estimée (xi = zi), plutôt reconstruite, il
existe toujours une partie ou une portion de sa variation qui ne peut pas être reconstruite à
partir seulement des autres variables xj(k). La portion non-capturée de chaque mesure à l’aide
du modèle ACP et les autres variables, est la variation non reconstruite, appelée aussi l’erreur
de reconstruction. En fait, la qualité de la reconstruction est liée à la capacité du modèle ACP à
modéliser les relations de redondance entre les variables.
L’estimation de l’information délivrée par le capteur i en utilisant toutes les autres mesures
des différents capteurs est donnée ainsi :
zi(k) =
[cT−i 0 cT+i
]1 − cii
x(k) (cii = 1) (2.29)
où les indices +i et −i désignent les vecteurs formés par les (i − 1) premiers et les (m − i)
derniers éléments du vecteur originel, respectivement. Dans ce cas, la reconstruction d’une telle
variable aboutit à un vecteur d’observation reconstruit comme suit :
xi = [x1, .., zi, .., xm] ∈ ℜm (2.30)
L’expression de la reconstruction xi du vecteur de données x sur une direction ξi ∈ ℜm est
donnée par Dunia et al. (2000) :
xi(k) =(Im − ξi(ξT
i Cξi)−1ξT
i C)
x(k) (2.31)
où ξi est la direction de la variable reconstruite. Ainsi, ξi = [0 0 0 1 0 0 0] est la ieme colonne de la
matrice d’identité, où 1 indique la variable reconstruite à partir des autres variables (avec 0). En
outre, la reconstruction de la ime variable n’est possible que sous la condition ξTi Cξi = 0. Cela
implique que le vecteur Cξi ne soit pas nul (existence de variables projetées dans le sous-espace
résiduel).
35

Identification du modèle ACP
L’erreur de reconstruction correspond à la différence entre une variable et son estimation (re-
construction) obtenue en utilisant les autres variables et le modèle ACP. Autrement dit, l’erreur
de reconstruction n’est d’autre que la partie de variation de mesures qui ne peut être reconstruite
en utilisant les autres variables. L’erreur de reconstruction de la ieme variable est définie par :
ξTi (x − xi) =
(ξTi Cξi
)−1ξTi Cx (2.32)
Selon Qin et Dunia, le critère de la variance non reconstruite (VNR), ou la variance de l’erreur
de reconstruction présente un minimum dans le cas où une meilleure reconstruction de toutes
les variables est obtenue. Cependant, la précision de l’erreur de la reconstruction est fonction
du nombre de composantes principales retenu dans le modèle ACP. Ainsi donc, une meilleure
reconstruction ne sera réalisée que si le nombre de composantes principales est judicieusement
choisi. La variance de l’erreur de reconstruction de la ieme composante du vecteur de donnée x
est donnée par Qin et Dunia, (2000) :
ui = varξTi (x − xi)
= E
∥x − xi∥2
(2.33)
=ξTi CE
xxT
Cξi(
ξTi Cξi
)2 =ξTi CΣCξi(ξTi Cξi
)2 (2.34)
où Σ = E
xxT
est la matrice de corrélation estimée à partir des données. Intuitivement, ui
est la variance de l’erreur de reconstruction dans l’estimation de x en utilisant xi. Les propriétés
d’orthogonalité de la matrice P permettent de représenter Σ sous la forme suivante :
Σ = CΣC + (I − C)Σ(I − C) = Σ + Σ (2.35)
où Σ = E
xxT
et Σ = E
xxT
sont les parties modélisées et non modélisées de la matrice de
corrélation Σ, respectivement. Ainsi, la substitution de cette expression dans l’équation (2.34)
conduit à :
ui =ξTi CΣCξi(ξTi Cξi
)2 =ξTi CΣCξi(ξTi Cξi
)2 (2.36)
Cette équation représente ui avec les variations des données non modélisées. Bien que l’on
dispose de plusieurs variables devant être étudiées simultanément, on doit aussi identifier le
nombre de composantes principales qui minimise la variance de l’erreur de reconstruction glo-
bale (variance non reconstruite, VNR), i.e. pour tout l’ensemble des variables reconstruites :
36

Identification du modèle ACP
V NR(l) =m∑
i=1
ξTi CΣCξi(
ξTi Σξi
)(ξTi Cξi
)2 (l = 1, 2, ...,m) (2.37)
Afin d’éviter tout problème d’échelle des variances non reconstruites, les contributions des dif-
férentes variables au critère, sont pondérées par leurs variances respectives ξTi Σξi. Maintenant,
pour bien illustrer comment ce critère admet un minimum, correspondant à un modèle optimal
et offrant une meilleure reconstruction, on utilise l’identité suivante :
∥Cξi∥2 + ∥Cξi∥2 = ∥ξi∥2 = 1 (2.38)
A partir de l’expression (2.38), on peut écrire l’équation (2.36) sous la forme suivante :
ui(l) =ξTi CΣCξi(ξTi Cξi
)2 =ξTi CΣCξi
∥Cξi∥2(1 − ∥Cξi∥2
) (2.39)
=ξTi CΣCξi∥Cξi∥2
(1 +
∥Cξi∥2
1 − ∥Cξi∥2
)(2.40)
En notant que
ui(l) =ξTi CΣCξi∥Cξi∥2
(2.41)
ui(l) = ui(l)
(∥Cξi∥2
1 − ∥Cξi∥2
)(2.42)
L’équation (2.36) devient alors sous la forme suivante :
ui(l) = ui(l) + ui(l) (2.43)
où ui représente la variance non reconstruite dans le sous-espace des composantes principales, et
ui représente la variance non reconstruite dans le sous-espace résiduel. Donc d’après l’expression
mathématique (2.43), on peut conclure que la variance totale de l’erreur de reconstruction est
en relation avec deux types de variation non reconstruite. La première est la variance de l’erreur
de reconstruction dans le sous-espace principal, alors que la seconde est celle envisagée dans le
sous-espace résiduel.
Dunia et Qin (2000) ont montré que ui est monotone décroissante avec l. Intuitivement,
lorsque l augmente, les valeurs propres non nulles restantes dans Σ diminuent, ce qui impose
ui(l + 1) ≤ ui(l). Pour le cas de variance non reconstruite dans le sous-espace principal, il est
clair que si le nombre l se rapproche de m, le dénominateur ∥Cξi∥2 tend vers zéro, et donc :
lim ui(l) = ∞ lorsque l → m. On constate que la variance non reconstruite ui doit obliga-
37

Analyse en Composantes Principales Adaptative (APCA)
toirement avoir un minimum correspondant à un nombre de composantes principales optimal
l ∈ [1,m]. La valeur optimale de l pour la reconstruction de toutes les variables xi est donc défini
par le critère suivant :
J(l) = min
m∑i=1
ui(l) (2.44)
2.4 Analyse en Composantes Principales Adaptative (APCA)
Les procédés industriels modernes sont toujours équipés de systèmes de contrôle. Ils per-
mettent la régulation du processus autour de l’objectif désiré et d’assurer son bon fonctionne-
ment. Les données collectées sur leur fonctionnement sont stockées dans une base de données.
Leur traitement permet d’élaborer des méthodes de modélisation, et d’observation du compor-
tement du système. L’analyse en composantes principales s’avère être l’outil le plus utilisé pour
extraire les caractéristiques des données définissant la dynamique du processus. Ces paramètres
sont ensuite exploités pour la prédiction et la surveillance de leur variabilité. Cette tâche n’est
pas facile à réaliser, car les données historiques collectées sur le fonctionnement du système
sont très souvent pauvres en informations. Aussi, la construction d’un modèle ACP basé sur ces
données représente un défi majeur pour la méthode ACP.
L’historique des données doit pouvoir contenir tous les modes possibles de fonctionnement
du processus. Cela, inclut non seulement les états inhérents au fonctionnement interne du pro-
cessus, mais aussi les états liés aux conditions externes, notamment les changements environne-
mentaux (exemple : variation de la température ambiante), les entrées du processus, l’encras-
sement ou la dégradation des équipements, etc. Ce foisonnement d’informations rend difficile
l’élaboration d’un modèle global relativement précis, et répondant à toutes les sollicitations du
processus.
Si, sous l’hypothèse de stationnarité ou d’invariance dans le temps des processus industriels,
l’ACP statique (section précédente) peut raisonnablement être appliquée à la modélisation et
la surveillance, il en est autrement si cette hypothèse n’est plus considérée. En effet, la plupart
des procédés industriels ont réellement un comportement variant dans le temps, non entière-
ment compris et qui n’est pas préalablement connu. L’ACP statique, ne peut donc être la solution
envisageable. En fait, l’appliquer ,conduirait à un modèle non représentatif du processus réel.
Cela engendre de fausses alarmes et/ou des non détection des changements naturels dans le
fonctionnement du système, qui seront interprétés comme des défauts. Le problème de la mo-
délisation et de la surveillance des systèmes dynamiques à base de la méthode ACP statique a
été discuté dans la littérature (Li et al. 2000, Wang et al. 2005, Choi et al. 2006). L’étude de la
dynamique des processus a fait ressortir trois possibilités (Tien D. X., 2005) :
1. développer un modèle global pour les différents modes de fonctionnement du système ;
38

Analyse en Composantes Principales Adaptative (APCA)
2. développer un modèle local pour chaque mode de fonctionnement ;
3. mettre à jour de manière adaptative le modèle et tenir compte des changements interve-
nant dans le fonctionnement du système.
La première classe, concerne des modèles globaux, tenant compte de tous les modes de
fonctionnement du processus. Cela engendre une complexité associée à une imprécision dans le
fonctionnement du système. Dans la deuxième classe, une connaissance à priori sur les modes
de fonctionnement du système est nécessaire, afin d’établir un modèle local pour chaque mode.
La prédiction ou la représentation d’un comportement observé du système est obtenu par la
combinaison des prédictions des différents modèles locaux. Intuitivement, les approches dans
cette classe donnent une meilleure représentation sur l’état du système car le modèle local offre
une meilleure résolution . Par contre, elles soufrent d’inconvénients, notamment la difficulté
à identifier l’instant de transition d’un mode à un autre. Enfin, la troisième classe, où l’on ne
dispose pas d’informations suffisantes sur les modes de fonctionnement, s’intéresse à la mise à
jour continue du modèle. C’est cette dernière voie que nous avons adopté dans notre travail.
En fait, nous distinguons deux grandes classes de méthodes ACP qui peuvent prendre en charge
et résoudre cette question, l’Analyse en composantes principales à base d’une fenêtre glissante
(Moving Window PCA, MWPCA), et l’ACP récursive (RPCA). A chaque instant de mesure, de
nouvelles données apparaissent et une opération d’ajustement des paramètres du modèle ACP
est exécutée.
2.4.1 Les concepts de l’adaptation
On appelle adaptation, le processus de modification d’un objet de façon à rester fonctionnel
dans de nouvelles conditions. Avant de discuter les différents mécanismes disponibles dans la
littérature pour l’adaptation du modèle ACP, il est utile qu’une certaine terminologie pour la mo-
délisation adaptative soit explicitée : (i) dynamique ; (ii) adaptative ; (iii) incrémentale ; et (iv)
récursive (Kadlec et al., 2011). Cette terminologie ayant pour but principal, de mieux présenter
les stratégies d’adaptation qui existent.
Pour le premier terme, les modèles dynamiques essayent de capturer l’influence des don-
nées précédentes sur la mesure courante, dont la prédiction est fournie. Le terme adaptatif est
une description générale des modèles disposant de la possibilité de modifier automatiquement
leurs caractéristiques et/ou leurs structures internes (e.g. le nombre de composantes principales
pour le cas de l’ACP). Il est donc nécessaire que ce type de modèle, soit équipé d’un mécanisme
permettant de s’adapter et de tenir compte des nouvelles données collectées en ligne, et d’être
renseigné sur leur feed-back en termes de performance. Il existe différents types d’algorithmes
d’adaptation, on peut notamment citer : les méthodes se basant sur une fenêtre glissante (Mo-
ving Window, MW) et les méthodes récursives. Pour le cas des algorithmes incrémentaux, plus
39

Analyse en Composantes Principales Adaptative (APCA)
que les modèles adaptatifs, ils devront remplir d’autres exigences . Le point le plus critique dans
ce cas, c’est l’impossibilité de stocker et donc d’exploiter l’historique des données, puisque ils
ne travaillent qu’échantillon par échantillon (sample-wise), à l’opposé des techniques d’adapta-
tion par bloc d’échantillons (block-wise). Enfin, La dernière catégorie d’algorithmes se base sur
la technique récursive. En général, la récursivité se réfère à l’autoréférence, i.e. une fonction
s’appelle par elle-même à chaque mesure disponible. Dans un sens, un algorithme récursif peut
également être considéré comme un algorithme incrémental.
Adapter ou apprendre au cours du temps, c’est élaborer une connaissance nouvelle et/ou
transformer une connaissance ancienne. Les techniques d’apprentissage, s’appuient sur l’oubli
progressif d’anciennes connaissances au profit de nouvelles acquisitions. Un dilemme apparait
alors entre l’apprentissage et l’oubli, appelé dilemme "stabilité-plasticité" (stability-plasticity di-
lemma) (Carpenter and Grossberg, 1998).
dilemme "stabilité-plasticité" : Si la plasticité, l’adaptativité est privilégiée, on diminue la ca-
pacité du modèle à mémoriser le passé et de stabiliser la représentation des informations apprises.
Si au contraire, la stabilité est privilégiée, on diminue la capacité du modèle à apprendre de nouveau.
FIGURE 2.1 – La fonction d’adaptation du modèle
Il s’agit alors de trouver un compromis optimal entre ces deux contraintes. La fonction d’oubli
permet de l’atteindre, en se basant sur l’estimation du niveau de variation dans le comportement
dynamique du système (Fig. (2.1)). Si les variations sont plus ou moins rapides, des contraintes
de flexibilité sont nécessaires pour permettre aux techniques de modélisation d’adapter rapide-
ment leurs paramètres. Par contre, si les variations sont plus ou moins lentes ces techniques
doivent également être capables de repérer et d’apprendre les structures et les invariants du
système. On a donc une coexistence de deux contraintes qui semblent a priori opposées. D’une
part, on a besoin d’un mécanisme instable et exploratoire, permettant au modèle de modifier
rapidement ces paramètres face aux variations de fonctionnement. D’autre part, on a besoin
40

Analyse en Composantes Principales Adaptative (APCA)
d’un mécanisme de stabilisation et de mémorisation, permettant au modèle d’apprendre pro-
gressivement les régularités des variations observées. Cependant, si la nature des variations des
systèmes dynamiques n’est pas préalablement connue ou entièrement comprise, un choix er-
roné de la fonction d’adaptation du modèle peut engendrer une mauvaise représentation de
l’état de fonctionnement actuel du système. Dans la surveillance et le diagnostic en temps réel ,
ce problème a un impact significatif sur la sensibilité de la détection de défauts ainsi que sur la
robustesse face aux fausses alarmes.
Si un cas extrême de ce problème est choisi, par exemple, la fonction d’oubli du mécanisme
d’adaptation est trop élevée (French, 1999), seules les nouvelles (dernières) connaissances ac-
quises permettent d’ajuster le modèle, tandis que les connaissances apprises précédemment sont
complètement écartées. Le processus d’adaptation deviendra sensible, rapide, et avec une grande
fréquence d’adaptation du modèle.
Par contre des comportements indésirables (bruits) ou anormaux (défauts) peuvent passer
inaperçus et intégrer directement la structure du modèle. Un effet similaire est observé lorsque
une fenêtre d’adaptation très courte est choisie dans le cas des techniques d’adaptation basée sur
une fenêtre glissante. Dans le cas inverse, où la plasticité du système est trop faible (et par consé-
quent la stabilité est trop élevée), cela peut aussi empêcher le modèle de s’adapter aux variations
rapides du système. De ce fait, on peut dire que le dilemme "stabilité-plasticité" est le facteur qui
consiste à mesurer la sensibilité d’adaptation du modèle par rapport aux changements observés
sur le fonctionnement du système. Il est donc nécessaire de disposer d’un mécanisme permet-
tant de gérer la notion d’oubli des anciennes informations au cours du temps. Les approches les
plus pratiques dans cette situation sont celles qui utilisent des fonctions d’oubli, variables, et des
fenêtres glissantes de taille variable au cours du temps, dont la plasticité est ajustée en fonction
du niveau de variation estimé dans le comportement du système.
D’après Li et al. (2000), tout algorithme complet de la méthode ACP adaptative devrait tenir
compte des éléments suivants :
1. mettre à jour les paramètres de normalisation (moyenne, variance), ainsi que la matrice
de variance-covariance ou de corrélation ;
2. adapter et mettre à jour les paramètres ACP sous deux formes : (i) sur une base continue,
échantillon par échantillon (adapt on sample-wise), lorsque les conditions de fonctionne-
ment du processus changent graduellement ou brusquement. ou (ii) sur une base discon-
tinue, en bloc d’échantillons (adapt on block-wise), lorsqu’un processus varie lentement
et que le temps d’échantillonnage est très petit par rapport à sa constante de temps. Il
est donc inutile de mettre à jour le modèle à chaque nouvelle acquisition, cela permet de
réduire le temps de calcul.
3. détermination récursive du nombre de composantes principales.
41
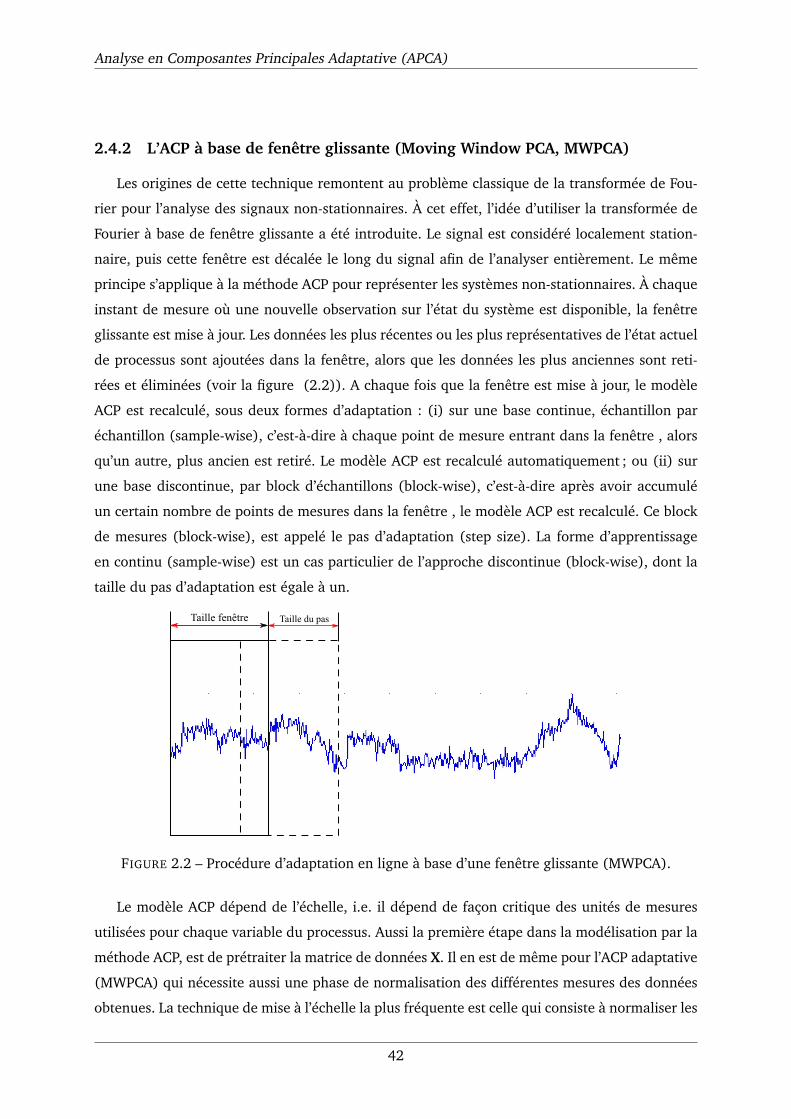
Analyse en Composantes Principales Adaptative (APCA)
2.4.2 L’ACP à base de fenêtre glissante (Moving Window PCA, MWPCA)
Les origines de cette technique remontent au problème classique de la transformée de Fou-
rier pour l’analyse des signaux non-stationnaires. À cet effet, l’idée d’utiliser la transformée de
Fourier à base de fenêtre glissante a été introduite. Le signal est considéré localement station-
naire, puis cette fenêtre est décalée le long du signal afin de l’analyser entièrement. Le même
principe s’applique à la méthode ACP pour représenter les systèmes non-stationnaires. À chaque
instant de mesure où une nouvelle observation sur l’état du système est disponible, la fenêtre
glissante est mise à jour. Les données les plus récentes ou les plus représentatives de l’état actuel
de processus sont ajoutées dans la fenêtre, alors que les données les plus anciennes sont reti-
rées et éliminées (voir la figure (2.2)). A chaque fois que la fenêtre est mise à jour, le modèle
ACP est recalculé, sous deux formes d’adaptation : (i) sur une base continue, échantillon par
échantillon (sample-wise), c’est-à-dire à chaque point de mesure entrant dans la fenêtre , alors
qu’un autre, plus ancien est retiré. Le modèle ACP est recalculé automatiquement ; ou (ii) sur
une base discontinue, par block d’échantillons (block-wise), c’est-à-dire après avoir accumulé
un certain nombre de points de mesures dans la fenêtre , le modèle ACP est recalculé. Ce block
de mesures (block-wise), est appelé le pas d’adaptation (step size). La forme d’apprentissage
en continu (sample-wise) est un cas particulier de l’approche discontinue (block-wise), dont la
taille du pas d’adaptation est égale à un.
FIGURE 2.2 – Procédure d’adaptation en ligne à base d’une fenêtre glissante (MWPCA).
Le modèle ACP dépend de l’échelle, i.e. il dépend de façon critique des unités de mesures
utilisées pour chaque variable du processus. Aussi la première étape dans la modélisation par la
méthode ACP, est de prétraiter la matrice de données X. Il en est de même pour l’ACP adaptative
(MWPCA) qui nécessite aussi une phase de normalisation des différentes mesures des données
obtenues. La technique de mise à l’échelle la plus fréquente est celle qui consiste à normaliser les
42

Analyse en Composantes Principales Adaptative (APCA)
données (centrage et réduction) en utilisant la moyenne et l’écart type de la matrice de données
X. A chaque nouvelle mesure, les paramètres de normalisation (moyenne et l’écart type) doivent
être mis à jour. À chaque instant où une nouvelle donnée est disponible dans la fenêtre de taille
fixe (L), un nouveau block de données Xk ∈ ℜL×m est obtenu. Les paramètres de normalisation
de ce block de données sont calculés comme suit :
bk =
∑Li=1 x(k)
L(2.45)
σk =
∑Li=1(x(k) − bk)
2
L(2.46)
où b et σ sont la moyenne et l’écart-type du block de données obtenus à l’instant k. Un vecteur
de mesure appartenant à ce block de données, est normalisé comme suit :
x =x − b
σ(2.47)
Une fois le block de données normalisé, l’algorithme de base de la méthode ACP lui est
appliqué . Une décomposition en valeurs et vecteurs propre de la matrice de corrélation Rk
(P Tk RkPk = Λk) est alors effectuée sur cette fenêtre de données. Le modèle ACP est recalculé
en relation avec ces nouvelles informations. Le nombre optimal de composantes principales est
calculé en utilisant les algorithmes présentés dans la partie précédente. Ce même algorithme est
sollicité à chaque instant où de nouvelles données arrivent dans la fenêtre. La procédure peut
être résumée comme suit :
fk = L(DM
)avec DM = xik
i=k−L+1 (2.48)
où fk est le nouveau modèle, L est l’algorithme d’apprentissage, et DM est l’ensemble des der-
niers points de mesure (L) pour l’apprentissage du nouveau modèle.
Deux paramètres influencent de façon critique la performance du modèle reconstruit. Ils
s’agit de la taille de la fenêtre glissante, et le pas d’adaptation. Dans le cas idéal, la taille de
la fenêtre doit correspondre à la nature du système, fonctionnement lent ou rapide. En effet,
si les changement du processus sont plus ou mois rapide, la fenêtre nécessite d’être de petite
taille afin de modéliser correctement les détails de variations. Par contre, si les changement sont
lents, la fenêtre glissante nécessite d’être de grande taille pour couvrir les variations suffisantes
afin de bien modéliser les corrélations entre les données. Dans le cas où ces prescriptions ne
sont pas bien respectées, le niveau d’adaptation peut être limité. Ce problème peut être résolu
en appliquant une technique d’adaptation de la taille de la fenêtre glissante à la dynamique du
système.
43
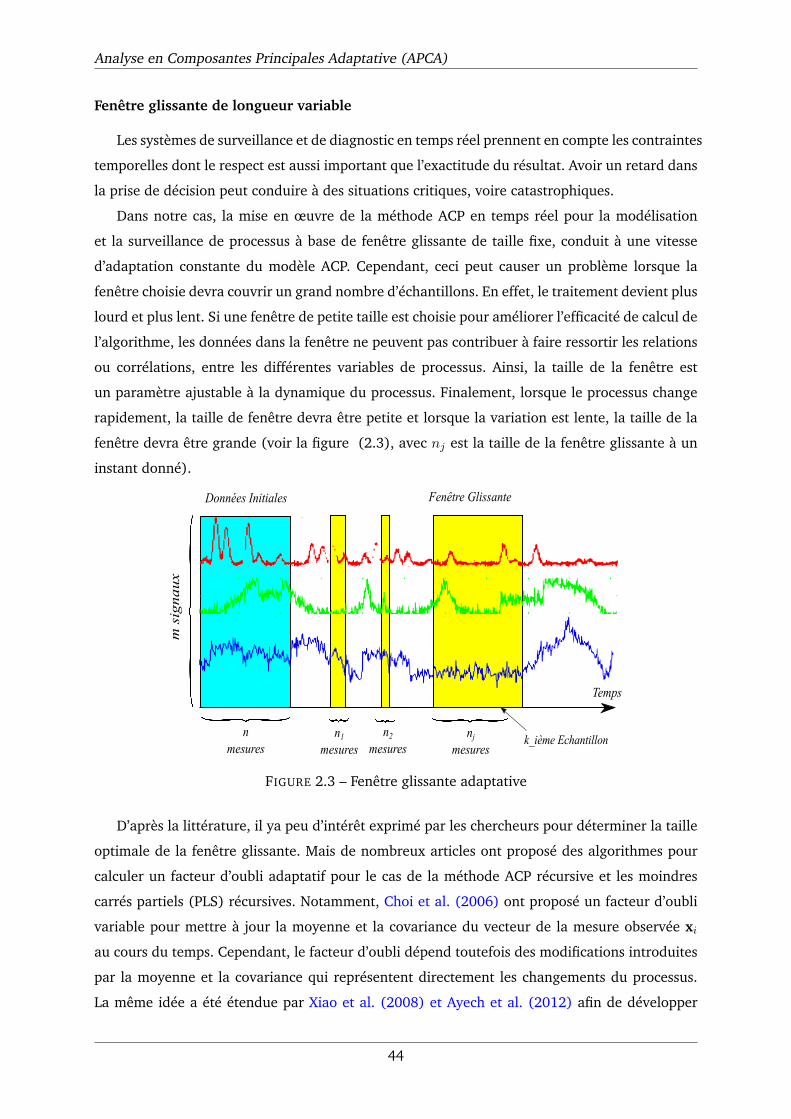
Analyse en Composantes Principales Adaptative (APCA)
Fenêtre glissante de longueur variable
Les systèmes de surveillance et de diagnostic en temps réel prennent en compte les contraintes
temporelles dont le respect est aussi important que l’exactitude du résultat. Avoir un retard dans
la prise de décision peut conduire à des situations critiques, voire catastrophiques.
Dans notre cas, la mise en œuvre de la méthode ACP en temps réel pour la modélisation
et la surveillance de processus à base de fenêtre glissante de taille fixe, conduit à une vitesse
d’adaptation constante du modèle ACP. Cependant, ceci peut causer un problème lorsque la
fenêtre choisie devra couvrir un grand nombre d’échantillons. En effet, le traitement devient plus
lourd et plus lent. Si une fenêtre de petite taille est choisie pour améliorer l’efficacité de calcul de
l’algorithme, les données dans la fenêtre ne peuvent pas contribuer à faire ressortir les relations
ou corrélations, entre les différentes variables de processus. Ainsi, la taille de la fenêtre est
un paramètre ajustable à la dynamique du processus. Finalement, lorsque le processus change
rapidement, la taille de fenêtre devra être petite et lorsque la variation est lente, la taille de la
fenêtre devra être grande (voir la figure (2.3), avec nj est la taille de la fenêtre glissante à un
instant donné).
FIGURE 2.3 – Fenêtre glissante adaptative
D’après la littérature, il ya peu d’intérêt exprimé par les chercheurs pour déterminer la taille
optimale de la fenêtre glissante. Mais de nombreux articles ont proposé des algorithmes pour
calculer un facteur d’oubli adaptatif pour le cas de la méthode ACP récursive et les moindres
carrés partiels (PLS) récursives. Notamment, Choi et al. (2006) ont proposé un facteur d’oubli
variable pour mettre à jour la moyenne et la covariance du vecteur de la mesure observée xi
au cours du temps. Cependant, le facteur d’oubli dépend toutefois des modifications introduites
par la moyenne et la covariance qui représentent directement les changements du processus.
La même idée a été étendue par Xiao et al. (2008) et Ayech et al. (2012) afin de développer
44

Analyse en Composantes Principales Adaptative (APCA)
un algorithme permettant de définir une fenêtre glissante adaptative. La taille de la fenêtre à
l’instant k est définie comme suit :
Lk = Lmin + (Lmax − Lmin) exp−(α∥bk∥∥b0∥
+ β∥Rk∥∥R0∥
)γ(2.49)
où Lmin et Lmax sont la valeur minimale et la valeur maximale de la fenêtre glissante, respec-
tivement, α, β, et γ sont les paramètres de la fonction. ∥bk∥ = ∥bk − bk−1∥ est la norme
du vecteur euclidien de la différence entre deux vecteurs moyens consécutifs. Similairement,
∥Rk∥ = ∥Rk − Rk−1∥ est la norme de la matrice euclidienne de la différence entre deux ma-
trices de covariance consécutives. ∥b0∥ est la variation moyenne de base dans l’état d’équilibre,
où il n’y a aucun changement de mode de fonctionnement ou anomalie (la différence entre la
moyenne de l’échantillon précédent et la moyenne utilisée en traitant les données historiques).
De même, ∥R0∥ est la variation de base de la matrice de corrélation.
Les deux paramètres suivant, Lmax et Lmin déterminent les limites d’ajustement ou l’in-
tervalle de variation de la taille de la fenêtre glissante. Lorsque le processus varie très len-
tement, les taux de changement dans la moyenne et la matrice de corrélation tendent vers
zéro (∥bk∥ → 0 et ∥Rk∥ → 0), et donc, la taille de la fenêtre tend vers la valeur maximale
(L→ Lmax). Maintenant, lorsque le processus connaît un changement très rapide, les taux de
changement dans la moyenne et la matrice de corrélation tendent vers l’infini (∥bk∥ → ∞) et
(∥Rk∥ → ∞), et la taille de la fenêtre tend vers la valeur minimale (L→ Lmin).
Afin d’avoir une bonne estimation de la matrice de corrélation (variance-covariance) des
données Xk ∈ ℜL×m, un ensemble de mesures de données minimales (Lmin) est nécessaire au
sein de la fenêtre glissante. Si la taille de la fenêtre est très petite, les erreurs d’estimation des
grandeurs de la moyenne et de la matrice de variance/covariance au cours du temps devraient
être significatives. Le nombre d’échantillons requis pour estimer la variance d’une seule variable
a été largement discuté dans les années 1950 et au début des années 1960 (Graybill 1958 ;
Graybill and Connell 1964 ; Graybill and Morrison 1960 ; Greenwood and Sandomire 1950).
Il faudrait que la valeur minimale de la fenêtre glissante Lmin soit suffisamment grande pour
éviter à la matrice de covariance d’être inexacte ou insuffisante. Selon Xiao et al. (2008), le
nombre de points de données Sp nécessaire pour construire un modèle ACP stable devrait être
supérieur ou égal au nombre de paramètres indépendants Mr dans le modèle. Le nombre de
paramètres indépendants est défini comme suit :
Sp ≥ Spmin = Mr (2.50)
où Spmin = Lth ×m. Avec Lth est la valeur du seuil de la taille de la fenêtre afin de reconstruire
45

Analyse en Composantes Principales Adaptative (APCA)
un modèle ACP stable. Avec un modèle ACP stable, nous avons également
Mr =l + 2lm− l2
2(2.51)
Ainsi, Lth peut être calculé comme suit :
Lth =l + 2lm− l2
2m(2.52)
avec l est le nombre de composantes principales, optimal (PCs) à retenir dans le modèle ACP, et
m est le nombre de variables à surveiller.
Enfin, la description simplifiée de la méthode ACP à base de fenêtre glissante (MWPCA) est
résumée dans l’algorithme qui suit. Généralement les algorithmes de modélisation des systèmes
variables dans le temps sont décomposés en deux parties, la première est hors ligne et la seconde
en ligne.
1. Apprentissage hors ligne : (identification du modèle ACP initial) :
(a) Acquérir l’historique de données disponibles Xinit, issues des différents capteurs-
actionneurs du système, en état de bon fonctionnement ;
(b) Calculer les valeurs initiales des paramètres de normalisation de la matrice Xinit, le
vecteur de la moyenne b0 et le vecteur de la variance σ0 ;
(c) Normaliser la matrice de données, et calculer le modèle ACP initial (valeurs propres
Λ0, vecteurs propres P0) ;
(d) Déterminer le nombre (l) de composantes principales (PCs) ;
(e) Calculer Lth en fonction des valeurs de l et m ;
(f) Déterminer l’intervalle de variation de la taille de la fenêtre glissante, Lmax et Lmin ;
(g) Sélectionner les paramètres de la fonction d’adaptation de la fenêtre : α, β, γ ;
(h) Calculer ∥b0∥ et ∥R0∥ ;
2. Apprentissage en ligne : (identification du modèle ACP au cours du temps) :
A chaque nouvelle mesure disponible, et selon le type de mise à jour de la fenêtre glissante
(block-wise ou sample-wise) ;
(a) Un nouveau block de donnée xnew ∈ ℜnk+1×m est disponible à l’instant k + 1 ;
(b) Déterminer la taille de la fenêtres Lk+1 ;
(c) Si Lk+1 ≤ Lk, éliminer les Lk−Lk+1 plus anciennes mesures de données de la fenêtre,
et passer à l’étape suivante ;
46

Analyse en Composantes Principales Adaptative (APCA)
(d) Mettre à jour les paramètres de normalisation à partir du nouveau block de données
présent dans la fenêtre ;
(e) Calculer le modèle ACP (valeurs propres Λk+1 et vecteurs propres Pk+1) ;
(f) Recalculer le nombre de composantes principales ;
(g) Estimer le bloc de données disponible à l’instant k + 1 et obtenir Xk+1 ;
(h) Passez à l’étape 2.(a) ;
(i) Sinon, insérer ensuite la mesure collectée dans la fenêtre Lk+1 = Lk +nk+1, et passez
à l’étape 2.(a).
Il existe également quelques contraintes liées à la méthode MWPCA, notamment le stockage
systématique de toutes les données introduites dans la fenêtre. Cette opération consomme beau-
coup de mémoire, et influence le temps et la complexité de calcul.
2.4.3 L’ACP Récursive (RPCA)
Contrairement à la méthode ACP adaptative basée sur une fenêtre glissante, les méthodes
récursives consistent à reconstruire le modèle actuel en relation avec le modèle de l’instant
précédent (figure (2.4)). En effet, l’adaptation comporte habituellement une pondération de
l’information précédente en utilisant un facteur d’oubli. Les coefficients de pondération sont
attribués en fonction de l’âge de la mesure collectée. De ce fait, le paramètre le plus impor-
tant est la vitesse de la décroissance temporelle des poids attribués aux différents échantillons
de mesure (plasticité-stabilité), autrement dit, c’est la façon de transformer les connaissances
anciennes et/ou d’adaptation avec les connaissances nouvelles. Similairement à la technique
de fenêtre glissante, et d’après le type de variation observée sur le fonctionnement du système
(variations brusques ou lentes), le facteur de pondération est choisi. Le rôle du facteur d’oubli
consiste à maitriser, ou à contrôler la quantité de connaissances transférées entre l’ancien et le
nouveau modèle.
Premièrement, afin d’être en mesure de mettre à jour le modèle ACP d’une manière récur-
sive, les mesures de données entrantes xk au cours du temps nécessitent d’être normalisées de
la même manière que dans le cas hors ligne. A cet effet, il est nécessaire de mettre à jour de ma-
nière récursive les paramètres statistiques qui caractérisent l’ensemble de données des variables
étudiées (la moyenne, la variance, et la matrice de corrélation ou de variance-covariance). Pour
formaliser ce problème, un modèle ACP adaptatif, pondéré exponentiellement (adaptive expo-
nentially weighted moving PCA, EWPCA) est introduit dans la littérature. En fait, les anciens
échantillons de mesure sont pondérés exponentiellement dans le temps, de sorte que les me-
sures récentes sont les plus pertinentes.
47
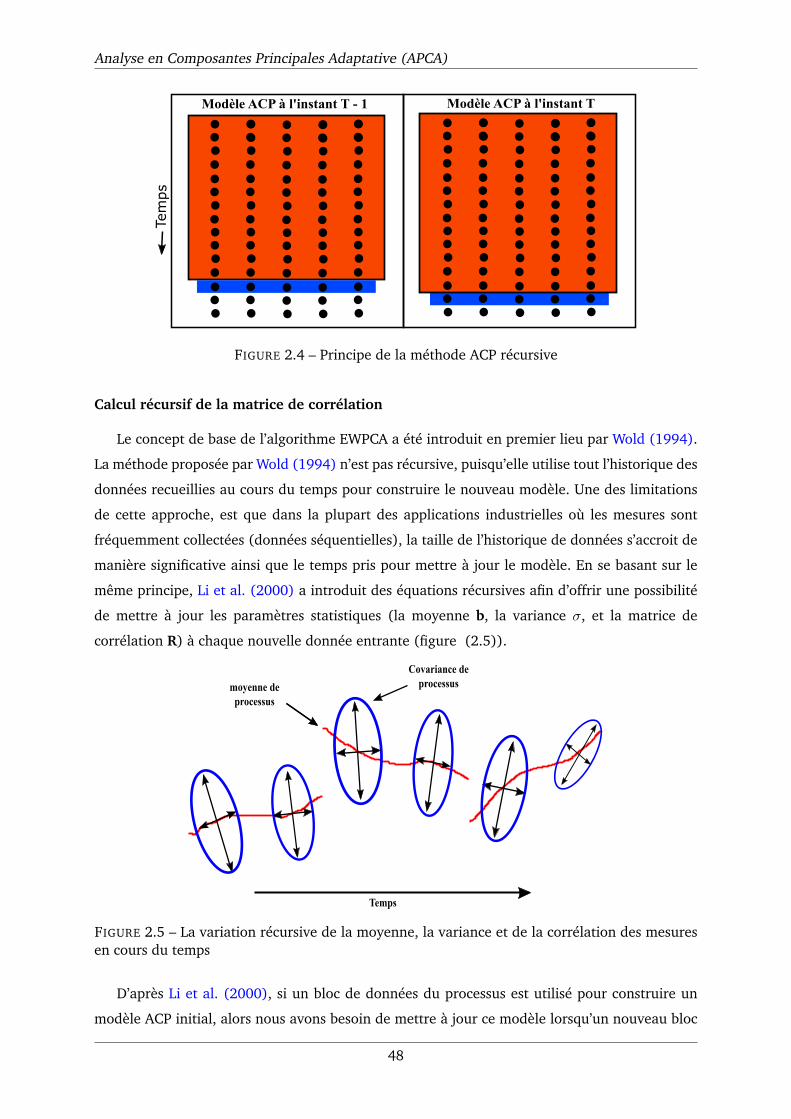
Analyse en Composantes Principales Adaptative (APCA)
FIGURE 2.4 – Principe de la méthode ACP récursive
Calcul récursif de la matrice de corrélation
Le concept de base de l’algorithme EWPCA a été introduit en premier lieu par Wold (1994).
La méthode proposée par Wold (1994) n’est pas récursive, puisqu’elle utilise tout l’historique des
données recueillies au cours du temps pour construire le nouveau modèle. Une des limitations
de cette approche, est que dans la plupart des applications industrielles où les mesures sont
fréquemment collectées (données séquentielles), la taille de l’historique de données s’accroit de
manière significative ainsi que le temps pris pour mettre à jour le modèle. En se basant sur le
même principe, Li et al. (2000) a introduit des équations récursives afin d’offrir une possibilité
de mettre à jour les paramètres statistiques (la moyenne b, la variance σ, et la matrice de
corrélation R) à chaque nouvelle donnée entrante (figure (2.5)).
FIGURE 2.5 – La variation récursive de la moyenne, la variance et de la corrélation des mesuresen cours du temps
D’après Li et al. (2000), si un bloc de données du processus est utilisé pour construire un
modèle ACP initial, alors nous avons besoin de mettre à jour ce modèle lorsqu’un nouveau bloc
48

Analyse en Composantes Principales Adaptative (APCA)
de données devient disponible. Soit X1 ∈ ℜn1×m un historique de données initiales prélevées sur
le système lorsque il est considéré en bon fonctionnement. Alors la moyenne de chaque colonne
est donnée par le vecteur suivant,
b1 =1
n1
(X1)T 1n1 (2.53)
avec 1n1 = [1, 1, ..., 1]T ∈ ℜn1 , et n1 est la taille, ou le nombre de mesures accumulées dans le
bloc de données X1. Ainsi, la matrice de données centrée et réduite est donnée comme suit :
X1 =(
X1 − 1n1bT1
)Σ−1
1 où Σ1 = diag (σ1.1, ..., σ1.m) (2.54)
dont le ième élément de la matrice Σ1 représente l’écart type du la ième variable (i = 1, ...,m).
La matrice de corrélation est donnée ainsi :
R1 =1
n1 − 1
(XT
1 X1
)(2.55)
En fait, un nouveau bloc de mesures est attendu afin d’augmenter la matrice de données et
de calculer la matrice de corrélation de manière récursive. Nous supposons que bk, Xk, et Rk ont
été calculées à l’instant k. Donc, la tâche récursive consiste à calculer les paramètres statistiques(bk+1, Xk+1, et Rk+1
)lorsque un nouveau bloc de données à l’instant suivant Xnk+1
∈ ℜnk+1×m
est disponible. En notant que :
Xk+1 =
[Xk
Xnk+1
](2.56)
Pour tout bloc de données obtenu à l’instant k + 1, le vecteur bk+1 est toujours en relation
avec le vecteur bk de l’instant précédent, en utilisant la formulation suivante :(k+1∑i=1
ni
)bk+1 =
(k∑
i=1
ni
)bk +
(Xnk+1
)T1nk+1
(2.57)
En notant que Nk =∑k
i=1 ni, l’équation (2.57) donne la formulation récursive suivante :
bk+1 =Nk
Nk+1
bk +1
Nk+1
(Xnk+1
)T1nk+1
(2.58)
En effet, le calcul récursif de la matrice de donnée centrée et réduite (normalisée) Xk+1, à
l’instant k + 1 est donnée par :
49

Analyse en Composantes Principales Adaptative (APCA)
Xk+1 =(
Xk+1 − 1nk+1bTk+1
)Σ−1
k+1 (2.59)
=
Xk
Xnk+1
− 1nk+1bTk+1
Σ−1k+1 (2.60)
=
Xk − 1k∆bTk+1 − 1kbT
k
Xnk+1− 1nk+1
bTk+1
Σ−1k+1 (2.61)
=
XkΣkΣ−1k+1 − 1k∆bT
k+1Σ−1k+1
Xnk+1
(2.62)
où
Xk =(
Xk − 1tbTk
)Σ−1
k .
Xnk+1=
(Xnk+1
− 1nk+1bT
k+1
)Σ−1
k+1.
Σj = diag (σj.1, ..., σj.m) , avec j = k, k + 1.
∆bk+1 = bk+1 − bk.
1k = [1, 1, ..., 1]T ∈ ℜNk .
(2.63)
Le calcul récursif de l’écart type est formulé comme suit :
(Nk+1 − 1)σ2k+1 = (Nk − 1)σ2
k +Nk∆b2k+1 + ∥Xnk+1
− 1nk+1bk+1∥2 (2.64)
De même, le calcul récursif de la matrice de corrélation, a la forme suivante :
Rk+1 =1
Nk+1 − 1XT
k+1Xk+1 −Nk − 1Nk+1 − 1
Σ−1k+1ΣkRkΣkΣ−1
k+1 (2.65)
+Nk
Nk+1 − 1Σ−1
k+1∆bk+1∆bTk+1Σ
−1k+1 +
1Nk+1 − 1
XTnk+1
Xnk+1(2.66)
Le plus souvent, les anciennes mesures de données sont exponentiellement ignorées, car
elles ne sont pas représentatives du fonctionnement en cours (actuel) du processus. De ce fait,
selon Li et al. , la formulation récursive des équations précédentes (2.58), (2.64) et (2.66) ,
en utilisant un facteur d’oubli , prend la forme suivante :
bk+1 = µbk + (1 − µ)1
nk+1
(Xnk+1
)T1nk+1
(2.67)
σ2k+1 = µ
(σ2
k + ∆b2k+1
)+ (1 − µ)
1
nk+1
∥Xnk+1− 1nk+1
bk+1∥2 (2.68)
50

Analyse en Composantes Principales Adaptative (APCA)
Rk+1 = µΣ−1k+1
(ΣkRkΣk + ∆bk+1∆bT
k+1
)Σ−1
k+1 + (1 − µ)1
nk+1
XTnk+1
Xnk+1(2.69)
En effet, lorque Nk ≫ 1, dans les relations précédentes, µ =Nk
Nk+1représente le facteur
d’oubli et il est compris entre 0 et 1, 0 < µ =Nk
Nk+1< 1 .
La procédure de mise à jour (présentée ci-dessus) de tous les paramètres définissant la dyna-
mique du système en bloc d’échantillons (block-wise), est identique à celle du cas continue, i.e.
en échantillon par échantillon (sample-wise). En effet, à chaque instant de mesure où xk ∈ ℜ1×m
est disponible, les paramètres (moyenne, variance et matrice de corrélation) sont mis à jour. Les
équations récursives (2.67), (2.68) et (2.69) prennent la forme suivante :
bk+1 = µbk + (1 − µ) xk+1 (2.70)
σ2k+1 = µ
(σ2
k + ∆b2k+1
)+ (1 − µ) ∥xk+1 − bk+1∥2 (2.71)
Rk+1 = µΣ−1k+1
(ΣkRkΣk + ∆bk+1∆bT
k+1
)Σ−1
k+1 + (1 − µ) xTk+1xk+1 (2.72)
Comme pour le principe de la fenêtre glissante, une petite valeur du µ a tendance à oublier
les anciennes données plus rapidement. Il a bien été montré, comme dans le critère plasticité-
stabilité, que le facteur d’oubli nécessite d’être flexible (variable) afin de permettre une meilleure
adaptation aux variations lentes ou brusques du système étudié.
Mise à jour du modèle ACP
A chaque instant, où un nouvel échantillon de mesure ou un nouveau bloc d’échantillons de
données devient disponible, la matrice de corrélation est mise à jour en relation avec ces nou-
velles données. Les valeurs et les vecteurs propres de cette nouvelle matrice de corrélation, sont
calculés, pour obtenir une nouvelle représentation ACP. Pour leur calcul, plusieurs approches ont
été proposées dans la littérature, notamment celle basée sur une décomposition en valeurs sin-
gulières (SVD) de la matrice de corrélation courante, qui est la plus utilisée. Une des contraintes,
liée à ces techniques relève de la complexité de calcul, i.e temps de traitement des algorithmes.
La matrice de corrélation Rk+1 peut être approchée par :
Rk+1 ≈ Pk+1Λk+1PTk+1 (2.73)
où Λ et P sont les valeurs et les vecteurs propres de la matrice de corrélation à l’instant (k + 1),
respectivement.
Afin de permettre une décomposition de la matrice de corrélation Rk+1, Li et al. (2000)
51

Analyse en Composantes Principales Adaptative (APCA)
ont proposé deux algorithmes de l’ACP récursive. Ils se basent sur la technique de modification
en rang unitaire (rank-one modification) et la tridiagonalisation de Lanczos (Lanczos tridiago-
nalization, LT). La première a été développée pour le cas de l’apprentissage en continue (i.e.
échantillon par échantillon). La seconde, a été développée pour l’apprentissage en bloc de don-
nées. D’après Li et al. (2000) ces deux approches sont meilleures en termes de complexité de
calcul, que l’algorithme classique SVD. Par contre, parmi les contraintes, on peut citer celles qui
nécessitent la mise à jour et le stockage de la matrice de corrélation dans son intégralité, surtout
lorsque le nombre de variables à surveiller est assez grand. Sur cette question, Choi et al. (2006)
proposent une nouvelle approche.
Une fois, obtenu les valeurs et les vecteurs propres de la matrice de corrélation, mise à jour,
on procède à la détermination récursive du nombre de composantes principales à retenir dans le
modèle ACP. Dans l’apprentissage continu, ce paramètre peut évoluer dans le temps. Il se trouve
que la plupart des méthodes présentées dans le cas statique, ne sont pas adaptées au cas de
l’ACP récursive. Par exemple, l’approche de validation croisée n’est pas appropriée, parce que les
données anciennes ne sont pas représentatives de l’état en cours du processus. C’est pourquoi,
Li et al. (2000) ont recommandé un ensemble de méthodes pour la détermination du nombre de
composantes principales, dans le cas de l’ACP récursive. Parmi ces méthodes , il y a l’approche
du pourcentage cumulé (PCV).
Facteur d’oubli variable
Un point important à souligner dans la technique EWPCA, c’est le choix optimal du facteur
d’oubli, qui détermine l’influence des données les plus anciennes sur le modèle actuel. Toujours
en relation avec le critère "plasticité-stabilité", durant les périodes où la dynamique du processus
change rapidement, l’accent est mis sur les observations les plus récentes. Afin de tenir compte
des variations (lentes ou rapides) avec une forme de flexibilité définie, la pondération expo-
nentielle des différents paramètres caractérisant la dynamique du processus est articulée sur un
facteur d’oubli uni-varié proposé par Fortescue et al. (1981). La pondération attribuée à chaque
observation dépend de la variation dans le vecteur de mesures Xnk+1. Le facteur d’oubli est alors
calculé comme suit :
µk = 1 −
(1 − T 2
k
m
)SPEk
m√nk − 1
(2.74)
avec T2 est la distance statistique de Hotelling, T2 =∑l
i=1
(t2iλi
), et SPE (squared prediction er-
ror), SPE =∑m
i=1 (xi − xi) = e2. Ces deux distances sont utilisées souvent pour la surveillance
et le suivi du processus, c’est l’objet du chapitre 04.
52

Analyse en Composantes Principales Adaptative (APCA)
Choi et al. (2006) ont proposé un algorithme d’adaptation au cours du temps, du facteur de
pondération µ. Il s’appuie sur le calcul d’une première pondération de la moyenne, intégrant la
nouvelle donnée, et sur une seconde pondération de la matrice de corrélation. Pour mettre à
jour le vecteur moyenne, le facteur d’oubli est calculé selon la formule suivante :
αk = αmax − (αmax − αmin) [1 − exp −ϑ (∥bt−1∥/∥bnor∥)n] (2.75)
où αmin et αmax sont la valeur minimale et la valeur maximale du facteur de pondération,
respectivement, ϑ, β, et n sont les paramètres de la fonction. Ainsi, ∥b∥ = ∥bk − bk−1∥ est
la norme du vecteur euclidien de la différence entre deux vecteurs consécutifs de la moyennes.
Pour |bnor∥ est la moyenne ∥b∥ obtenue en utilisant les données historiques. De même, pour
mettre à jour la matrice covariance, le facteur d’oubli est donné par :
βk = βmax − (βmax − βmin) [1 − exp −ϑ (∥Rk−1∥/∥Rnor∥)n] (2.76)
où βmin et βmax sont la valeur minimale et la valeur maximale du facteur de pondération,
respectivement, k, β, et n sont les paramètres de la fonction. Ainsi, ∥R∥ = ∥Rk − Rk−1∥ est la
norme de la matrice euclidienne de la différence entre deux matrices de covariance consécutives.
Le choix de ces valeurs est généralement fait de façon empirique. Par exemple, Choi et al.
(2006) ont adopté la démarche suivante :
1. Sélectionner une valeur pour αmax et αmin, typiquement le choix de αmax varie entre
(0.999 − 0.99), et pour αmin, varie entre (0.95 − 0.90).
2. Déterminer ϑ de telle sorte que α = µ (αmax − αmin) +αmin lorsque ∥bk−1∥/∥bnor∥ =
1.
3. Sélectionner n entre 1 et 3. Cette orientation est également applicable pour la détermina-
tion du facteur d’oubli β.
Enfin, la description simplifiée de la méthode ACP récursive est résumée dans l’algorithme
suivant :
1. Apprentissage hors ligne : (identification du modèle ACP initial) :
(a) Acquérir l’historique de données disponible Xinit, issue du bon fonctionnement des
différents capteurs-actionneurs du système ;
(b) Calculer les valeurs initiales des paramètres de normalisation de la matrice Xinit, le
vecteur de la moyenne b0, le vecteur de la variance σ0, et la matrice de corrélation
R0 ;
(c) Calculer le modèle ACP initial (valeurs propres Λ0, vecteurs propres P0) ;
(d) Déterminer le nombre (l) de composantes principales (PCs) ;
53

Analyse en Composantes Principales Adaptative (APCA)
(e) Sélectionner les valeurs αmin, αmax, βmin et βmax ;
(f) Déterminer les paramètres de la fonction de pondération : n, k ;
(g) Calculer ∥bnor∥ et ∥Rnor∥ ;
(h) Déterminer les valeurs initiales des deux facteurs d’oubli, α0, β0 ;
2. Apprentissage en ligne : (identification du modèle ACP en cours du temps) :
(a) Un nouveau block de données xnew ∈ ℜnk+1×m est disponible à l’instant k + 1 ;
(b) Mettre à jour les paramètres de normalisation, bk+1 et σk+1 ;
(c) Mettre à jour la matrice de corrélation Rk+1.
(d) Calculer les valeurs et les vecteurs propres de la matrice de variance-covariance mis
à jour, Rk+1 ≈ Pk+1Λk+1PTk+1 ;
(e) Calculer le nombre de composantes principales à inclure dans le modèle.
(f) Estimer le bloc de données disponible à l’instant k + 1 et obtenir xnew ;
(g) Mettre à jour les facteurs de pondération (d’oubli), αk+1, βk+1 ;
(h) Revenez à l’étape 2.(a) et répétez l’itération pour le prochain vecteur de mesures
disponibles à l’instant (k + 2).
2.4.4 L’ACP à base de fenêtre glissante rapide (Fast Moving Window PCA)
Comme déjà indiqué dans les sections précédentes, il est suggéré dans la littérature deux
approches principales pour la mise à jour du modèle ACP. La première est liée à une fenêtre
glissante. Celle-ci s’applique à l’ensemble des données en intégrant les nouvelles observations
tout en excluant les plus anciennes. Un nouveau modèle du processus est alors généré. L’autre
approche est une formulation récursive. Elle consiste à mettre à jour le modèle, en relation avec
un ensemble de données de plus en plus croissant puisque il inclut les nouveaux échantillons
mais sans écarter les anciens.
Dans le cadre de la surveillance des processus en temps réel, la complexité de calcul, et la
rapidité d’adaptation sont deux paramètres importants. Ils décrivent la vitesse de changement du
modèle à partir de l’apparition d’un nouvel événement. Intuitivement, les techniques récursives
offrent une meilleure efficacité en terme de calcul pour la mise à jour du modèle ACP. Elles
utilisent directement le modèle élaboré à l’instant précédent plutôt que de le reconstruire en
passant par l’ensemble des données, mis à jour, comme dans le cas de la MWPCA (Dayal and
MacGregor 1997c ; Li et al. 2000 ; Qin 1998). D’après Wang et al. 2005, l’ACP récursive peut
être difficile à mettre en pratique pour les deux raisons suivantes :
54

Analyse en Composantes Principales Adaptative (APCA)
1. l’ensemble de données avec lesquelles le modèle est mis à jour, est toujours croissant ; Cela
conduit à une réduction de la vitesse d’adaptation du modèle qui est fonction de la taille
de données.
2. le modèle actuel comprend des données plus anciennes qui deviennent de plus en plus
non représentatives de l’état actuel du processus.
Comparativement, les techniques de l’ACP basées sur une fenêtre glissante (MWPCA) peuvent
surmonter certains des problèmes cités ci-dessus. Ils incluent seulement, un nombre suffisant de
points de données dans la fenêtre temporelle à partir de laquelle le modèle adaptatif est re-
construit. Plus précisément, la MWPCA permet aux échantillons de mesure les plus âgés d’être
écartés en faveur des échantillons les plus récents et les plus représentatifs du fonctionnement
actuel du processus. Par contre, l’utilisation d’un nombre constant d’échantillons dans la fenêtre
conduit à une vitesse constante d’adaptation du modèle. Cela peut engendrer un problème si
la fenêtre doit couvrir un grand nombre de points de données afin d’inclure une information
suffisante sur le fonctionnement du processus. En effet, le mécanisme d’adaptation devient plus
lourd , et la vitesse de calcul chute de manière significative. De plus, si la fenêtre est de petite
taille, les données en son sein ne peuvent pas représenter correctement les corrélations existant
entre les variables de processus.
Sur cette base et afin d’améliorer l’efficacité de calcul sans compromettre la taille de la
fenêtre glissante, un nouvel algorithme plus rapide, de la méthode ACP adaptative est proposé
par Wang et al. (2005). Cette nouvelle technique repose principalement sur la combinaison de
la méthode ACP récursive (RPCA) et la méthode ACP à base de fenêtre glissante (MWPCA) afin
de mettre en valeur les conditions de la surveillance en temps réel et surmonter les problèmes
précités de chacune des deux techniques classiques de l’ACP adaptative. En fait, la combinaison
de la technique récursive avec celle de la fenêtre glissante s’est avérée bénéfique pour réduire la
complexité de calcul. L’idée de cette nouvelle technique montre comment dériver une adaptation
efficace de la matrice de corrélation R tout en intégrant une étape de mise à jour (updating
stage), comme dans l’ACP récursive, et éliminer la contribution de l’échantillon le plus ancien
(downdating stage), comme dans la MWPCA.
La combinaison de ces deux techniques en même temps est l’intérêt principal de cette nou-
velle approche, appelée Fast Moving Window (FMWPCA). La procédure d’adaptation du modèle
ACP dans cet algorithme est composée de deux étapes, comme l’illustre la figure 2.6. Au fur et à
mesure de l’arrivée des nouvelles données, et avant que le modèle ne soit mis à jour, l’extraction
ou l’élimination de l’information la plus ancienne de l’historique de données est exécutée. En
fait, le modèle ACP est recalculé en relation avec les informations les plus à jour de l’historique
des données limité, par la taille de la fenêtre. Les trois matrices de la figure 2.6 représentent, le
processus de mis à jour (updating) et d’élimination (downdating), caractérisé par une fenêtre
55

Analyse en Composantes Principales Adaptative (APCA)
glissante de l’instant précédent, de taille L (matrice I), par l’étape d’élimination de l’ancien
échantillon (matrice II), et l’étape de mise à jour de l’historique de données (matrice III). Cette
dernière est représentée par la fenêtre de l’instant en cours, produite par l’ajout du nouvel échan-
tillon à la matrice (II). Les paramètres qui caractérisent la dynamique du processus (moyenne,
écarts-types et matrice de corrélation) de la matrice (II) et la matrice (III) sont calculées à partir
des trois (03) étapes suivantes.
FIGURE 2.6 – Les deux étapes d’adaptation pour construire une nouvelle fenêtre de données.
Etape 01 : Matrice I vers la Matrice II
Selon Wang et al. (2005), l’effet d’éliminer ou d’écarter l’échantillon de mesure le plus ancien
x0k de la matrice I, sur la moyenne et la variance de chaque variable de processus et sur la matrice
de corrélation, peut être estimé de manière récursive. La formulation récursive de ces paramètres
dans cette étape (downdating stage) est alors comme suit,
b =1
L− 1(Lbk − x
k) (2.77)
∆b = bk − b (2.78)
σ2(i) =L− 1
L− 2(σk(i))
2 − L− 1
L− 2
(∆b(i)
)2
− [x0k(i) − bk(i)]
2
L− 2(2.79)
Σ = diag σ(1), . . . , σ(m) (2.80)
Une fois que les paramètres de normalisation sont calculés, un nouvel échantillon normalisé
(centré/réduit) est défini ainsi,
xk = Σ−1k
(x0
k − bk
)(2.81)
Enfin, l’impact de l’élimination récursive de l’ancien échantillon x(k) à partir de la matrice
de corrélation Rk est le résultat des équations ci-dessus. Pour plus de simplicité, une matrice R∗
56

Analyse en Composantes Principales Adaptative (APCA)
est introduite afin de calculer la matrice de corrélation R.
R∗ =L− 2
L− 1Σ−1
k ΣRΣΣ−1k (2.82)
ce qui peut être encore divisée en
R∗ = Rk − Σ−1k ∆b∆bΣ−1
k − 1
L− 1xkxT
k (2.83)
La récursivité afin de mettre à jour et éliminer l’échantillon le plus ancien de la matrice de
corrélation de l’instant précédent R, Matrice II, est exprimée en Eq. 2.84.
R =L− 1
L− 2Σ−1ΣkR∗ΣkΣ
−1 (2.84)
Etape 02 : Matrice II vers la Matrice III
Cette étape concerne la mise à jour du modèle ACP en incorporant le nouvel échantillon de
mesure en utilisant la méthode récursive. En se basant sur cette formulation de l’ACP récursive
pour la mise à jour des différents paramètres de normalisation, le vecteur moyenne mis à jour
est donc donné comme suit,
bk+1 =1
L
[(L− 1) b + x
k+L
](2.85)
Le changement dans les vecteurs moyennes est calculé comme suit :
∆bk+1 = bk+1 − b (2.86)
Ainsi, l’écart-type de la ime variable est donné avec la formulation suivante :
σ2ik+1 =
L− 2
L− 1σ2
i + (∆bik+1)2 − 1
L− 1
[xik+L − bik+1
]2 (2.87)
avec,
Σk+1 = diag σ1k+1, . . . , σmk+1 (2.88)
Enfin, la mise à l’échelle (normalisation) de l’échantillon de mesure le plus récent, xk+L, ainsi
que la mise à jour de la matrice de corrélation, sont décrits respectivement dans les équations
qui suivent.
xk+L = Σ−1k+1
(x
k+L − bk+1
)(2.89)
Rk+1 =L− 2
L− 1Σ−1
k+1ΣRΣΣ−1k+1 + Σ−1
k+1∆bk+1∆bTk+1Σ
−1k+1 +
1
L− 1xk+LxT
k+L (2.90)
57

Analyse en Composantes Principales Adaptative (APCA)
Etape 03 : Combinaison des étapes 1 et 2
Les étapes 1 et 2 peuvent être combinées pour dériver directement la matrice III à partir de
la matrice I, i.e l’élimination de l’ancienne information (downdating), comme dans (Eq. 2.77),
et la mise à jour de la nouvelle information, comme dans (Eq. 2.85). L’adaptation du vecteur
moyenne donne directement :
bk+1 = bk +1
L
(x
k+L − xk
)(2.91)
L’adaptation de l’écart-type découle de la combinaison des équations (2.79) et (2.87)
σ2ik+1 = σ2
ik + ∆b2ik+1 − ∆b2i +1
L
[xik+L − bik+1
]2 − 1
L[xik − bik]
2 (2.92)
En remplaçant les équations 2.83 et 2.84 dans l’équation 2.90, on obtient une formulation
récursive pour mettre à jour la matrice de corrélation de la matrice III. Cette formulation est
donnée comme suit :
Rk+1 = Σ−1k+1ΣkR∗ΣkΣ
−1k+1 + Σ−1
k+1∆bk+1∆bTk+1Σ
−1k+1 +
1
L− 1xk+LxT
k+L (2.93)
Enfin, pour cette approche, on peut conclure que le mécanisme d’adaptation des différents
paramètres du modèle ACP (moyenne, écart type, matrice de corrélation) est constitué de deux
phases développées en même temps. La première inclut la nouvelle information dans le modèle
(updating), et la seconde permet l’élimination des données les plus anciennes (downdating).
La formulation récursive de tous les paramètres définissant le modèle ACP, montre que la mise
à jour est réalisée en relation avec la nouvelle information ainsi que le modèle de l’instant
précédent. Habituellement, le modèle calculé à l’instant précédent implique tout l’historique de
données disponibles sur le fonctionnement du processus. L’intérêt de cette nouvelle technique,
Fast MWPCA, consiste, à chaque fois qu’une nouvelle mesure est disponible, au calcul du modèle
de l’instant précédent mais en relation seulement avec une partie limitée de l’historique de
données. Cette partie est définie par la taille de la fenêtre glissante utilisée dans cet algorithme.
Finalement, la récursivité améliore la vitesse du mécanisme d’adaptation alors que la fenêtre
glissante met à jour la partie réduite de l’historique de données.
2.4.5 L’ACP Incrémentale (IPCA)
La vitesse du mécanisme d’adaptation du modèle ACP en relation avec un nouvel événement
observé sur le fonctionnement du système, est une propriété très intéressante, mais qui n’est pas
beaucoup abordée par la communauté des chercheurs. Cette propriété se traduit par le nombre
58

Analyse en Composantes Principales Adaptative (APCA)
d’opérations et le temps nécessaire pour que l’algorithme de surveillance offre à chaque instant
une information sur l’état courant du processus. Elle est caractérisée par l’ordre de calcul, où la
complexité de calcul du modèle ACP, est notée O(·). C’est l’objet de cette section.
A chaque nouvelle mesure disponible sur le fonctionnement du processus et après la mise
à jour de la matrice de covariance, les valeurs et les vecteurs propres sont recalculés afin d’ob-
tenir une nouvelle représentation ACP. Le calcul est de l’ordre de O(m2) pour la matrice de
covariance ou de corrélation, et peut aller jusqu’à O(m3) pour sa décomposition en valeurs et
vecteurs propres. Comme dans les cas pratiques, le nombre de variables à surveiller est assez
grand, l’ACP peut se révéler prohibitive en termes de temps de calcul, pour modéliser en temps
réel cette grande quantité de données. Il en est de même de la décomposition en valeurs et
vecteurs propres de la matrice de covariance. En fait, la procédure d’adaptation nécessite trop
d’espace mémoire et prend beaucoup de temps, alors que les algorithmes d’apprentissage en
temps réel, qui travaillent sur la décomposition répétée en valeur propre (EVD) ou la décom-
position en valeur singulière (SVD), doivent être en mesure de mettre à jour la structure du
modèle rapidement. Les travaux de Elshenawy et al. (2009), Hu et al. (2013) proposent deux
algorithmes de l’ACP récursive, qui permettraient de réduire considérablement le coût de cal-
cul. Le premier algorithme est basé sur la technique d’analyse en premier ordre de perturbation
(First-order Perturbation, FOP), et il consiste à mettre à jour en rang un (rank-one) les valeurs
et leurs vecteurs propres correspondant à la matrice de covariance de l’échantillon de mesure
disponible. Le second algorithme est basé sur la méthode de projection de données (Data Pro-
jection method, DPM). C’est une approche simple et fiable pour le pistage, i.e. le "traking" des
sous-espaces adaptatifs.
Afin d’adapter la décomposition en valeurs et vecteurs propres de la matrice de corrélation
en relation avec les mesures nouvellement disponibles tout en respectant un ordre de calcul
réduit, une nouvelle technique récursive-incrémentale est proposée dans ce chapitre. La plupart
des techniques analytiques en lien avec le problème de la décomposition en valeurs/vecteurs
propres nécessitent un calcul intensif et ne sont donc pas les mieux adaptés pour des appli-
cations en temps réel. D’autres modèles sur une base neuronale ont aussi été proposés pour
résoudre ce problème, dont le principal initiateur a été Erkki Oja en 1982 (Oja, 1982). Il a pro-
posé un modèle de neurones à une seule sortie qui permet d’extraire la plus grande composante
principale d’un ensemble de données. Par suite, plusieurs modèles ont été développés afin d’ex-
traire l’ensemble des autres composantes principales. Citons notamment l’algorithme de Hebb
généralisé (GHA) développé par Sanger en 1989 (Sanger, 1989), qui consiste à trouver direc-
tement les vrais vecteurs propres des données disponibles, sans la nécessité d’estimer et/ou de
stocker la matrice de covariance ou de corrélation R. Ceci permet de réduire la complexité de
calcul du modèle ACP à un ordre linéaire O(m). Cette propriété rend l’algorithme GHA parti-
culièrement mieux adapté à la surveillance des systèmes variant dans le temps. Chakour et al.
59

Analyse en Composantes Principales Adaptative (APCA)
(2014) ont présenté une nouvelle technique de l’ACP adaptative qui est à la base de l’algorithme
GHA. Contrairement aux algorithmes existants de l’ACP adaptative, celui qui est proposé se ré-
fère à un paradigme où, à chaque nouvelle observation, le modèle ACP est mis à jour seulement
en relation avec cette dernière et sans avoir à ré-explorer toutes les données précédemment
disponibles. En effet, la procédure d’élimination des anciennes informations (comme est le cas
de la technique Fast MWPCA) à partir du modèle à chaque instant (down-dating step) n’est pas
nécessaire.
A) Algorithme de Oja et Sanger (GHA)
Le problème majeur des techniques classiques de l’ACP adaptative réside dans la complexité
de calcul du modèle ainsi que dans l’espace mémoire occupé. Leur implémentation neuronale
constitue une alternative très intéressante, car elle permet d’estimer les directions principales
des données multidimensionnelles, ou modèle ACP, sans la nécessité de calculer ou de stocker
la matrice de covariance. En fait, on ne traite qu’un seul vecteur de mesure à la fois. Cette
méthode a déjà fait ses preuves dans la compression d’images et dans la classification. Dans
notre cas, nous l’avons adapté à la surveillance des procédés industriels variant dans le temps.
L’implémentation neuronale de l’ACP linéaire par les réseaux de Oja et Sanger sont constitués
de deux couches : une couche d’entrée et une couche de sortie. L’apprentissage au sein de ces
réseaux est non supervisée. Il est réalisé à l’aide de l’Algorithme Hebbien Généralisé (GHA). Ce
dernier a été proposé par Sanger (Sanger et al. 1989) en se basant sur la règle d’apprentissage
de Oja (Oja et al. 1982). Le premier vecteur propre, principal , est estimé par la règle récursive
d’Oja suivante :
p(k + 1) = p(k) + η(k)[y(k)x(k)T − p(k)y(k)2
], (2.94)
= p(k) + ∆p(k) (2.95)
où η est le pas d’apprentissage, et k est le nombre d’itérations de l’algorithme. Ainsi,
y(k) = p(k)T x(k), (2.96)
Les deux premiers termes de la règle d’Oja correspondent à la loi de Hebb Donald, qui posait
un problème majeur d’instabilité. Le module de p a tendance à croitre sans cesse, et conduit ainsi
à une divergence de la règle. C’est pourquoi , Oja a introduit une modification consistant en le
rajout d’un dernier terme qui assure la normalisation du vecteur p. Il a été démontré que cette
règle est stable, et fait converger les poids vers la première composante principale des données
avec une norme unitaire (Oja and Karhunen 1985, Haykin 1994).
60

Analyse en Composantes Principales Adaptative (APCA)
L’Algorithme Hebbien Généralisé est un des premiers modèles neuronaux , développé dans
la littérature afin d’avoir une estimation simultanée de multiples directions principales aboutis-
sant à une analyse en composantes principales au sens large. L’architecture de réseau adoptée,
comporte m neurones linéaires connectés en parallèle sur le flux de données d’entrée. Les m
sorties du réseau identifient, en fin d’apprentissage, les m composantes principales. En effet, la
sortie yi du ieme neurone est décrite par l’équation linéaire suivante :
yi = pTi x, (2.97)
où x est le vecteur d’entrée, et pi est un vecteur de poids (synaptic weight) du ieme neurone, qui
représente le ieme vecteur principal. La règle suivante, dite règle de Sanger, ou encore algorithme
de Hebb généralisé, est une généralisation de la règle de Oja. En effet, pour obtenir le modèle
du premier neurone, ou le premier vecteur propre, GHA suit exactement la même formulation
décrite précédemment par Oja :
∆p1(k) = η(k)[y1(k)x(k)T − y1(k)
2p1(k)], (2.98)
Pour le cas des autres neurones (2, 3, . . ., m), la règle de Sanger est légèrement modifiée :
∆pi(k) = η(k)
[yi(k)x(k)T − yi(k)
i∑l=1
yl(k)pl(k)
](2.99)
= η(k)
[yi(k)
(x(k)T −
i−1∑l=1
yl(k)pl(k)
)− yi(k)
2pi(k)
](2.100)
Si nous définissons le vecteur suivant,
x(i) = x −i−1∑l=1
ylpl, (2.101)
L’algorithme GHA prend la forme de la règle de Oja sur x(i) :
∆pi(k) = η(k)[yi(k)x
(i)(k) − yi(k)2pi(k)
], (2.102)
où,
yi = pTi x(i). (2.103)
La règle d’apprentissage (2.102) désigne l’algorithme de Hebb généralisé. L’algorithme GHA
est basé sur une transformation, appelée déflation (deflation transform). Elle est implémentée
dans l’équation (2.101). Cette transformation consiste à supprimer à chaque fois l’effet des neu-
rones précédents sur le neurone actuel i. Elle est une étape clé dans le processus d’extraction
61

Analyse en Composantes Principales Adaptative (APCA)
des composantes 2, 3, etc. Elle fait donc le même travail que celui de l’ACP classique présentée
précédemment.
Le fait de soustraire les plus grandes variances, associées aux directions principales déjà
extraites, n’accélère pas l’apprentissage des vecteurs principaux suivants, puisque l’algorithme
GHA possède un pas d’apprentissage η constant. La convergence peut être améliorée, sous cer-
taines conditions liées au choix de la valeur du pas. La valeur de ce paramètre ne doit pas être
constante, mais décroître avec le temps. A cet effet, Darken et al. (2007) proposent un pas
d’apprentissage adaptatif pour l’algorithme de Hebb généralisé linéaire. Il est représenté selon
l’expression suivante :
η(k) =η0
1 + k/τ(2.104)
où k est le nombre d’itérations et η0 est un paramètre libre. Le paramètre de réglage τ détermine
la durée de l’étape de recherche, avec ηt ≈ η0 lorsque (k ≪ τ), avant l’étape de convergence où
ηk diminue selon η0/k (lorsque k ≫ τ). Généralement, le choix du paramètre de réglage τ et η0
dépend de l’application.
L’algorithme de Hebb détermine seulement les vecteurs propres des données, mais pas les va-
leurs propres correspondantes. Elles sont alors estimées comme suit :
λi =1m
m∑k=1
yi(k)2 (2.105)
Cette estimation des valeurs propres n’est pas toujours adaptée à l’apprentissage en ligne (Schrau-
dolph et al., 2007).
B) Adaptation de la décomposition en valeurs/vecteurs propres
Les caractéristiques variables dans le temps, des procédés industriels dynamiques, com-
prennent : des changements dans la moyenne, des changements de la variance, et des chan-
gements dans la structure de corrélation entre les variables (Li et al. 2000). Une adaptation au
cours du temps de tous ces paramètres, définissant le changement naturel dans le fonctionne-
ment du processus, est nécessaire.
Dans l’algorithme de l’ACP classique et la règle de Oja ou GHA, les données à traiter sont
supposées centrées, i.e. de moyenne nulle. C’est pourquoi, une phase de prétraitement est né-
cessaire. En effet, à chaque nouvel échantillon de mesure, ce dernier est mis à l’échelle avant
traitement. La formulation récursive que nous avons adapté et adopté, est celle proposée dans
62

Analyse en Composantes Principales Adaptative (APCA)
Li et al. (2000), de l’ACP récursive (voir section (2.4.3)).
bk+1 = αkbk + (1 − αk) xk+1 (2.106)
σ2k+1 = βk
(σ2
k + ∆b2k+1
)+ (1 − βk) ∥xk+1 − bk+1∥2 (2.107)
Toute nouvelle observation du processus, disponible devra être incluse dans le modèle. En
effet, les valeurs et les vecteurs propres de la matrice de covariance, ou de corrélation récem-
ment mis à jour, sont calculées afin d’obtenir une nouvelle représentation ACP. D’après Choi et
al. (2006), la décomposition récursive de la matrice de corrélation est donnée par l’équation
suivante :
Rk+1 ≃ βkRk + (1 − βk)Rnew (2.108)
On peut écrire aussi l’équation (2.108) avec la représentation suivante,
Pk+1Λk+1PTk+1 ≃ βkPkΛkP
Tk + (1 − βk)PnewΛnewPT
new (2.109)
avec, Rnew = xTk+1xk+1, et βk est un facteur d’oubli variable. À partir de cette expression, tout en
respectant le dilemme (stabilité-plasticité), le mécanisme d’adaptation des vecteurs et valeurs
propres de la matrice de corrélation Rk+1 peut être donné par :
Pik+1 ≃ βkPi
k + (1 − βk)Pinew (2.110)
λik+1 ≃ 1
m
m∑k=1
yi(k)2 (2.111)
avec yi = Pik+1xk+1. Tandis que, Pi
new est le ieme vecteur propre de l’échantillon de mesure dis-
ponible dans l’instant k+ 1, calculé par l’algorithme de Hebb généralisé. Ainsi, Pik est le vecteur
propre calculé à l’instant précédent.
La quantité de pondération attribuée à chaque observation, dépend de la quantité de va-
riation dans la dynamique du système, celle-ci est observée sur les mesures xk+1. Afin de tenir
compte de ces variations observées sur le fonctionnement du système, un nouveau facteur de
pondération adaptatif , est proposé pour l’équation (2.110). De même que le facteur d’oubli
proposé par Choi et al. 2006 (voir section (2.4.3)), la formulation du nouveau facteur de pon-
dération, proposé, dépend directement du changement survenu dans les structures internes du
modèle P. L’équation de ce dernier est donnée par :
βk = βmax − (βmax − βmin) [1 − exp −ϑ (∥Pk−1∥/∥Pnor∥)n] (2.112)
63

Analyse en Composantes Principales Adaptative (APCA)
où βmin et βmax sont la valeur minimale et la valeur maximale du facteur de pondération, res-
pectivement, ϑ, β, et n sont les paramètres de la fonction. Ainsi, ∥P∥ = ∥Pk − Pk−1∥ est la
norme euclidienne de la différence entre deux vecteurs propres consécutifs.
Un nombre important d’approches ont été proposées pour recalculer et/ou adapter, à chaque
instant de mesure, les valeurs et vecteurs propres. Il convient de noter que la complexité de cal-
cul, ou l’ordre de calcul du modèle ACP à chaque instant en se basant sur la technique MWPCA
est de O(Lm2). Par contre, pour le cas de la technique récursive et la MWPCA rapide est seule-
ment de O(m2). Par conséquent, l’approche proposée dans la présente section diminue la com-
plexité de calcul de O(m2) à un ordre linéaire de O(m). Les différentes méthodes qui consistent
à mettre à jour la décomposition en valeurs et vecteurs propres des matrices symétriques définies
positives, matrice de covariance, ont été étudiées au cours des dernières décennies. L’efficacité
de calcul de ces méthodes peut être évaluée par le nombre d’opérations consommées. Le Tableau
(2.1) montre une comparaison en termes de complexité de calcul entre les méthodes les plus
couramment proposées pour adapter de manière récursive la matrice de covariance (Kruger and
Xie, 2012) :
Méthodes d’adaptations Coût de calcul
Standar SVD (Bunch et al. 1978) O(m3)
Inverse iteration (Golub and Van Loan 1996) O(m3)
Lanczos approach (Paige 1980 ; Parlett 1980) O(m2lk)
First order perturbation, FOP (Champagne 1994) O(m2)
Projection-based (Hall et al. 1998) O(m3)
Data projection method (Doukopoulos 2008) O(ml2k)
GHA algorithm (Oja 1982 ; Sanger 1989) O(lkm)
TABLE 2.1 – Efficacité des méthodes d’adaptation.
Ici, le paramètre m est le nombre de variables à surveiller, et lk est le nombre du PCs rete-
nus dans le modèle ACP à chaque instant de mise à jour. Ce Tableau démontre que l’algorithme
de Hebb généralisé est le plus économique en terme de côut de calcul par rapport aux autres
méthodes précitées. Il convient de noter que la méthode de projection des données (data projec-
tion), ainsi que la technique de Oja et Sanger permettent seulement la mise à jour des vecteurs
propres mais pas les valeurs propres dans le même mécanisme d’adaptation. L’algorithme pro-
posé n’a pas besoin de calculer et de re-décomposer la matrice de covariance à chaque instant
de mesure. Cela implique une réduction significative de la complexité de calcul. Enfin, et afin de
64

Conclusion
déterminer le nombre d’opérations consommées (flops), ou l’ordre de complexité de calcul pour
chaque algorithme, il faut noter que (Kruger and Xie, 2012) :
1. l’addition et la multiplication de deux valeurs nécessite une flop, O(1).
2. le nombre de flops pour le produit de deux vecteurs ainsi le produit de deux matrices est
d’un ordre O(m2).
3. les opérations de mise à l’échelle des vecteurs, sont de O(m).
2.5 Conclusion
Dans ce chapitre, nous avons présenté le principe de base de la modélisation des systèmes in-
dustriels en utilisant la méthode d’analyse en composantes principales linéaires. Les différentes
démarches à suivre pour avoir un modèle ACP statique adéquat sont présentées. L’identifica-
tion du modèle ACP nécessite la détermination du nombre de composantes principales (PCs).
Plusieurs approches sont utilisées dans la littérature pour identifier le nombre optimal de com-
posantes principales à retenir dans le modèle ACP. Le critère de sélection du nombre de compo-
santes basé sur le principe de reconstruction est très intéressant pour des objectifs de diagnostic,
car ce principe permet l’exploitation de la redondance qui existe entre les différentes variables
étudiées.
Néanmoins, la plupart des procédés industriels sont dynamiques, et ont souvent un compor-
tement variable dans le temps. L’utilisation de la méthode ACP statique engendre une repré-
sentation incomplète sur l’état du système. De ce fait, une autre alternative à la méthode ACP
statique a été présentée. Elle permet de surmonter les limitations ainsi que les problèmes posés
par la méthode statique. Il s’agit de l’ACP dynamique qui est abordée dans une deuxième partie.
Les différentes approches de l’ACP adaptative ont été détaillées. Le challenge majeur de ces tech-
niques est de surpasser la complexité de calcul, élevée. À cet effet, une nouvelle approche est
proposée comme étant une alternative qui permet l’adaptation à ce problème. L’intérêt donné à
la méthode ACP linéaire et son extension dans le cas dynamique a été explicité pour la modéli-
sation et la surveillance des processus industriels dans ce chapitre.
Le chapitre suivant, est considéré comme une extension de ce chapitre dans le cas non li-
néaire. L’analyse en composante principale non linéaire statique et dynamique seront présentées,
et particulièrement, l’analyse en composante principale non linéaire à noyau, ou kernel PCA.
65

Chapitre 3Analyse en composantes principales non
linéaire à noyau (Kernel PCA)
Sommaire3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
3.2 Principe de l’ACP non linéaire . . . . . . . . . . . . . . . . . . . . . . 68
3.3 ACP non linéaire à noyau (kernel PCA) . . . . . . . . . . . . . . . . 72
3.3.1 Principe de la méthode ACP à noyau . . . . . . . . . . . . . . . . . . . 72
3.3.2 L’astuce du noyau (kernel trick) . . . . . . . . . . . . . . . . . . . . . . 73
3.3.3 Les fonctions noyaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
3.3.4 Modèle ACP à noyau (KPCA) . . . . . . . . . . . . . . . . . . . . . . . 79
3.3.5 Centrage des données dans l’espace à noyau . . . . . . . . . . . . . . . 81
3.4 Reconstruction de données (Problème de Pré-image) . . . . . . . . . 82
3.5 ACP à noyau adaptative (Adaptive KPCA, AKPCA) . . . . . . . . 85
3.5.1 ACP à noyau à base de fenêtre glissante (MWKPCA) . . . . . . . . . . 87
3.5.2 ACP à noyau récursive (RKPCA) . . . . . . . . . . . . . . . . . . . . . 89
3.5.3 ACP à noyau neuronale (NKPCA) . . . . . . . . . . . . . . . . . . . . . 95
3.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
3.1 Introduction
L’ACP est une technique de projection orthogonale linéaire qui projette les observations mul-
tidimensionnelles représentées dans un espace de dimensionm sur un sous-espace de dimension
inférieure l, (l < m), tout en maximisant la variance des projections. Le but principal de la trans-
formation est d’étudier les relations qui existent entre l’ensemble de données. Elle permet l’iden-
tification d’une structure de dépendance entre les observations multi-variables afin d’obtenir une
66

Introduction
description compacte de l’information. En fait, l’ACP linéaire est un outil de modélisation des
relations linéaires entre un ensemble de variables représentant le comportement d’un processus
étudié, où seules les dépendances linéaires ou quasi-linéaires entre les variables peuvent être ré-
vélées. Du fait que la plupart des processus réels sont dynamiques et non linéaires, l’application
de l’ACP classique n’est pas adaptée.
Afin de contourner cette difficulté, plusieurs méthodes d’analyse en composantes principales
non linéaires (ACPNL) ont été proposées. Plusieurs auteurs y ont contribué, on peut citer Has-
tie et al. (1989), Kramer et al. (1991), Tan S. et Mayrovouniotis (1995), et Schökopf et al.
(1998). Hastie en 1989, propose une approche pour une généralisation de l’ACP dans le cas non
linéaire basée sur le principe des courbes principales. Cette courbe lisse minimise la distance
entre tous les points de données et leurs projections sur cette même courbe. Toutefois, cette
approche est non paramétrique (pas de modèle de représentation) et ne peut être utilisée pour
la surveillance. Ainsi, elle ne permet de calculer que les composantes principales non linéaires
unidimensionnelles. Kramer en 1991, a proposé une analyse en composantes principales non
linéaires (ACPNL) en utilisant un réseau de neurones à cinq couches dont les poids sont calculés
par apprentissage et en minimisant l’erreur quadratique entre les entrées et les sorties du réseau.
D’autres auteurs ont proposés d’effectuer une transformation des observations du système à
l’aide d’une fonction non linéaire issue d’un développement polynomial, puis l’ACP est appliquée
sur ces données transformées. Schökopf en 1998 a proposé une nouvelle approche basée sur
une transformation non linéaire des observations. Cette transformation permet la projection des
données, initialement non linéaires, vers un autre espace où les relations entre les nouvelles
données sont linéaires. Il propose d’introduire des fonctions appelées fonctions noyaux définies
par un produit scalaire des observations transformées. Cette méthode, appelée ACP à noyaux
(Kernel PCA), peut donc être considérée comme une généralisation de l’ACP linéaire. En effet,
cette technique a déjà fait ses preuves dans plusieurs domaines d’application, notamment dans
la modélisation et le diagnostic des procédés industriels (Lee et al., 2004 ; Choi et al., 2005).
Comme toute méthode statique d’analyse des données, la représentation fournie par l’ACP à
noyau est incomplète et n’est pas précise lorsque le comportement des systèmes étudiés est de
nature dynamique. Similairement au cas linéaire, ce problème peut être résolu à travers une mise
à jour continue de tous les paramètres définissant la dynamique du système. Il apparait ainsi
nécessaire de rechercher pour les cas qui nous intéressent, une version adaptative du modèle
non linéaire, qui tienne compte de cette dynamique. Dans la littérature consultée, peu de travaux
traitent de l’analyse en composantes principales à noyau, récursive, pour la surveillance et le
diagnostic des processus non linéaires dynamiques (Kruger et al. 2009 ; Ben Khediri et al. 2011).
Dans ce chapitre nous présentons la généralisation de l’ACP linéaire au cas non linéaire. Dans
un premier temps, le principe de base de l’analyse en composantes principales non linéaires, est
introduit. Ensuite, l’identification du modèle ACP à noyau, est détaillée. L’extention de cette
67

Principe de l’ACP non linéaire
approche vers le cas dynamique est exposée. Dans ce contexte deux nouvelles approches de
l’ACP à noyau adaptative sont proposées.
3.2 Principe de l’ACP non linéaire
Chercher à comprendre des données, c’est souvent chercher à trouver de l’information ca-
chée dans un gros volume de mesures redondantes. En effet, C’est chercher des dépendances,
linéaires ou non, entre les variables observées pour pouvoir résumer ces dernières par un petit
nombre de paramètres. La méthode classique, l’Analyse en Composantes Principales (ACP), est
abondamment employée dans ce but. Malheureusement, il s’agit d’une méthode exclusivement
linéaire, qui est donc incapable de révéler les dépendances non linéaires entre les variables. Pour
ce cas, une extension de cette dernière dans le cas non linéaire est nécessaire afin d’avoir une
possibilité d’identifier ou d’extraire à la fois les relations, ou les dépendances, linéaires et non
linéaires (voir la Figure 3.1).
FIGURE 3.1 – La méthode ACP
Pour mieux comprendre le problème et pouvoir faire le lien avec le cas linéaire, la Figure 3.2
représente le principe général d’un modèle ACP, quelque soit le modèle linéaire ou non linéaire.
Le modèle global est composé de deux sous-modèles, l’un de compression qui consiste à projeter
des données de dimension m vers l’espace des composantes principales de dimension l, et l’autre
effectue l’opération inverse, à savoir une projection de ℜl vers ℜm.
Dans le cas linéaire, les deux sous-modèles sont donnés par les deux matrices orthogonales
des vecteurs propres de la matrice de corrélation des données : P et P−1 = P T . Le modèle
global est donné par la matrice de projection définie par C = P P T .
Dans le cas non linéaire, le but est de chercher deux fonctions non linéaires F et G. G repré-
sente le modèle non linéaire de compression qui permet de calculer les composantes principales
non linéaires à partir des données. F représente le modèle non linéaire de décompression. Ce
dernier permet l’estimation des variables originelles à partir des composantes principales non
linéaires données par le modèle de compression. Dans ce cas, la matrice de données X peut être
68

Principe de l’ACP non linéaire
Demapping model
X ∈ ℜN×m
ℓ
X ∈ ℜN×m
Mapping model
m
T ∈ ℜN×ℓ
ℓm
FIGURE 3.2 – Principe de la modélisation par l’analyse en composantes principales.
représentée par une estimation X, plus une erreur d’estimation E :
X = X + E = F(T ) + E (3.1)
où T = [t1, t2, .., tl] ∈ ℜN×l est la matrice des composantes principales non linéaires qui est
donnée par :
T = G(X) (3.2)
A partir de cette équation le modèle non linéaire (ACPNL) est représenté par la fonction
F (G (·)), et l’estimation de X, notée X, est donnée par l’équation suivante :
X = F(G(X)) (3.3)
Pour ce cas, et afin de permettre l’exploration de la structure non linéaire des données,
plusieurs approches utilisent l’extraction des composantes principales non linéaires. Dans un
premier temps Hastie et al. (1989) ont proposé une approche pour l’ACP non linéaire basée
sur la méthode des courbes principales. Une courbe principale est une courbe lisse qui passe au
milieu du nuage de point de données de dimension m tout en minimisant la déviation orthogo-
nale entre les deux (i.e. les données et la courbe). Elle fournit un résumé unidimensionnel non
linéaire de ces données (voir la Figure 3.3). Elle est définie comme une courbe auto-consistante,
où la propriété d’auto-consistance peut s’interpréter par le fait que chaque point de la courbe
F est la moyenne de tous les points qui sont projetés sur elle. Généralement, sa forme est dé-
terminée par la structure des données, et elle est paramétrée par sa longueur d’arc, c’est-à-dire
que chaque point sur la courbe peut être décrit par sa distance le long de la courbe à partir de
l’origine. Si l’on utilise une fonction non linéaire F pour exprimer cette courbe, cette fonction est
analogue au vecteur propre p dans le cas linéaire. Et les distances de projection de données sur
cette courbe sont analogues aux composantes principales t. L’inconvénient majeur des courbes
principales est qu’elles ne donnent pas un modèle de représentation des composantes princi-
69
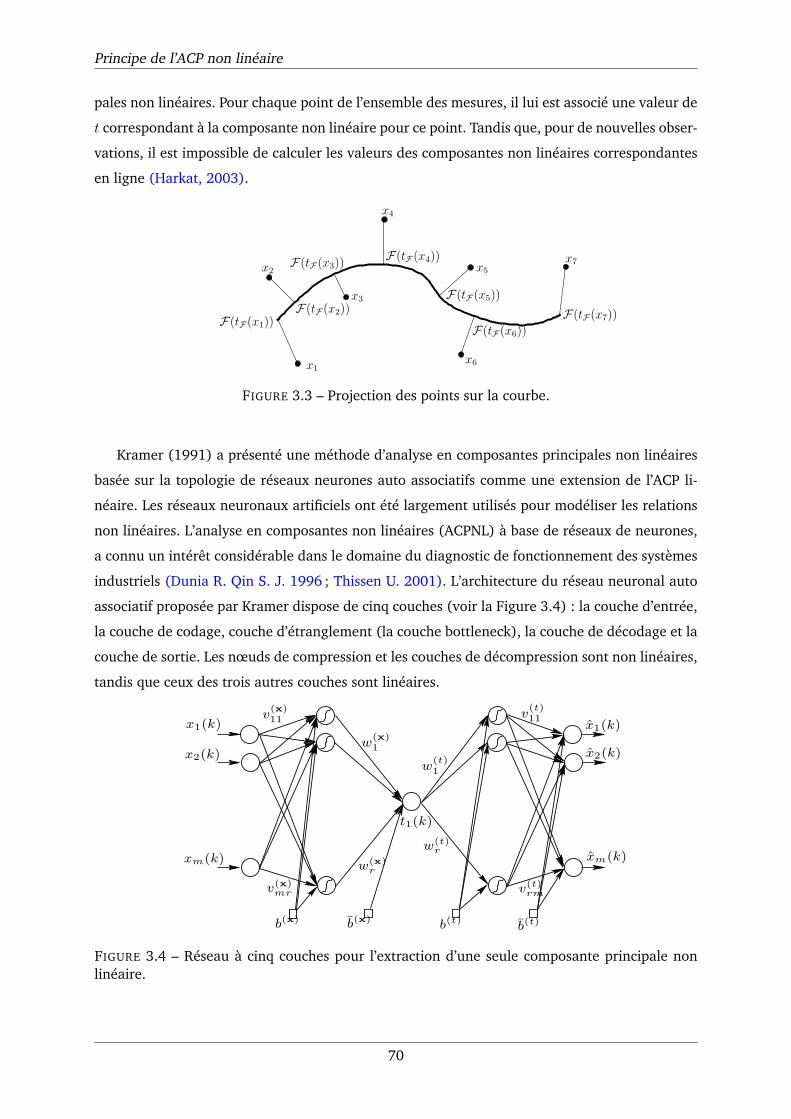
Principe de l’ACP non linéaire
pales non linéaires. Pour chaque point de l’ensemble des mesures, il lui est associé une valeur de
t correspondant à la composante non linéaire pour ce point. Tandis que, pour de nouvelles obser-
vations, il est impossible de calculer les valeurs des composantes non linéaires correspondantes
en ligne (Harkat, 2003).
x1
x3
x2
F(tF(x1))F(tF(x2))
F(tF(x3))
F(tF(x5))
x6
x7
x4
F(tF(x4))x5
F(tF(x6))
F(tF(x7))
FIGURE 3.3 – Projection des points sur la courbe.
Kramer (1991) a présenté une méthode d’analyse en composantes principales non linéaires
basée sur la topologie de réseaux neurones auto associatifs comme une extension de l’ACP li-
néaire. Les réseaux neuronaux artificiels ont été largement utilisés pour modéliser les relations
non linéaires. L’analyse en composantes non linéaires (ACPNL) à base de réseaux de neurones,
a connu un intérêt considérable dans le domaine du diagnostic de fonctionnement des systèmes
industriels (Dunia R. Qin S. J. 1996 ; Thissen U. 2001). L’architecture du réseau neuronal auto
associatif proposée par Kramer dispose de cinq couches (voir la Figure 3.4) : la couche d’entrée,
la couche de codage, couche d’étranglement (la couche bottleneck), la couche de décodage et la
couche de sortie. Les nœuds de compression et les couches de décompression sont non linéaires,
tandis que ceux des trois autres couches sont linéaires.
xm(k)
x1(k)
x2(k)
xm(k)
t1(k)
v(x)11
v(x)mr
w(x)r
w(t)r
w(x)1
w(t)1
b(x) b(x)b(t)
v(t)rm
v(t)11
b(t)
x1(k)
x2(k)
FIGURE 3.4 – Réseau à cinq couches pour l’extraction d’une seule composante principale nonlinéaire.
70

Principe de l’ACP non linéaire
Pour effectuer l’ACPNL, le réseau de neurones (Fig. 3.4) contient trois couches entre les
variables d’entrée et de sortie. Une fonction de transfert G1 réalise une projection du vecteur
x, vecteur d’entrée de dimension m, vers la première couche cachée (couche de codage). La
deuxième fonction de transfert G2 projette les données de la première couche cachée vers la
couche d’étranglement, bottleneck layer, contenant un seul neurone, la sortie de cette dernière
représente les composantes principales non linéaires t. La fonction de transfert G1 est généra-
lement non linéaire, tandis que la fonction G2 représente la fonction identitée (G(x) = x). En
effet, il faut noter que l’extraction des composantes principales peut se faire de deux façons.
La première consiste à extraire les composantes séquentiellement, dont un seul neurone dans
la couche du milieu, bottleneck, est utilisé (ACPNL séquentielle). Une fois que l’estimation des
données à partir de cette première composante non linéaire est effectuée, on doit soustraire le
résultat obtenu de l’ensemble des données, et une opération d’extraction d’une deuxième com-
posante non linéaire est effectuée sur les résidus obtenus etc. La seconde consiste à extraire les l
composantes désirées simultanément en insérant au départ l neurones dans la couche du milieu
(ACPNL parallèle ou simultanée). Ensuite, une fonction de transfert G3, qui est une fonction
non linéaire, projette les données à partir de t vers la deuxième couche cachée (couche de dé-
codage). La dernière fonction de transfert G4 est la fonction identité, qui consiste à projeter les
données à partir de la deuxième couche de décodage vers la couche de sortie x, vecteur de sortie
de dimension m. La fonction coût utilisée pour entraîner ce réseau de neurones est :
e =n∑
j=1
m∑i=1
(xi − xi)2j (3.4)
où xi est l’observation désirée de l’ensemble de données x, et xi est la sortie réelle du réseau.
L’avantage principal des réseaux neuronaux, c’est que nous n’avons pas besoin de connais-
sance antérieure sur les relations sous-jacentes entre les données. Néanmoins, un nombre de li-
mitations peut être soulevé. Tout d’abord, la phase d’apprentissage du réseau de neurone à cinq
couches est une tâche ardue. Ensuite, il peut être difficile de déterminer le nombre de nœuds
dans la couche de codage, la couche de décodage, et la couche d’étranglement. Généralement,
on fait appel à plusieurs algorithmes d’optimisation permettant de construire itérativement la
couche cachée, comme on en trouve par exemple pour la méthode de validation croisée.
Dans le même contexte, Dong et McAvoy (1996) proposent une procédure pour l’identifica-
tion du modèle ACP non linéaire en combinant la méthode des courbes principales avec celle
des réseaux de neurones auto-associatifs. Une nouvelle technique de l’ACP non linéaire, très
prometteuse est apparue. Elle a été développée par Schölkopf en 1998 et est basée sur l’astuce
noyau. Sa description fera l’objet de la section suivante.
71

ACP non linéaire à noyau (kernel PCA)
3.3 ACP non linéaire à noyau (kernel PCA)
L’intérêt porté à l’ACP pour résoudre des problèmes d’apprentissage a été récemment relancé
par l’obtention d’une version non-linéaire de cette méthode. L’ACP à noyau (Kernel PCA) permet
d’exploiter des relations potentiellement non linéaires entre les variables. Elle a attiré l’attention
des chercheurs, par sa capacité d’extraire la corrélation non linéaire entre les variables sans
aucun appel à une procédure d’optimisation, comme c’est le cas de l’ACP basée sur les réseaux
de neurones. Cette approche consiste à projeter les observations dans un nouvel espace de plus
grande dimension et de procéder par la suite à une ACP ordinaire sur l’image des observations
obtenues dans cette espace.
Cette technique est basée sur une transformation non linéaire des données via des fonc-
tions habituellement non linéaires, appelées fonctions noyaux. Cette transformation effectue un
changement de base qui permet de projeter les données de l’espace d’entrée dans un nouvel
espace où les relations entre les variables sont linéaires. La modélisation est ainsi facilitée, par
l’application de l’ACP linéaire, puisque on passe d’un système initialement non linéaire, à un
autre linéaire. L’espace de la représentation obtenu est de dimension plus grande que l’espace
de départ. L’ACP à noyau présente un formalisme mathématique intéressant, où elle s’appuie sur
l’algèbre linéaire. En effet, cette dernière peut être donc considérée comme une généralisation
naturelle de l’ACP linéaire.
L’ACP à noyau fournit seulement un modèle qui permet de calculer les composantes prin-
cipales non linéaire, mais ne fournit aucune technique d’estimation des données dans l’espace
initial. Autrement dit, aucune notion n’est introduite sur la fonction réciproque, ou la transfor-
mation non linéaire inverse, permettant de revenir de l’espace transformé à l’espace des obser-
vations. Cette difficulté est appelée le problème de l’estimation de la pré-image. Il consiste à
trouver une observation dont l’image, par la fonction noyau considérée, soit la plus proche pos-
sible de l’élément en question dans l’espace transformé. Cependant, la transformation inverse
est souvent complexe. La résolution de ce problème, dit de pré-image, permet d’étendre le prin-
cipe de la reconstruction, comme en ACP linéaire, pour reconstruire une partie du vecteur de
données afin de générer des résidus structurés utiles, pouvant être appliquées à la localisation
de défauts.
3.3.1 Principe de la méthode ACP à noyau
L’analyse en composantes principales à noyau (ACP-à-noyau), constitue une extension non-
linéaire de l’ACP à des espaces de représentation induits par des fonctions noyaux . Mieux que
l’ACP classique, l’information extraite est liée non-linéairement aux données d’entrée. Comparée
à d’autres extensions non-linéaires de l’ACP, par exemple les réseaux de neurones, elle bénéficie
d’une stabilité et d’un coût calculatoire réduit. L’idée est de projeter les données dans un espace
72

ACP non linéaire à noyau (kernel PCA)
de plus grande dimension de sorte que la variété devienne linéaire et d’effectuer l’ACP dans ce
nouvel espace obtenu. On notera la projection par :
ϕ : ℜm 7→ H (3.5)
où H est appelé l’espace des caractéristiques (Feature space). Le nouvel espace H est de très
grande dimension de sorte à pouvoir contenir plusieurs interactions différentes entre les va-
riables.
L’ACP à noyau correspond à une ACP linéaire dans H (voir la figure (3.5)). Considérons
un ensemble de mesures sur un système en bon fonctionnement, de n observations x1, . . . , xn
dans un espace donné ℜ de dimension m. On suppose que ces observations sont centrées dans
ℜ. En fait, l’ACP vise à rechercher des espaces de projection pertinents pour les données en
maximisant leur variance projetée. Les composantes de faible variance sont associées à du bruit,
et écartées de fait. On cherche alors des composantes principales dans un espace transformé,
lié par une relation non-linéaire à l’espace des données. On considère donc une transformation
ϕ : xi 7→ ϕ(xi) de ℜ vers l’espace transformé H. Et on suppose que les images ϕ(x1), . . . , ϕ(xn)
sont centrées à l’origine de H, c’est-à-dire∑n
i=1 ϕ(xi) = 0. L’ACP à noyau agit donc sur les ϕ(xi)
de la même façon que l’ACP linéaire agissait sur les xi.
FIGURE 3.5 – L’idée de base de l’ACP à noyau
3.3.2 L’astuce du noyau (kernel trick)
L’astuce du noyau est une technique qui consiste à utiliser une méthode linéaire pour ré-
soudre un problème non-linéaire, en transformant l’espace de représentation des données d’en-
trées en un espace de plus grande dimension (appelé aussi espace de re-description), où la
méthode linéaire est alors utilisée.
Les méthodes à noyaux permettent de trouver des fonctions de décision non linéaires, tout
73

ACP non linéaire à noyau (kernel PCA)
en s’appuyant fondamentalement sur des méthodes linéaires. Une fonction noyau correspond à
un produit scalaire dans un espace de re-description des données. Dans cet espace, qu’il n’est pas
nécessaire de manipuler explicitement, les méthodes linéaires peuvent être mises en œuvre pour
y trouver des régularités linéaires, correspondant à des régularités non linéaires dans l’espace
d’origine. Par conséquent, les fonctions noyaux permettent d’utiliser des techniques simples,
rigoureuses et traiter des problèmes non linéaires. C’est pourquoi ces méthodes sont devenues
très populaires récemment.
L’astuce du noyau s’utilise dans un algorithme qui ne dépend que du produit scalaire entre
deux vecteurs d’entrée xi et xj . Après le passage à un espace de re-description par une transfor-
mation ϕ, l’algorithme n’est plus dépendant que du produit scalaire :
⟨ϕ(xi), ϕ(xj)⟩ (3.6)
Le problème de ce produit scalaire est qu’il est effectué dans un espace de grande dimension,
ce qui conduit à des calculs impraticables. L’idée est donc de remplacer ce calcul par une fonction
noyau telle que :
k(xi, xj) = ⟨ϕ(xi), ϕ(xj)⟩, (3.7)
L’astuce du noyau consiste donc à remplacer un produit scalaire dans un espace de grande
dimension par une fonction noyau, facile à calculer. Un autre avantage des fonctions noyaux
est qu’il n’est pas nécessaire d’expliciter la transformation ϕ. Sur le plan théorique, la fonction
noyau définit un espace hilbertien, dit auto-reproduisant et isométrique par la transformation
non linéaire de l’espace initial et dans lequel est résolu le problème linéaire. En fait, elle fournit
un moyen de représenter les observations implicitement dans un espace de re-description.
Pour réaliser cela, et afin qu’une fonction ϕ représente un produit scalaire dans l’espace de
re-description H, elle doit satisfaire à un certain nombre de conditions. En d’autres termes, l’idée
principale réside dans l’interprétation d’un noyau défini positif comme un produit scalaire dans
un espace de re-description. Ainsi, un tel noyau assure-t-il le passage des données de l’espace des
observations à l’espace dit de Hilbert, sans la nécessité d’exhiber la fonction de transformation
non-linéaire associée (Khallas, 2012).
Corollaire. (Astuce du Noyau).
Tout noyau défini positif, k, induisant un espace de Hilbert H définit le produit scalaire dans cet
espace, comme suit :
k(xi, xj) = ⟨ϕ(xi), ϕ(xj)⟩H, (3.8)
pour chaque xi, xj dans X.
Definition 3.3.1. (Espace de Hilbert).
74

ACP non linéaire à noyau (kernel PCA)
Un espace vectoriel H muni d’un produit scalaire ⟨·, ·⟩, est un espace de Hilbert. De plus, un
espace de Hilbert est complet. Un espace métrique M est dit complet si toute suite de Cauchy de
M a une limite, convergente, dans M.
Plusieurs théorèmes permettent de caractériser les fonctions noyau sans passer explicitement
par l’espace de redescription. Le théorème de Mercer, montre qu’étant donné une fonction noyau
continue, symétrique, semi-définie positive k(xi, xj), elle peut s’exprimer comme un produit
scalaire dans un espace de grande dimension.
Definition 3.3.2. (Noyau semi défini positif).
Un noyau k est dit semi défini positif sur X si et seulement si, il vérifie
n∑i=1
n∑j=1
αiαjk(xi, xj) ≥ 0 (3.9)
pour tout n ∈ N, x1, . . ., xn ∈ X et α1, . . ., αn ∈ R.
Le théorème de Mercer, fournit des conditions pour qu’une fonction symétrique k : X ×
X → ℜ soit une fonction noyau. Il permet en outre d’identifier une décomposition spectrale des
fonctions noyau, c-à-d, permet d’exprimer les fonctions noyau en termes de valeurs propres et
de fonctions propres.
Theorème 3.3.1. (Théorème de Mercer).
Si k(·, ·) est une fonction noyau continue symétrique d’un opérateur intégral
g(y) = Af(y) =
∫ b
a
k(xi, xj)f(y)dy + h(x) (3.10)
vérifiant : ∫X×X
k(xi, xj)f(xi)f(xj)d(xi)d(xj) ≥ 0. (3.11)
pour toute fonction f ∈ L2(X) (de carré sommable) (X étant un sous-espace compact de Rd), alors
la fonction k(xi, xj) peut être développée en une série uniformément convergente en fonction des
valeurs propres positives λi et des fonctions propres ψi :
k(xi, xj) =N∑
k=1
λkψk(xi)ψk(xj) (3.12)
où N est le nombre de valeurs propres positives (nombre éventuellement infini).
On peut alors décrire la fonction ϕ(x) de redescription des entrées comme :
ϕ(x) =(√
λ1ψ1(x),√λ2ψ2(x), . . .
)(3.13)
75

ACP non linéaire à noyau (kernel PCA)
Le théorème de Mercer (3.3.1), fournit donc une description explicite de l’espace de redes-
cription par une base de fonctions analysantes orthogonales.
3.3.3 Les fonctions noyaux
L’astuce du noyau permet d’employer toutes les méthodes linéaires afin de découvrir des
relations non-linéaires dans les données. Au fil des années récentes ont été ainsi revisitées l’ana-
lyse en composantes principales (ACP), les méthodes linéaires de clustering, la discrimination
linéaire de Fisher, etc. Les démarches à suivre dans cette technique sont résumées comme suit :
1. Les données décrites dans l’espace d’entrée sont projetées dans un espace vectoriel de
redescription H ;
2. Des régularités linéaires sont cherchées dans cet espace H ;
3. Les algorithmes de recherche n’ont pas besoin de connaître les coordonnées des projections
des données dans H, mais seulement leurs produits scalaires ;
4. Ces produits scalaires peuvent être calculés efficacement grâce à l’utilisation des fonctions
noyaux.
Dans cette approche, il est crucial de faire savoir que l’essentiel des informations contenues
dans les données d’entrée X, s’exprime dans une matrice noyau K, appelée aussi matrice de
Gram. Celle-ci encode les produits scalaires entre les projections des données d’apprentissage.
Definition 3.3.3. (Matrice de Gram).
La matrice de Gram du noyau k(·, ·) pour les observations x1, . . . , xi, . . . , xn (pour tout
entier n fini) est la matrice carrée K de taille n et de terme général Kij = k(xi, xj).
La matrice de Gram est symétrique, elle contient toute information extraite sur les données
en utilisant des noyaux. Un noyau est une fonction qui associe à tout couple d’observations
(xi, xj) une mesure de leur influence réciproque calculée à travers leur corrélation ou leur dis-
tance. La fonction noyau est donc une mesure non-linéaire de la similarité entre les observations.
Elles peuvent être considérées comme une généralisation des fonctions de covariance.
La traduction ou l’interprétation des données est obtenue, grâce à l’examen des caracté-
ristiques de la matrice noyau (voir la Figure (3.6)). En fait, s’il existe une structure dans les
données, elle doit se refléter dans la matrice de Gram. La fonction noyau choisie est appropriée
pour détecter les similarités sous-jacentes entre ces données. Cette fonction noyau agit de fait
comme un filtre sensible à certaines fréquences et pas à d’autres. Il semble donc essentiel de
contrôler le choix de la fonction noyau afin d’éviter le risque de sous-apprentissage (espace de
fonctions trop pauvre) ou de sur-apprentissage (espace de fonctions trop riche). Le choix d’une
fonction noyau est lié à des raisons diverses. Il correspond implicitement par exemple au choix :
1. d’une mesure de similarité entre éléments de l’espace d’entrée X.
76
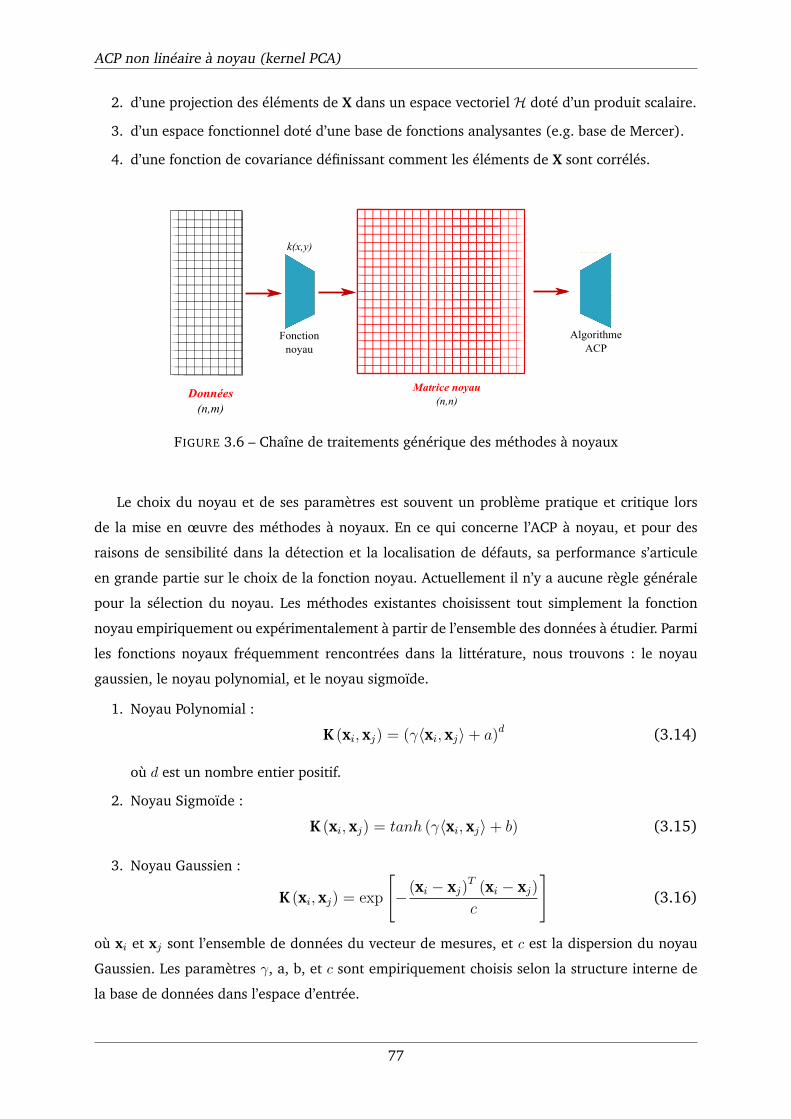
ACP non linéaire à noyau (kernel PCA)
2. d’une projection des éléments de X dans un espace vectoriel H doté d’un produit scalaire.
3. d’un espace fonctionnel doté d’une base de fonctions analysantes (e.g. base de Mercer).
4. d’une fonction de covariance définissant comment les éléments de X sont corrélés.
FIGURE 3.6 – Chaîne de traitements générique des méthodes à noyaux
Le choix du noyau et de ses paramètres est souvent un problème pratique et critique lors
de la mise en œuvre des méthodes à noyaux. En ce qui concerne l’ACP à noyau, et pour des
raisons de sensibilité dans la détection et la localisation de défauts, sa performance s’articule
en grande partie sur le choix de la fonction noyau. Actuellement il n’y a aucune règle générale
pour la sélection du noyau. Les méthodes existantes choisissent tout simplement la fonction
noyau empiriquement ou expérimentalement à partir de l’ensemble des données à étudier. Parmi
les fonctions noyaux fréquemment rencontrées dans la littérature, nous trouvons : le noyau
gaussien, le noyau polynomial, et le noyau sigmoïde.
1. Noyau Polynomial :
K (xi, xj) = (γ⟨xi, xj⟩ + a)d (3.14)
où d est un nombre entier positif.
2. Noyau Sigmoïde :
K (xi, xj) = tanh (γ⟨xi, xj⟩ + b) (3.15)
3. Noyau Gaussien :
K (xi, xj) = exp
[−(xi − xj)
T (xi − xj)
c
](3.16)
où xi et xj sont l’ensemble de données du vecteur de mesures, et c est la dispersion du noyau
Gaussien. Les paramètres γ, a, b, et c sont empiriquement choisis selon la structure interne de
la base de données dans l’espace d’entrée.
77

ACP non linéaire à noyau (kernel PCA)
Le noyau polynomiale et le noyau gaussien, satisfont toujours le théorème de Mercer, alors
que le noyau sigmoïde satisfait ce théorème seulement pour certaines valeurs des paramètres de
la fonction noyau. De plus, il n’est pas pratique d’avoir des fonctions noyaux standards adaptées
à tous les ensembles de données. Apparemment, ce problème peut se résoudre en utilisant les
techniques d’optimisation (Shao et al. 2009 ; Jia et al. 2012). Il est souhaitable alors, que les
méthodes à noyaux utilisent des fonctions noyaux optimisées qui s’adaptent bien à des don-
nées d’entrées spécifiques. L’utilisation d’un noyau optimisé, peut effectivement servir à mieux
capturer la variation dans les données d’entrée. Ces dernières sont alors plus précisément modé-
lisées. Une bonne représentation des données (modèle adéquat) a un impact significatif direct
sur l’amélioration de la sensibilité dans la procédure de détection et de localisation de défauts
par la méthode ACP à noyau. Pour le moment, beaucoup moins d’effort a été consacré à l’ap-
prentissage de la fonction noyau pour arriver à une meilleure représentation des données. Shao
et al. (2009), proposent une technique d’apprentissage des fonctions noyaux pour la méthode
ACP, KPCA, afin de les adapter à des données spécifiques et explorer leurs potentiels pour des
raisons de surveillance de processus. Elle s’articule autour de la méthode, maximum variance
unfolding (MVU, Weinberger et al. , 2004). En fait, la fonction noyau optimale cherche une
représentation qui maximise la variance tout en préservant les distances entre points voisins,
dont la structure non linéaire dans les données d’entrée est dépliée dans l’espace de caractéris-
tiques, ou de re-description, et devient plus susceptible d’être linéaire (Shao et al. 2009). Jia et
al. (2012) développent une autre stratégie d’optimisation basée sur les algorithmes génétiques
pour choisir le type et les paramètres appropriés de la fonction noyau à utiliser.
D’après la littérature, la fonction gaussienne est la fonction noyau la plus utilisée. Elle donne
presque toujours une erreur quadratique moyenne (MSE) inférieure dans la phase d’apprentis-
sage par rapport aux autres fonctions et permet une bonne capacité de généralisation. De ce
fait, la fonction du noyau Gaussien est celle qui est utilisée dans ce travail afin de construire un
modèle ACP à noyau, représentant le bon fonctionnement du système à surveiller.
L’ajustement de la valeur du paramètre de la fonction noyau c, peut affecter les performances
de la détection et le diagnostic de défauts. En effet, une petite valeur de ce paramètre rendrait
l’argument de l’exponentielle vraiment grand, ce qui rend la valeur de la fonction de noyau très
faible ou proche de 0. Dans le cas contraire, une très grande valeur de c rendrait la valeur de la
fonction noyau très proche de 1. Plusieurs auteurs ont contribués dans le réglage du paramètre
c (Alcala, 2011). La valeur du paramètre c de la fonction noyau gaussienne peut être fixée en
se basant sur la méthode de Park et Park, (2005), qui propose de sélectionner la valeur de
c = Const∗Averd, où Averd est la distance moyenne entre toutes les observations dans l’espace
des fonctions, et Const est une valeur prédéterminée.
78

ACP non linéaire à noyau (kernel PCA)
3.3.4 Modèle ACP à noyau (KPCA)
Dans les méthode à noyau, les noyaux peuvent être considérés comme une mesure de simi-
larité non-linéaire. Soit un ensemble non-vide X et un noyau positif k, des données de mesure
qui représentent le fonctionnement non linéaire du système x1, x2, ..., xn ∈ X, définissant un
sous-espace de ℜm. Dans le cas de l’ACP linéaire, le modèle est obtenu par une décomposi-
tion en valeurs et vecteurs propres de la matrice de covariance de l’historique de données X.
Comme cette dernière n’identifie que les structures linéaires, une technique plus générale a été
mise en place pour apprendre les non-linéarités en utilisant les noyaux, appelée ACP-à-noyaux.
Les données X sont (implicitement) transformées dans un espace fonctionnel appelé espace
de caractéristique (feature space), où l’ACP classique est appliquée. Soit Φ la transformation
non-linéaire de l’espace des observations X à l’espace fonctionnel H qui, à chaque xi lui fait
correspondre son image ϕ(xi). En effet, l’ACP à noyau calcule les composantes principales non
linéaires des données transformées ϕ(x1), ϕ(x2), ..., ϕ(xn). Bien que les vecteurs propres ré-
sultant soient obtenus par une technique linéaire dans l’espace H, ils décrivent des relations
non-linéaires dans l’espace des observations.
En supposant que les vecteurs de mesure dans l’espace de caractéristique (feature space)
sont mises à l’échelle (centrées), i.e. moyenne nulle. L’algorithme de l’ACP est reformulé donc
en termes de produit scalaire des données dans l’espace des caractéristiques. Les données d’ap-
prentissage sont alors disposées comme X = [Φ1,Φ2, ...,Φn]T . En fait, la matrice de covariance
dans l’espace des caractéristiques est S, donnée par la formulation suivante :
(n− 1)S = X TX =n∑
i=1
ΦiΦTi (3.17)
Pour diagonaliser la matrice S, on cherche les valeurs propres λ ≥ 0 et les vecteurs propres
correspondant v satisfaisant l’équation :
X TX v =n∑
i=1
ΦiΦTi v = λv (3.18)
Notons que toute solution de (3.18) s’inscrit dans un sous-espace engendré par les images
ϕ(xi). La solution v, vecteur propre de la matrice X TX , peut être représentée par :
v =n∑
i=1
αiϕ(xi) (3.19)
Remarquez que Φi n’est pas explicitement définie, ni ΦTj . L’astuce dite noyau pré-multiplie
l’équation (3.18) par X :
XX TX v = λX v (3.20)
79

ACP non linéaire à noyau (kernel PCA)
On définit alors K, comme :
K = XX T =
ΦT
1 Φ1 . . . ΦT1 Φn
... . . . ...
ΦTnΦ1 . . . ΦT
nΦn
=
k(x1, x1) . . . k(x1, xn)
... . . . ...
k(xn, x1) . . . k(xn, xn)
(3.21)
Si on note :
α = X v (3.22)
Alors, on obtient :
Kα = λα (3.23)
L’équation (3.18) montre que α et λ sont les valeurs et les vecteurs propres de la matrice K.
Afin de trouver v de l’équation (3.22), nous la pré-multiplions par X et nous utilisons l’équation
(3.20),
X Tα = X TX v = λv (3.24)
ce qui montre que v est donné par :
v = λ−1X Tα (3.25)
Ainsi, pour calculer le modèle KPCA (λi et vi), nous réalisons d’abord une décomposition
en valeurs et vecteurs propres de l’équation (3.23) pour obtenir λi et αi, puis l’utilisation de
l’équation (3.25) pour calculer vi. Afin de garantir que vTi vi = 1, les équations (3.22) et (3.18)
sont utilisées pour tirer :
αTi αi = vT
i X TX vi = vTi λivi = λi (3.26)
Donc, αi necessite d’être normalisé par√λi. Soit α
i le vecteur propre unitaire normalisé
correspondant à λi,
αi =√λiα
i (3.27)
La matrice avec les l premiers vecteurs propres constituant l’espace principal dans F (feature
space) sont notés comme suit :
Pf = [v1 v2 . . . vl] (3.28)
80

ACP non linéaire à noyau (kernel PCA)
A partir de l’équation (3.25), Pf est en relation avec l’espace de mesure en tant que
Pf =[
1λ1
X Tα1 . . .1λlX Tαl
](3.29)
=[X Tα
1λ− 1
21 . . .X Tα
l λ− 1
2l
](3.30)
= X T PΛ− 12 (3.31)
avec P = [α1 . . . α
l ] et Λ = diag λ1, . . . λl sont les l premières vecteurs et valeurs propres de
la matrice K, correspondant aux plus grandes valeurs propres.
Pour une mesure donnée x et son vecteur associé dans l’espace des caractéristique Φ = ϕ(x),
les composantes principales sont données par t = PfΦ. Ainsi à partir de l’équation (3.31), on
peut la ré-écrire comme suit :
t = Λ− 12P TXΦ (3.32)
= Λ− 12P T k(x) (3.33)
où
k(x) = XΦ = [Φ1 Φ2 . . . Φn]T Φ (3.34)
=[ΦT
1 Φ ΦT2 Φ . . . ΦT
nΦ]T
(3.35)
= [k(x1, x) k(x2, x) . . . k(xn, x)]T (3.36)
3.3.5 Centrage des données dans l’espace à noyau
Comme dans le cas linéaire de la méthode ACP, les mesures ou l’historique de données
nécessitent d’être normalisés avant qu’ils ne soient utilisés pour établir le modèle ACP. Si le
centrage dans l’espace des observations est aisé, ce n’est pas le cas dans l’espace fonctionnel H.
Le calcul de la matrice de covariance dans l’équation (3.17) est pris en compte si le vecteur Φ
dans l’espace des caractéristiques dispose d’une moyenne nulle. Si ce n’est pas le cas, les vecteurs
associés ϕ(x) dans l’espace des caractéristiques nécessitent d’être mis à l’échelle à moyenne nulle.
Pour ce faire, le vecteur normalisé ϕ(x) est donné comme suit,
Φ = Φ − 1
n
n∑i=1
Φi = Φ − [Φ1 Φ2 . . . Φn] 1n (3.37)
où 1n est un vecteur de n dimension, dont les éléments sont1n
. En fait, la fonction noyau de
mise à l’échelle de deux vecteurs Φi et Φj est
81

Reconstruction de données (Problème de Pré-image)
k(xi,xj) = ¯ΦiT Φi (3.38)
= k(xi, xj) − k(xi)T 1n − k(xj)T 1n . . . + 1Tn K1n (3.39)
De même, la mise à l’échelle du vecteur de noyau k(x) est
k(x) =[Φ1 Φ2 . . . Φn
]T Φ (3.40)
= F [k(x) − K1n] (3.41)
Avec
F = I - E (3.42)
Dans cette équation, I est la matrice identité, pour E = 1n1Tn est une matrice de taille n×n dont
les elements sont1n
. Une propriété de F est qu’elle est idempotente,
Fn = F (3.43)
Enfin, la mise à l’échelle de la matrice noyau, K, est calculée comme suit :
K =[Φ1 Φ2 . . . Φn
]T [Φ1 Φ2 . . . Φn
](3.44)
= F K F (3.45)
3.4 Reconstruction de données (Problème de Pré-image)
Dans le cas classique de l’ACP linéaire, il est facile de déterminer la reconstruction du vecteur
de mesure x dans l’espace d’entrée ℜm, à partir de la composante principale t de l’espace des
caractéristiques ACP ℜl (l < m). La reconstruction de données (la transformation inverse) se
fait alors entre deux fonctions (one to one), de l’espace de caractéristiques vers l’espace d’entrée
directement. Etant donné que t est le vecteur de caractéristique, ou le vecteur des composantes
principales, et l est le nombre de composantes principales à retenir dans le modèle ACP (P ), le
vecteur de mesure x reconstruit dans l’espace d’entrée est donné comme suit :
x = tP T (3.46)
Habituellement, la reconstruction des observations x dans un espace d’entrée à partir d’un
espace de caractéristiques est connu comme le problème de pré-image. En effet, la précision
dans la reconstruction est donnée par la distance euclidienne au carré (erreur quadratique)
entre la mesure et sa reconstruction dans l’espace d’entrée :
82

Reconstruction de données (Problème de Pré-image)
d2 (x, x) = ∥x − x∥2 (3.47)
Dans ce cas linéaire de la méthode ACP, l’erreur de reconstruction globale de tout l’historique
de données d’apprentissage est garanti tout simplement d’être minimale, lorsque le nombre de
composantes principales, choisi dans le modèle ACP est optimale.
La reconstruction, ou le problème de pré-image n’est pas aussi simple dans l’ACP à noyau.
Les méthodes à noyaux permettent la transformation non linéaire d’un espace des observations,
x(k), à un espace des caractéristiques H, où une nouvelle représentation des données ϕ(x) est
obtenue. L’ACP linéaire est de nouveau appliquée sur les images ϕ(x) afin d’avoir un vecteur
caractéristique t défini dans un espace orthonormée Γ appelé espace de caractéristique KPCA.
En effet, le principe de la reconstruction de l’ACP linéaire indiqué ci-dessus est donc valable pour
la reconstruction des images ϕ(x) associées à l’espace des caractéristiques H, à partir de l’espace
de KPCA. Elle ne peut, malheureusement pas, être appliquée directement pour reconstruire
l’échantillon de mesure x dans l’espace d’entrée d’origine à partir de l’espace de caractéristiques
KPCA.
Le retour inverse de l’espace des caractéristiques H à l’espace des observations, espace d’en-
trée, est le problème de la pré-image (comme dans le cas linéaire). Il faut se rappeler que l’espace
de caractéristiques est souvent de dimension plus grande que celle de l’espace des observations.
Ainsi, en raison des propriétés de l’espace de caractéristique H défini par certaines fonctions
noyaux, une solution exacte de la pré-image dans l’espace d’entrée risque de ne pas exister, et
si elle existe, elle pourrait de ne pas être unique (Mika et al. 1999). Pour résoudre ce problème,
il peut s’avérer nécessaire de déterminer un élément x de l’espace des observations tel que son
image ϕ(x) dans H, soit la plus proche possible de ϕ(x), avec ϕ(x) = Pϕ(x). En fait, le problème
de l’estimation de la pré-image consiste à trouver un point z ≡ x ∈ X tel que ϕ(z) = Pϕ(x). Il
s’agit alors de chercher plutôt l’équivalent dans l’espace des observations de la caractéristique
obtenue dans l’espace H (voir la figure (3.7)).
FIGURE 3.7 – Estimation de la pré-image.
83

Reconstruction de données (Problème de Pré-image)
La mesure reconstruite dans l’espace des caractéristiques H à partir de l’espace KPCA, est
définie avec la formulation suivante :
ϕ(x) = Pϕ(x) =l∑
i=1
1√λi
tipi (3.48)
Il s’agit donc de résoudre le problème d’optimisation, en cherchant un x∗ vérifiant,
z = min d2H
(ϕ(z), ϕ(x)
)= min ∥ϕ(z) − ϕ(x)∥2
H (3.49)
Minimiser le résultat ci-dessus ne signifie pas nécessairement que l’erreur de reconstruction
dans l’espace d’entrée est minimale. En outre, en raison du manque de l’unicité et/ou la pos-
sibilité de la non-existence de la pré-image, il n’existe pas de fonctions explicites permettant
directement de déterminer x à partir de ϕ(x), ou le vecteur caractéristique t. En développant
l’expression de la fonction coût dans (3.49) en termes de fonctions ou de matrices de noyaux,
elle pourrait être exprimée comme suit (Aldrich and Auret, 2013) :
d2H
(ϕ(z), Pϕ(x)
)= ∥ϕ(z)∥2 − 2ϕ(z) · Pϕ(x) + ∥Pϕ(x)∥2 (3.50)
= ϕ(z)ϕ(z) − 2ϕ(z)
l∑i=1
1√λiti
n∑j=1
αijϕ(xj)
+(
Pϕ(x))(
Pϕ(x))
= k(z, z) − 2l∑
i=1
n∑j=1
1√λitiα
ijϕ(z)ϕ(xj)
+
l∑i=1
n∑j=1
1√λitiα
ijϕ(xj)
·
(l∑
i=1
n∑k=1
1√λitiα
ikϕ(xk)
)
= k(z, z) − 2l∑
i=1
n∑j=1
1√λitiα
ijk(z, xj) +
l∑i=1
n∑j=1
n∑k=1
t2iαijα
ikϕ(xj)ϕ(xk)
= k(z, z) − 2l∑
i=1
n∑j=1
1√λitiα
ijk(z, xj) +
l∑i=1
n∑j=1
n∑k=1
t2iαijα
ikk(xj , xk)
= k(z, z) − 2l∑
i=1
βi
n∑j=1
αijk(z, xj) + Ω.
où, le troisième terme ne dépend pas de z, il est une constante représenter par Ω.
Ceci est défini généralement comme un problème d’optimisation non-linéaire et non-convexe,
à cause de la nature du noyau (Maya, 2012). Afin de revenir à l’espace initial et avoir une esti-
mation de la pré-image dans ce dernier, dont l’expression (3.50) est minimale, un grand nombre
de chercheurs se sont intéressés à ce problème et ont proposé des éléments de solution.
84

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
En se basant sur le gradient de la fonction coût (3.50) par rapport à z. Mika et al. (1999)
utilisent la technique itérative du point fixe pour trouver une solution approximative au pro-
blème de l’estimation de la pré-image. Elle est également sensible au choix des points initiaux
et nécessite un critère d’arrêt. Elle peut être instable et aboutit à des minimas locaux, et parfois
peut ne pas converger. Par la suite, Kwok et al. (2004) ont proposé de trouver directement les
pré-images par des contraintes de distance. L’idée consiste à déterminer une relation et faire un
lien entre les distances de l’espace H et les distances entre les données, de l’espace d’entrée.
Tout d’abord, dans l’espace des caractéristiques, elle consiste en la sélection de quelques points
parmi les plus proches voisins du vecteur caractéristique ϕ(x). Après, dans l’espace d’entrée,
calculer les distances entre la pré-image souhaitée et leur plus proches voisins correspondants.
La performance de la méthode de contrainte de distance dépend du nombre des plus proches
voisins choisis. Sachant que le nombre optimal des plus proches voisins n’est pas difficile à dé-
terminer, cette approche ouvre la porte à une gamme d’autres techniques qui se basent sur une
connaissance préalable sur les données d’apprentissage dans les deux espaces, tels que la mé-
thode d’apprentissage de variétés (manifold learning). Pour plus de détails sur le problème de
l’estimation de la pré-image, le lecteur est prié de se référer aux travaux de Mika et al. (1999) ;
Kwok et al. (2004) ; Bakir et al. (2004) ; Paul et al. (2011) ; Kallas (2012).
3.5 ACP à noyau adaptative (Adaptive KPCA, AKPCA)
L’environnement dans lequel nous vivons n’est pas immuable, il peut changer rapidement au
cours du temps. Il est donc important pour nous d’être en mesure de nous adapter continuelle-
ment à de nouvelles situations. Il en est de même pour le cas de la modélisation des systèmes
non stationnaires ou variables dans le temps. Ils nécessitent des procédures d’adaptation per-
mettant l’apprentissage continu de leurs nouvelles modalités de fonctionnement. Le problème
majeur qui cerne ces procédures d’adaptation est la manière d’apprendre au cours du temps,
défini par ce que l’on a appelé dilemme plasticité-stabilité (voir chapitre 02). En effet, il permet
une adaptation stable et optimale du modèle à l’arrivée de nouvelles observations.
Construire un modèle statistique adéquat peut-être une tâche plus compliquée pour les mé-
thodes d’analyse des données. Elle est souvent considérée comme un processus itératif, dont
un modèle est d’abord construit, testé et analysé puis réglé et rétabli. En fait, le processus de
construction d’un modèle peut être divisé en trois parties : la sélection de l’architecture du mo-
dèle, l’estimation des paramètres du modèle, et enfin le choix de la complexité du modèle (e.g.
cross-validation, afin d’estimer l’erreur de généralisation du modèle). Les trois étapes sont dé-
pendantes les unes des autres. Le processus de construction du modèle devient alors tout un
cycle. Cette tache devient de plus en plus compliquée lorsque les systèmes étudiés sont variables
dans le temps. Ce problème peut être contourné en ajustant d’un instant à l’autre l’architecture
85

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
ainsi que les paramètres du modèle initialement choisi.
La modélisation des processus non linéaires évoluant dans le temps à base de la méthode
ACP à noyau récursive, n’a pas encore été abordée de manière adéquate par la communauté des
chercheurs. Dans les méthodes récursives existantes, seules des méthodes linéaires ont été pro-
posées. La fonction du noyau est inconnue, et il est difficile de décrire la structure de données
non linéaire dynamique. En effet, à chaque instant de mesure où de nouvelles observations sont
disponibles, une mise à jour des paramètres définissant la dynamique non linéaire du système
est alors nécessaire. De même que pour le cas linéaire, l’ACP non linéaire à noyau à base de
fenêtre glissante, MWKPCA, a été proposée par Liu et al. (2009a). Le mécanisme d’adaptation
fonctionne de manière similaire à celle de l’ACP à base de fenêtre glissante rapide, Fast Moving
Window (Wang et al., 2005). La contribution de ce travail, comme dans le cas linéaire, consiste
en une mise à jour de la moyenne et de la matrice de covariance dans l’espace à noyau (Feature
space). En d’autre terme, elle présente comment l’adaptation du vecteur moyenne s’est intégrée
dans l’adaptation de la matrice de Gram. L’adaptation se fait en deux étapes. Tout d’abord, sup-
primer les échantillons les plus anciens (downdating), ensuite, on prend en compte la nouvelle
mesure (mise à jour). Liu et al. (2009a) fournissent également un algorithme numérique efficace
pour la décomposition en valeurs et vecteurs propres de la matrice noyau mise à jour, qui à son
tour, décrit le modèle KPCA adapté. Ils ont adopté la technique proposée par Hall et al. (2002,
2000) dans l’espace à noyau. A l’opposé des autres techniques d’adaptation, la méthode pro-
posée par Hall et al., (2002) ne nécessite pas une adaptation complète de la matrice de Gram.
Elle adapte seulement les l premières (l ≪ n) valeurs propres non nulles de la matrice de Gram
au lieu de tout l’ensemble des valeurs propres. Liu et al. (2009a) ont démontré que la version
étendue de cette technique dans le cas non linéaire est d’un ordre de complexité de O(n2).
La technique adoptée par Liu et al. (2009a) permet une adaptation des paramètres KPCA
sous une base continue, échantillon par échantillon. Néanmoins, dans de nombreuses situations
pratiques, les systèmes varient lentement, la mise à jour est alors nécessaire en fonction d’un
block de mesures. De plus, il est parfois intéressant de geler le modèle pour un certain temps
afin d’éliminer un certain nombre d’observations qui ne caractérisent pas les états de processus
(outliers). Lorsque un groupe de données doit être introduit dans le modèle, le coût de stockage
et de calcul de la matrice noyau peut être réduit. Ben Khediri et al. (2011) proposent une
nouvelle approche de l’ACP à noyau adaptative, à base d’une fenêtre glissante de taille variable,
permettant à la matrice noyau d’introduire et d’éliminer un block de données. L’idée de base
s’articule autour de la méthode adoptée par Hoegaerts et al. (2007). En effet, cette dernière
a introduit un algorithme rapide consistant en une adaptation de la matrice noyau, up- and
downdating, menée de manière séparée, sur une base continue (sample wise adaptation). Afin
de permettre une adaptation en discontinue (block wise), Ben Khediri et al. (2011) ont modifé et
étendu cette technique pour ce cas. Il est important aussi de noter que la mise à jour du vecteur
86

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
moyenne de l’ensemble de variables transformées à l’espace de caractéristique ϕ(x) n’est pas
prise en compte dans l’adaptation du modèle par la méthode de Hoegaerts et al. (2007). D’après
Liu et al. (2009a), cela peut réduire la sensibilité de détection de défauts et donc elle ne peut
pas modéliser adéquatement le comportement des processus non stationnaires.
En se basant sur les discussions précédentes, et afin d’incorporer la variation du vecteur
moyenne dans l’adaptation de la matrice de Gram, on applique les étapes d’adaptation (down-
and up-dating steps) en même temps, ainsi adapter la décomposition en valeurs/vecteurs propres
de la matrice de Gram avec un coût de calcul réduit, O(n), plus récemment, Li et al. (2015) pro-
posent un nouvel algorithme qui tient compte de tous ces points.
En ce qui concerne l’arrangement de la deuxième technique de l’ACP adaptative, l’ACP récur-
sive, dans le cas de l’ACP à noyau non linéaire, et contrairement à la méthode ACP adaptative
basée sur une fenêtre glissante, nous proposons Chakour et al. (2013 ; 2015a) une nouvelle
approche de l’ACP à noyau, adaptative. Elle permet une projection de la méthode ACP récur-
sive dans l’espace à noyau. Similairement au cas linéaire, la matrice de covariance dans l’espace
de caractéristiques ou la matrice noyau, est mise à jour à chaque instant de mesure. En effet,
l’adaptation comporte habituellement une pondération de l’information apprise précédemment
dans l’espace noyau en utilisant un facteur d’oubli tandis que la variation de la moyenne dans
l’espace des caractéristique est prise en compte. Dans le même contexte, nous avons introduit,
Chakour et al. (2015b), un nouvel algorithme de l’ACP à noyau récursive comme une troisième
contribution dans ce chapitre. Cet algorithme est considéré comme une extension dans le cas
non linéaire du premier algorithme proposé dans le chapitre 02, ACP neuronale. L’idée de base
est d’utiliser une ACP à noyau neuronal basé sur la version noyau de l’algorithme Hibbean géné-
ralisé (KHA). En utilisant l’algorithme proposé, les performances de surveillance sont améliorées
sur deux aspects ; adaptation rapide du modèle KPCA, et la réduction de la compléxité de calcul
et d’occupation de mémoire.
3.5.1 ACP à noyau à base de fenêtre glissante (MWKPCA)
Pour la technique de l’ACP à noyau basée sur une fenêtre glissante proposé par Liu et al.
(2009a), l’adaptation du modèle KPCA se fait en deux étapes similaires à celle du cas linéaire
de l’ACP à base de fenêtre glissante rapide, Fast MWPCA, discuté dans le chapitre 2. En effet, la
première étape se réfère également à la suppression de l’échantillon le plus ancien de la fenêtre
(down-dating), tandis que la deuxième étape consiste à ajouter l’échantillon nouvellement dis-
ponible, défini comme une mise à jour. La taille de la fenêtre glissante utilisée dans l’algorithme
est fixée à k ∈ N, ainsi que sont définis les matrices noyaux qui mémorisent les données trans-
formées dans l’espace de caractéristique de la fenêtre intermédiaire et la fenêtre nouvellement
mise à jour par Φ(X) et Φ(X), respectivement. En fait, l’adaptation de la moyenne et de la ma-
trice de covariance de l’ensemble de variables transformées, sur le plan conceptuel, s’appuie sur
87

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
la procédure suivante :
Φ(X) ⇒ Φ(X) ⇒ Φ(X)
avec, Φ(X) = [Φ(x2), . . . ,Φ(xk)], et Φ(X) = [Φ(x2), . . . ,Φ(xk+1)]. Ainsi, X = [x2, x3, . . . , xk],
X = [x2, x3, . . . , xk, xk+1] et Φ(xk+1) est l’échantillon nouvellement enregistré transformé en
l’espace de caractéristiques.
Comme le montre si bien l’équation (3.17), le modèle KPCA est construit à partir de la
matrice de covariance des données de processus transformées dans l’espace de caractéristiques.
Ainsi, son adaptation nécessite l’adaptation du vecteur moyenne, bϕ, et la matrice de covariance,
Rϕ, en suivant les deux étapes de la procédure précitée. Il convient de noter que le développe-
ment des algorithmes d’adaptation ou de mise à jour pour la moyenne, la matrice de covariance
et le modèle KPCA s’appuie principalement sur le premier décalage de la fenêtre glissante, qui
apparait lorsque le nouvel échantillon, xk+1, devient disponible.
Etape 01. Downdating (Φ(X) ⇒ Φ(X)) :
Le vecteur moyenne dans l’espace à noyau de la fenêtre intermédiaire, bΦ, peut être exprimé
par celle de l’ancienne fenêtre, bΦ, et l’élimination de l’impact de l’échantillon de mesure le plus
ancien, ϕ(x1) :
bΦ =k
k − 1bΦ − 1
k − 1ϕ(x1)
(3.51)
Intégrer l’équation (3.51) dans la définition de la matrice de covariance donne lieu à :
RΦ =k − 1
k − 2
[RΦ − k
(k − 1)2(ϕ(x1) − bΦ) (ϕ(x1) − bΦ)T
]. (3.52)
Etape 02. Updating (Φ(X) ⇒ Φ(X)) :
Le vecteur moyenne dans l’espace de caractéristiques de la nouvelle fenêtre, bϕ, peut être
calculée à partir du vecteur moyenne de la fenêtre intermédiaire, bϕ, plus les nouvelles obser-
vations, ϕ(xk+1) :
bϕ =k − 1
kbϕ +
1
kϕ(xk+1) (3.53)
En utilisant l’équation ci-dessus, la matrice de covariance des données transformées dans la
nouvelle fenêtre devient alors sous la formulation suivante :
88

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
RΦ = ϕ(X)ϕ(X)T (3.54)
=k − 2k − 1
RΦ +1k
(ϕ(xk+1) − bΦ
)(ϕ(xk+1) − bΦ
)T, (3.55)
où, ϕ(X) = ϕ(X)− 1k ϕ(X)Ek, avec Ek = 1k × 1T
k , est la matrice des observations ϕ(X), centrées,
i.e. de moyenne nulle dans l’espace de caractéristiques.
Etape 03. Principe de la fenêtre glissante (Φ(X) ⇒ Φ(X)) :
Combinant les étapes 1 et 2, le vecteur moyenne dans l’espace de caractéristiques de la
matrice de nouvelle fenêtre Φ(X) peut être calculé en utilisant la matrice de l’ancienne fenêtre,
bϕ, tout en supprimant la contribution de l’échantillon le plus ancien, ϕ(x1), et en ajoutant
l’impact des récentes observations, ϕ(xk+1) :
bϕ = bϕ +1
k[ϕ(xk+1) − ϕ(x1)] (3.56)
La combinaison des étapes 1 et 2 pour la détermination d’une matrice de covariance adaptée
à la nouvelle fenêtre, produit la formulation suivante :
Rϕ = Rϕ − k
(k − 1)2[ϕ(x1) − bϕ] [ϕ(x1) − bϕ]T (3.57)
+1k
[ϕ(xk+1) −
k
(k − 1)bϕ +
1(k − 1)
ϕ(x1)]
(3.58)
× 1k
[ϕ(xk+1) −
k
(k − 1)bϕ +
1(k − 1)
ϕ(x1)]T
. (3.59)
Enfin, l’adaptation du modèle ACP à noyau (KPCA) exige en fait, un nouveau calcul des va-
leurs et vecteurs propres de la matrice de covariance R à chaque instant que la fenêtre glissante
est mise à jour (up and down-dating). Les méthodes existantes comprennent la méthode de SVD,
la modification de Rang-1, la méthode de Lanczos, etc. Il est montré que la complexité pour re-
calculer un modèle de l’ACP linéaire est de O(k3) pour la plupart des méthodes existantes.
Afin de répondre à ce probleme, la deuxième contribution de Liu et al. (2009) consiste
en l’intégration d’une procédure numérique plus efficace pour le calcul des valeurs et vecteurs
propres de la matrice R, qui est d’un ordre de complexité de O(k2).
3.5.2 ACP à noyau récursive (RKPCA)
Comme dans le cas linéaire de la méthode ACP récursive, la présente section propose une
étude similaire dans le cas non linéaire de l’ACP à noyau, proposée par Chakour et al. (2013 ;
89

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
2015a). Suite aux questionnements précedents, on constate qu’il est nécessaire de prendre en
compte plusieurs points relatifs à l’adaptation du modèle KPCA : incorporer l’adaptation du vec-
teur moyenne dans l’adaptation de la matrice de Gram, combiner les étapes de mise à jour et
d’élimination en même temps, adapter la décomposition en valeurs/vecteurs propres de la ma-
trice de Gram en utilisant l’ancienne décomposition, de réduire plus, la complexité de calcul.
La technique que nous avons adopté, Chakour et al. 2015a, permet une projection de l’ACP ré-
cursive linéaire dans l’espace à noyau ou de re-description, où une adaptation récursive de la
matrice de Gram qui tient compte de ces questions est présentée. Contrairement à la méthode
ACP à noyau adaptative basée sur une fenêtre glissante, la récursivité se réfère à l’autoréfé-
rence. En effet, le modèle sera mis à jour en relation seulement avec celui de l’instant précédent
et les mesures nouvellement disponibles. Cela peut engendrer alors plus de rapidité dans les
procédures d’adaptation ainsi que la réduction de la compléxité de calcul.
Afin d’apprendre ou modéliser au cours du temps l’évolution des caractéristiques variables
des données, il est souhaitable de se concentrer d’avantage sur les données récemment acquises
et un peut moins sur les données plus anciennes. Par exemple, lors de la poursuite d’une cible
avec des changements apparaissant dans sa trajectoire, il est probable que les observations ré-
centes seront plus indicatives de son apparence que celles qui sont les plus éloignées. Le moyen
le plus commun pour modérer l’équilibre entre les anciennes et les nouvelles observations est
d’intégrer la technique de pondération exponentielle (exponentially weighted PCA). Les coeffi-
cients de pondération sont attribués en fonction de l’âge de la mesure collectée.
L’idée de base de Chakour et al. (2015a) était en premier lieu, la projection de l’ACP pondé-
rée exponentiellement (Exponentially Weighted KPCA) dans l’espace noyau, pour la surveillance
et le diagnostic des processus non linéaires variables dans le temps. La contrainte de transfor-
mation noyau, nécessite tout un ensemble de mesures à chaque instant afin de calculer le nou-
veau vecteur noyau de la nouvelle mesure ϕ(xk+1). Une fenêtre glissante de taille k est utilisée
pour calculer à chaque instant l’image de la nouvelle mesure disponible ϕ(xk+1) en relation
avec l’ensemble des anciennes mesures définies à l’intérieur de la fenêtre. L’idée principale est
de combiner l’algorithme de l’ACP à base de fenêtre glissante pour calculer correctement la
transformation noyau (vecteur noyau, k) à chaque instant, avec l’algorithme de l’ACP pondérée
exponentiellement afin de mettre à jour d’une manière récursive la matrice de covariance dans
l’espace de re-description en fonction du nouveau vecteur k. Ding et al. (2010) à introduit un al-
gorithme similaire pour des applications temps réel dans la poursuite visuelle (visual tracking),
qui permet une adaptation de la matrice de Gram en utilisant une fenêtre glissante pondérée
(Weighted Sliding Window). En effet, la technique proposée par Chakour et al. (2015a) permet
une adaptation de la matrice de Gram sur une base continue (sample-wise), et par block d’échan-
tillon (block-wise). Ainsi, en se basant sur la méthode de la fenêtre glissante pondérée (WSW),
la procédure d’élimination de l’ancienne mesure (down-dating) et la procédure de mise à jour
90

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
de la nouvelle mesure (updating) sont combinées en même temps dans un seul algorithme.
Formulation récursive de la matrice noyau
Dans la technique de l’ACP à noyau à base de fenêtre glissante (MWKPCA), similairement au
cas linéaire, une fois les nouvelles mesures de données sont disponibles, une fenêtre de données
de taille fixe qui se déplace en temps réel est mise à jour. A chaque instant de mise à jour, ces
données à l’intérieur de la fenêtre sont projetées dans l’espace de re-description, où une nouvelle
matrice noyau ou matrice de covariance est calculée afin de mettre à jour le modèle KPCA. En
fait, il s’agit du principe suivant :
Φ(X) ⇒ Φ(X)
ou plutôt,
X ⇒ X ⇒ Φ(X)
avec, Φ(X) = [Φ(x1),Φ(x2), . . . ,Φ(xk)], et Φ(X) = [Φ(x2), . . . ,Φ(xk+1)]. X = [x1, x2, . . . , xk],
X = [x2, x3, . . . , xk, xk+1], k est la taille de la fenêtre glissante, et Φ(xk+1) est l’échantillon nou-
vellement enregistré transformé dans l’espace de caractéristiques.
Supposons que nous ayons à l’instant k une fenêtre glissante avec un bolck de données initial
X. La matrice noyau Kk de cette fenêtre glissante est donnée comme suit :
Kk =
k(x1, x1) k(x1, x2) . . . k(x1, xk)
k(x2, x1) k(x2, x2) . . . k(x2, xk)
· · · ·k(xk, x1) k(xk, x2) . . . k(xk, xk)
(3.60)
Lorsque une nouvelle donnée xk+1 est disponible dans la fenêtre de taille (k), i.e. adaptation
en continue (sample wise), de nouveau la transformation Φ(X) est calculée. En fait, la matrice
noyau Kk+1 de la fenêtre glissante nouvellement mise à jour est donnée par :
Kk+1 =
k(x2, x2) k(x2, x3) . . . k(x2, xk+1)
k(x3, x2) k(x3, x3) . . . k(x3, xk+1)
· · · ·k(xk+1, x2) k(xk+1, x3) . . . k(xk+1, xk+1)
(3.61)
où, knew = [k(x2, xk+1), k(x3, xk+1), . . . , k(xk+1, xL+1)]T = k
(X, xk+1
)est le nouveau vecteur
noyau de la nouvelle mesure collectée à l’instant k + 1.
Pour ce qui concerne la mise à jour par block de données (block-wise), la matrice noyau
Kk+τ de la fenêtre glissante nouvellement mise à jour est donnée comme suit :
91

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
Kk+τ =
k(xτ , xτ ) k(xτ , xτ+1) . . . k(xτ , xk+τ )
k(xτ+1, xτ ) k(xτ+1, xτ+1) . . . k(xτ+1, xk+τ )
· · · ·k(xk+τ , xτ ) k(xk+τ , xτ+1) . . . k(xk+τ , xk+τ )
(3.62)
avec, knew = [k(xτ , xk+τ ),k(xτ+1, xk+τ ), . . . , k(xk+τ , xk+τ )]T = k
(X, xk+τ
)est le nouveau vec-
teur noyau du nouveau block de mesure disponible à l’instant k+ τ , et τ est le pas d’adaptation,
avec X = [xτ , xτ+1, xτ+2, . . . , xk, xk+1, . . . , xk+τ ].
Une fois la matrice de données mise à jour à l’intérieur de la fenêtre glissante est transformée
en un espace à noyau, une nouvelle matrice noyau centrée de taille k est obtenue, ainsi qu’une
décomposition en valeurs et vecteurs propres de cette dernière. Le modèle KPCA est recalculé
en relation avec ces nouvelles informations.
Dans l’algorithme de l’ACP linéaire récursive proposé par Choi et al. (2006), la mise à jour
du vecteur moyenne ainsi que la matrice de covariance sont données comme suit :
bk+1 = (1 − α)xk+1 + αbk (3.63)
Rk+1 = (1 − β) (xk+1 − bk+1) (xk+1 − bk+1)T + βRk (3.64)
Comme cela est indiqué ci-dessus dans les équations (3.63) et (3.64), les techniques ré-
cursives s’appuient sur l’oubli progressif d’anciennes connaissances au profit de nouvelles acqui-
sitions. En fait, l’adaptation comporte habituellement une pondération de l’information précé-
dente en utilisant un facteur d’oubli. Les coefficients de pondération sont attribués en fonction
de l’âge de la mesure collectée. Sur le même principe, on essaie d’introduire la même idée à
l’algorithme de l’ACP à noyau. A chaque fois qu’un nouvel échantillon de mesure est disponible,
un nouveau vecteur noyau knew peut être calculé afin d’ajuster ou mettre à jour la matrice de
covariance dans l’espace à noyau (feature space).
Supposons que les mesures (x1, x2, . . . , xk) représentent l’état actuel du système, tandis que
la nouvelle mesure xk+1 est considérée comme une donnée de mise à jour, collectée à l’instant
k + 1. Nous commençons avec la formulation récurrente de la matrice de covariance noyau :
Rϕk+1 =
1
k + 1
k+1∑i=1
ϕ(xi)ϕ(xi)T =
k
k + 1Rϕ
k +1
k + 1ϕ(xk+1)ϕ(xk+1)
T (3.65)
Pour des raisons de simplicité, nous avons considéré l’hypothèse que toutes les données
92

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
transformées dans l’espace noyau sont de moyenne nulle. Néanmoins, l’hypothèse est souvent
invalidée puisque la moyenne des données peut changer avec l’arrivée de nouvelles données au
cours du temps. Notant les moyennes précédentes et actuelles de données dans l’espace à noyau
par bϕk et bϕ
k+1, respectivement. La formulation récurrente de la matrice noyau (3.65) devient
alors comme suit :
Rϕk =
1
k
k∑i=1
(ϕ(xi) − bϕ
k
)(ϕ(xi) − bϕ
k
)T
, (3.66)
et,
Rϕk+1 =
1
k + 1
k+1∑i=1
(ϕ(xi) − bϕ
k+1
)(ϕ(xi) − bϕ
k+1
)T
. (3.67)
Pour le cas de la matrice de covariance Rϕk+1, les images ϕ(xi), i = 1, 2, . . . , k, k + 1 sont
centrées avec la moyenne courante bk+1 mais pas avec le vecteur moyenne précedent, utilisé
dans Rϕk . On peut ainsi, facilement obtenir, pour les matrices de covariance noyaux, la forme
récursive suivante :
Rϕk+1 =
k
k + 1Rϕ
k +1
k + 1
(ϕ(xk+1) − bϕ
k
)(ϕ(xk+1) − bϕ
k
)T
(3.68)
Lorsque k ≫ 1, β =k
k + 1représente un facteur d’oubli de la matrice noyau, sa valeur dans
notre cas est plus proche de 1. Comme dans le cas linéaire (Eq. (3.64) et (3.63)), la formulation
récursive (3.68) est ainsi donnée :
Rϕk+1 = βRϕ
k + (1 − β)(ϕ(xk+1) − bϕ
k
)(ϕ(xk+1) − bϕ
k
)T
(3.69)
Avec,
bϕk+1 = αbϕ
k + (1 − α)ϕ(xk+1). (3.70)
où, α est le facteur d’oubli du vecteur moyenne dans l’espace à noyau.
En développant l’expression (3.69) en termes de fonctions ou de matrices de noyaux, elle
pourrait être exprimée comme suit :
Kk+1 = βKk + (1 − β)(
knewkT
new
). (3.71)
où, knew =[k(x2, xk+1), k(x3, xk+1), . . . , k(xk+1, xk+1)
]T= k
(X, xk+1
)est le nouveau vecteur
noyau de la nouvelle mesure collectée à l’instant k+1, dans le cas d’une mise à jour en continue
(sample-wise). Et, knew =[k(xτ , xk+τ ), k(xτ+1, xk+τ ), . . . , k(xk+τ , xk+τ )
]T= k
(X, xk+τ
)est le
nouveau vecteur noyau du nouveau block de mesure disponible à l’instant k + τ (block-wise
adaptation).
93

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
A chaque instant de mesure où la matrice noyau est mise à jour recursivement dans l’espace
à noyau, une décomposition en valeurs et en vecteurs propres de cette dernière est effectuée afin
de recalculer le nouveau modèle. Le choix optimal du facteur d’oubli, détermine l’influence des
données les plus anciennes sur le modèle actuel. Toujours en relation avec le critère "plasticité-
stabilité", durant les périodes où la dynamique du processus change rapidement, l’accent est mis
sur les observations les plus récentes. A cet effet, un facteur d’oubli adaptable dans le temps
est necessaire. D’après Choi et al. (2006), dans le cas linéaire, le facteur d’oubli permettant une
mise à jour de la moyenne dans l’espace à noyau est calculé comme suit :
αk = αmax − (αmax − αmin)[1 − exp
−ϑ(∥bϕ
k−1∥/∥bϕnor∥
)n](3.72)
où αmin et αmax sont la valeur minimale et la valeur maximale du facteur de pondération,
respectivement, k, β, et n sont les paramètres de la fonction. Avec, ∥bϕ∥ = ∥bϕk − bϕ
k−1∥ est
la norme du vecteur euclidien de la différence entre deux vecteurs moyennes consécutifs. Pour
|bϕnor∥ est la moyenne ∥b∥ obtenue en utilisant les données historiques.
De même, le facteur d’oubli pour mettre à jour la matrice de Gram est donné par :
βk = βmax − (βmax − βmin)[1 − exp
−ϑ(∥Rϕ
k−1∥/∥Rϕnor∥
)n](3.73)
où βmin et βmax sont la valeur minimale et la valeur maximale du facteur de pondération,
respectivement, ϑ, β, et n sont les paramètres de la fonction. Ainsi, ∥Rϕ∥ = ∥Rϕk −Rϕ
k−1∥ est la
norme de la matrice euclidienne de la différence entre deux matrices de covariance consécutives.
Adaptation de la matrice noyau en combinant les étapes up- and downdating
En ACP récursive, les anciens échantillons sont pondérés exponentiellement dans le temps,
de sorte que l’influence de la plus récente mesure soit la plus grande. Afin de permettre une
estimation de la matrice de covariance avec un mécanisme d’adaptation qui met l’accent un
peu plus sur les observations les plus récentes (updating), les observations les plus anciennes
sont complètement tronquées (down-dating) simultanément. Ding et al. (2010) ont intégré une
nouvelle technique basée sur une fenêtre glissante pondérée (Weighted sliding window).
De manière analogue à la section précédente, la formulation récursive de la matrice de
covariance (3.69) sera modifée et aura la forme suivante :
Rϕk+1 = β Rϕ
k − (1 − β)k(ϕ(xk+1−k) − bϕ
k
)(ϕ(xk+1−k) − bϕ
k
)T(3.74)
+ (1 − β)(ϕ(xk+1) − bϕ
k
)(ϕ(xk+1) − bϕ
k
)T.
avec, k est la longueur de la fenêtre glissante.
94

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
Contrairement au processus d’adaptation dans (3.69), à chaque instant de mise à jour, la
nouvelle formule d’adaptation (3.74) a fait exclure l’effet de la mesure la plus ancienne de la
fenêtre glissante ϕ(xk+1−k).
Enfin, à chaque instant que de nouvelles mesures sont disponibles, la matrice de Gram est
mise à jour en relation avec ces nouvelles données. Les valeurs et les vecteurs propres de cette
nouvelle matrice, sont calculés, pour obtenir une nouvelle représentation KPCA. Un nombre
important d’approches ont été proposées pour recalculer et/ou adapter, à chaque instant de
mesure, les valeurs et vecteurs propres. Afin d’adapter la décomposition en valeurs et vecteurs
propres de la matrice de Gram en relation avec les mesures nouvellement disponibles tout en
respectant un ordre de calcul réduit (un ordre de calcul linéaire O(k)), nous proposons (Chakour
et al. (2015b)) une nouvelle technique de l’ACP à noyau, adaptative. Elle est considérée comme
une extension de l’ACP neuronale linéaire, présentée dans le chapitre précédent, dans le cas non
linéaire de la méthode ACP à noyau. Cette dernière fait l’objet de la section suivante.
3.5.3 ACP à noyau neuronale (NKPCA)
Habituellement, lorsqu’un nouvel échantillon de mesure devient disponible, une fonction
noyau est disponible, ϕ(xt+1) ≡ knew. Elle doit être inclue dans le modèle, plutôt dans la matrice
à noyau de l’instant précédent. Les valeurs et les vecteurs propres de la matrice à noyau nouvel-
lement mise à jour sont calculés pour obtenir une nouvelle représentation KPCA. De nombreuses
approches ont été proposées pour calculer et/ou adapter les valeurs et les vecteurs propres dont
l’ordre de complexité est de O(k3). Réduire l’ordre de calcul du modèle KPCA est un domaine
de recherche très intéressant, qui n’a pas encore été abordé de manière efficace.
L’identification du modèle ACP à noyau nécessite le stockage et la manipulation de l’en-
semble de la matrice à noyau (k×k). Comme les systèmes sont naturellement non stationnaires
et les nouvelles données peuvent continuer à être disponibles au cours du temps, recalculer la
décomposition en valeurs/vecteurs propres de la matrice noyau à chaque instant, a été jugée non
réalisable. L’ACP à noyau devient non applicable pour la modélisation en ligne pour de grandes
quantités de données et de dimension élevée. La plupart des techniques analytiques permettant
l’estimation de vecteurs/valeurs propres, nécessitent un calcul intensif et ne sont pas les mieux
adaptées pour des applications temps réel.
Afin d’adapter la décomposition de la matrice de Gram en fonction de la mesure nouvel-
lement disponible avec un ordre de calcul réduit, nous proposons une extension au cas non
linéaire de l’algorithme développé sur le cas linéaire par Oja et Sanger. Dans un formalisme
fonctionnel basé sur les espaces à noyau, la version noyau de l’algorithme de Oja et Sanger a
été élaboré par Kim et al. (2005), qui est connu comme l’algorithme de Hebbian kernelizé (ker-
nelizing Hebbian algorithm, KHA). L’algorithme KHA permet de trouver les vecteurs propres
95

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
des données disponibles, sans la nécessité d’estimer et de stocker la matrice de covariance dans
l’espace de rédescription, ou la matrice noyau. Ceci contribue à réduire le coût de calcul ainsi
que la complexité d’occupation de l’espace mémoire à un ordre linéaire O(k). Cette propriété
conforte notre choix et rend l’algorithme KHA particulièrement souhaitable pour la surveillance
et le diagnostic des systèmes non linéaires variant dans le temps. Pour des raisons de clarté, le ta-
bleau suivant retrace succinctement l’évolution des algorithmes de l’ACP, en termes de linéarité
du modèle et du mode de traitement :
Modèle Mode
Analyse en composantes principales (Jolliffe, 1986) linéaire batch
ACP-à-noyaux (Schölkopf et al., 1998) non linéaire batch
Règles d’Oja (Oja, 1982) et de Sanger (Sanger, 1989a) linéaire en ligne
ACP-à-noyaux itératif (Kim et al., 2005) non linéaire itératif
TABLE 3.1 – Modèles et modes de traitement de l’ACP.
Adaptation des valeurs/vecteurs propres dans l’espace à noyau
Contrairement aux algorithmes existants de l’ACP à noyau adaptatifs (AKPCA), celui qui est
proposé se réfère à un paradigme où, à chaque instant de mesure où une nouvelle observation
est disponible, le modèle est mis à jour seulement en fonction d’elle sans avoir à ré-explorer
toutes les données précédemment disponibles. En fait, dans un premier temps, avant d’abor-
der les principales démarches de l’algorithme proposé, il est nécessaire de rappeler le dilemme
apprentissage-oubli lorsqu’il s’agit des système adaptatifs. Il s’agit de trouver un compromis op-
timal entre l’apprentissage des nouvelles informations et l’oubli des anciennes.
Dans le même contexte, la manière dont le dilemme apprentissage-oubli est défini, c’est à
dire l’ajustement du modèle avec les nouvelles données ou connaissances acquises, et l’élimi-
nation des anciennes connaissances, conduit à l’instabilité du processus d’adaptation. La consé-
quence pourrait être l’introduction dans la structure du modèle, de comportements anormaux
ou indésirables (outliers). En effet, l’utilisation de la règle d’Oja ou de Sanger telle quelle nous
conduit au même cas extrême d’adaptation.
Afin d’adapter les valeurs/vecteurs propres tout en respectant les exigences du dilemme
d’adaptation, la formulation récursive de la matrice à noyau proposée dans la section précédente
est utilisée. Aussi, pour réduire l’ordre de calcul du modèle KPCA, la version noyau de la règle
d’Oja (KHA) est intégrée dans cette dernière, où un nouveau processus d’adaptation stable est
développé. La formulation récursive de la matrice de covariance, similairement à la section
précédente, est donnée comme suit :
96

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
Rϕk+1︸︷︷︸
matrice mise à jour
= β Rϕk︸︷︷︸
K à l’instant k
+ (1 − β)(ϕ(xk+1) − bϕ
k
)(ϕ(xk+1) − bϕ
k
)T
︸ ︷︷ ︸matrice noyau du nouveau vecteur ϕ(xk+1)
(3.75)
La décomposition en valeurs/vecteurs propres de l’equation (3.75) peut être écrite selon l’ex-
pression suivante :
Pk+1Λk+1PTk+1 = β PkΛkP
Tk + (1 − β) PnewΛnewPT
new (3.76)
où, Pnew est la matrice des vecteurs propres du nouveau vecteur noyau, knew, disponible à
l’instant k + 1.
En utilisant la version noyau de la règle d’Oja et Sanger, l’algorithme de Hebbian kernelisé,
les vecteurs propres Pnew du vecteur noyau de données nouvellement disponibles est facilement
estimé sans la nécessité de calculer sa matrice noyau dans son intégralité. Les matrices Pk sont
celles des vecteurs propres calculés à l’instant précédent. Pour le cas de la première mesure
disponible à l’instant k = 1, sa valeur est égale aux vecteurs propres du modèle initial (i.e.
modèle hors ligne).
En partant de ce principe, une nouvelle formulation récursive-incrémentale est proposée.
Elle permet une adaptation ou ajustement direct des vecteurs propres à chaque instant où de
nouvelle mesures sont disponibles. Cette formulation est donnée comme suit :
Pϕk+1 = β Pϕ
k + (1 − β) Pϕnew (3.77)
avec, β est un facteur d’oubli, ces valeurs sont proches de 1.
Pour plus de flexibilité dans le mécanisme d’adaptation du modèle KPCA, qui dépend de
la quantité de variation dans la dynamique du système, le niveau de pondération attribué au
nouveau vecteur Pϕnew nécessite d’être variable dans le temps. Comme proposé par Choi et al.
(2006), nous proposons aussi un nouveau facteur de pondération, qui dépend directement du
changement survenu dans les structures internes du modèle P. Le facteur d’oubli variable dans
l’espace à noyau, est donné par la relation suivante :
βk = βmax − (βmax − βmin)[1 − exp
−ϑ(∥Pϕ
k−1∥/∥Pϕnor∥
)n](3.78)
où βmin et βmax sont la valeur minimale et la valeur maximale du facteur de pondération, res-
pectivement, ϑ, et n sont les paramètres de la fonction. Et, ∥Pϕ∥ = ∥Pϕk − Pϕ
k−1∥ est la norme
euclidienne de la différence entre deux vecteurs propres consécutifs.
Ainsi l’efficacité de calcul du modèle ACP à noyau en utilisant la formulation récursive-
97

ACP à noyau adaptative (Adaptive KPCA, AKPCA)
incrémentale proposée (3.77), est augmentée. L’ordre de complexité de calcul ainsi que la
capacité mémoire, est réduit à un ordre linéaire O(k).
Algorithme de Hebbian à noyau (Kernel Hebbian Algorithm, KHA)
Comme mentionné dans l’équation (3.77), les vecteurs propres Pϕnew du nouveau vecteur à
noyau (knew) des données nouvellement disponibles, sont calculés en utilisant l’algorithme de
Hebbian à noyau.
Il convient de noter que la taille de la matrice du noyau est le carré du nombre d’observa-
tions ou de mesures disponibles dans la base de données historique. Il devient ainsi coûteux
en terme de complexité de calcul, de résoudre directement le problème de la décomposition
en valeurs-vecteurs propres noyau pour un grand nombre de données. Comme indiqué dans
la dernière section du chapitre précédent, un problème similaire se produit avec l’ACP linéaire
lorsque la matrice de covariance devient de grande taille, i.e. un grand nombre de paramètres
(capteurs/actionneurs) à surveiller. Ceci a motivé l’introduction de l’algorithme GHA qui ne
nécessite pas de stockage et l’estimation de la matrice de covariance. Dans cette partie, une ap-
proche similaire est présentée en reformulant l’algorithme GHA dans l’espace à noyau, appelé
algorithme de Hebbian à noyau (Kim et al., 2005). La projection de la règle d’Oja et de Sanger
dans l’espace à noyau est donnée comme suit :
P(i+ 1) = P(i) + η(k)(y(i)ϕ(xk+1)
T − LT[y(i)y(i)T ] P(i)), (3.79)
où, η est le pas d’apprentissage, et i est le nombre d’itérations de l’algorithme. Ainsi,
y(i) = P(i)ϕ(xk+1). (3.80)
En développant l’expression (3.79) en terme de fonctions noyaux, elle devient alors sous la
forme suivante :
P(i+ 1) = P(i) + η(i)[y(i) k(xk+1, ·)T − y(i)2 P(i)
](3.81)
avec,
y(i) = P(i)k(xk+1, ·)T , (3.82)
ainsi,
yj(i) =k∑
l=1
ajl(i)k(xk+1, xj)T . (3.83)
où la jème ligne aj = (aj1, . . . , ajk) de la matrice P correspond aux coefficients du jème vecteur
propre de la matrice noyau K à l’instant k + 1. k est la taille de la fenêtre glissante utilisée pour
98

Conclusion
calculer la transformation noyau de la mesure nouvellement disponible xk+1.
Néanmoins, tenir compte de la variation de la moyenne dans l’espace à noyau pour l’adap-
tation des vecteurs propres est vitale lorsqu’il s’agit des systèmes non stationnaires. Le vecteur
noyau des nouvelles données disponibles est centré avant le calcul des vecteurs propres en utili-
sant l’algorithme KHA. La formulation récursive (3.70) du vecteur moyenne permet une phase
de normalisation adaptative et tient compte de cette question.
Une valeur constante du pas d’adaptation η, conduit à ralentir la convergence de l’algorithme
d’apprentissage KHA. Afin de garantir et accélérer la convergence de cet algorithme, un vecteur
de gain adaptatif η associé aux vecteurs propres courant KHA a été adopté par Schraudolph et
al. (2007). Ce dernier considère l’estimation des valeurs propres courantes comme un vecteur
de gain (pas d’adaptation). Le vecteur de gain ηj(i) pour chaque vecteur propre pj(i) est estimé
comme suit :
ηj(i) = η0∥λ(i)∥λj(i) t1
(3.84)
où t1 est le nombre d’itérations et η0 est un paramètre libre.
L’objectif de l’algorithme Hebbian à noyau (KHA), comme celui de GHA, est de trouver en
premier lieu les vecteurs propres du nouveau vecteur noyau, sachant que les valeurs propres
correspondantes sont généralement inconnues lors de l’exécution de l’algorithme. Les valeurs
propres estimées, associées aux vecteurs propres KHA courant, sont calculées comme suit par
Schraudolph et al. (2007) :
λj(i) =∥Pj(i)k
Tnew∥
∥Pj(i)∥(3.85)
où Pj désigner la j-ème colonne de P.
3.6 Conclusion
Dans ce chapitre, la modélisation des systèmes non linéaires à base de la méthode ACP non li-
néaire est envisagée. Dans un premier temps, un bref historique des méthodes ACP non linéaires
est étudiée. Il a été notamment focalisé sur la méthode ACP non linéaire à noyau. Les différentes
démarches à suivre pour avoir un modèle ACP à noyau statique adéquat sont explicitées. Dans
l’ACP à noyau, le problème de l’estimation de la pré-image permet d’étendre le principe de la
reconstruction, comme en ACP linéaire, afin de générer des résidus structurés utiles et pourrait
être appliquée à la localisation de défauts. L’extension de la méthode de contribution basée sur
la reconstruction (RBC) dans le cas non linéaire a été présentée par Alcala et Qin (2011).
99

Conclusion
Dans un second temps, et comme au chapitre précédent, la méthode ACP à noyau adap-
tative est étudiée. Deux algorithmes de l’ACP à noyau, adaptative sont proposés. La première
contribution consiste à étendre le principe de l’ACP récursive linéaire dans l’espace à noyau. Le
challenge majeur des techniques adaptatives est de surpasser la complexité de calcul, élevée.
À cet effet, une nouvelle approche, ACP neuronale, est proposée comme une alternative qui
permet l’adaptation à ce problème. En fait, le chapitre trois est considéré comme une version
étendue du chapitre 2 dans le cas non linéaire de la méthode ACP.
Le chapitre suivant, discute les différentes techniques permettant la détection et la localisa-
tion des éventuels défauts en utilisant la méthode ACP.
100

Chapitre 4Détection et localisation de défauts
Sommaire4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
4.2 Détection de défauts . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
4.2.1 L’erreur de Prédiction Quadratique, SPE . . . . . . . . . . . . . . . . . 103
4.2.2 Statistique T2 de Hotelling . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.2.3 Indice combiné . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.3 Détection de défauts dans l’espace à noyau . . . . . . . . . . . . . . . 105
4.3.1 Indice SPE dans H . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
4.3.2 Indice T2 dans H . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
4.3.3 Indice combiné dans H . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
4.4 Procédure de surveillance des systèmes dynamiques . . . . . . . . . 107
4.5 Localisation de défauts . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
4.5.1 Localisation par calcul des contributions . . . . . . . . . . . . . . . . . 112
4.5.2 Localisation par contributions à base de reconstruction (RBC) . . . . . 113
4.5.3 Localisation par ACP partielle . . . . . . . . . . . . . . . . . . . . . . . 115
4.6 Localisation dans le cas du noyau par RBC-KPCA . . . . . . . . . . 118
4.6.1 Algorithme itératif du point fixe . . . . . . . . . . . . . . . . . . . . . . 119
4.6.2 Méthode d’optimisation de Newton . . . . . . . . . . . . . . . . . . . . . 119
4.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
4.1 Introduction
Un fonctionnement relativement sûr et efficace nécessite un niveau de surveillance et de su-
pervision adéquat par notamment la détection et la localisation des anomalies ou défauts. Les
101

Introduction
variables surveillées évoluent dans une plage de mesures considérées de fonctionnement nor-
mal ; au delà c’est un disfonctionnement qu’il faudra prendre en charge. Il s’agit alors d’identifier
l’origine du défaut en question. Les techniques classiques font usage des seuils supérieurs et in-
férieurs pour chaque variable afin de détecter le défaut. Généralement, cette stratégie conduit à
un grand nombre d’indicateurs, et rend difficile l’identification des défauts.
Plusieurs auteurs ont beaucoup travaillé sur la question en utilisant la méthode des compo-
santes principales (ACP) et les moindres carrés partiels (PLS), MacGregor et al. (1994), Wise
et Ricker (1991), et Kresta et al. (1991). Elles ont eu un succès considérable avec des applica-
tions industrielles. Le succès de ces approches réside dans la collecte et l’exploitation de grande
quantité de données pendant le fonctionnement normal des processus. C’est d’ailleurs, cette ri-
chesse informationnelle qui contribue au développement de modèles statistiques relativement
très proche du fonctionnement normal des processus étudiés. La détection de défauts est effec-
tuée par comparaison des deux comportements, l’observé et celui donné par le modèle. En effet,
des signaux révélateurs de présence de défauts, appelés résidus, sont générés.
La surveillance des défauts utilise des techniques et tests statistiques. A cette fin, plusieurs
indices ont été définis à partir, soit d’une estimation paramétrique, soit d’une estimation de l’état
du système. C’est cette dernière que nous avons adopté dans notre travail et pour laquelle plu-
sieurs indices ont été développés dans la littérature, notamment par Qin (2003). Ce dernier a
présenté cinq indices, dont les plus connus et utilisés sont SPE (l’erreur quadratique de prédic-
tion), l’indice de Hotelling T2 et l’indice combiné. Ils feront l’objet de la première partie de ce
chapitre, avec une présentation dans le cas linéaire et non linéaire selon la méthode ACP.
Pour chacun de ces indices, une valeur limite ou seuil est défini et leur est associé. Le dé-
faut est déclaré, une fois que ce seuil est dépassé. Il y a lieu, alors de lancer le processus de
localisation. Cette phase, basée sur l’analyse en composantes principales (ACP), a été beaucoup
étudié dans la littérature. Trois approches se sont distinguées : l’approche par structuration des
résidus (Gertler et al. 1999), l’approche reposant sur le principe de calcul des contributions à
l’indice de détection (MacGregor et al. 1995), et les approches utilisant des bancs de modèles.
Cette dernière est décomposée en trois autres techniques, l’ACP partielle, l’approche utilisant le
principe de reconstruction (Dunia et al. 1996), et l’approche par élimination qui est similaire à
l’approche par reconstruction. Dans une deuxième partie de ce chapitre, seules les techniques
de localisation de défauts qui permettent une extension dans le cas non linéaire de la méthode
ACP à noyau seront explicitées. Parmi ces méthodes on peut citer l’ACP partielle, et la méthode
des contributions par reconstruction (reconstruction-based contributions, RBC).
102

Détection de défauts
4.2 Détection de défauts
L’ACP modélise les corrélations mesurées entre les données historiques lorsque le processus
est en fonctionnement normal. Une violation de la corrélation indique une situation inhabi-
tuelle, parce que les variables ne conservent pas leurs relations normales. En fait, une fois que le
modèle ACP est élaboré, les nouvelles observations de test seront projetées sur le nouvel espace
engendré. Elles seront caractérisée par une première distance, notée T2 de Hotelling, dans l’es-
pace principal et par une seconde, appelée SPE, dans l’espace résiduel. Ces deux distances sont
utilisées pour la surveillance et le suivi du processus. Cependant, un défaut perturbe à la fois les
projections des observations dans l’espace principal et dans l’espace résiduel. La présence d’un
défaut provoque un changement dans les corrélations entre les variables, dont les relations ne
sont plus vérifiées. Dans ce cas, la projection du vecteur de mesures dans le sous-espace des
résidus va croître par rapport à sa valeur dans les conditions normales. En effet, l’indice SPE est
un test global qui cumule les erreurs de modélisation présentes sur chaque résidu et la statis-
tique T2 est calculée à partir des premières composantes principales qui ne représentent pas les
résidus.
4.2.1 L’erreur de Prédiction Quadratique, SPE
L’indice de détection SPE (Squared Prediction Error) est définie comme étant la norme au
carré du vecteur résiduel x.
SPE(k) = ∥x2(k)∥ = xT (k)CCTx(k) = xT (k)Cx(k). (4.1)
Le processus est considéré en fonctionnement normal (absence de défaut) si :
SPE ≤ δ2 (4.2)
où, δ2 est le seuil de détection du SPE.
δ2 = gSPEχ2α(hSPE) (4.3)
avec, un intervalle de confiance (1 − α) × 100%, gSPE =θ2θ1
, hSPE =θ21
θ2, et θ1 =
∑mi=l+1 λi,
θ2 =∑m
i=l+1 λ2i , et λi est la valeur propre de la matrice de covariance. Ce contrôle limite est
proposé par Nomikos et MacGregor (1995) en utilisant les résultats de Box (1954).
L’indice SPE somme les résidus sans tenir compte de leur variance. Bien que les résidus avec
une faible variance auront une influence moindre sur la quantité SPE par rapport aux résidus
ayant une variance plus élevée. Ceci, peut entrainer de nombreuses fausses alarmes, et ainsi
103

Détection de défauts
réduire la sensibilité de détection de défaut. De ce fait, d’autres indices ont été proposés afin de
surmonter cette difficulté, on peut citer l’indice de Hawkins et l’indice de Harkat et al. (2003).
4.2.2 Statistique T2 de Hotelling
La variation des données de processus dans l’espace principal (PS) est mesurée par l’indice
T2. Elle est définie comme suit :
T2(k) = xT (k)PΛ−1P T x(k) = xT (k)Dx(k). (4.4)
où D = P Λ−1P T est semi-définie positive.
Le processus est en fonctionnement normal, à l’instant k, si :
T2(k) ≤ τ 2 = χ2α (l) , (4.5)
avec, un intervalle de confiance (1 − α) × 100%. Qin (2003) utilise les résultats de Box (1954)
pour obtenir ce contrôle limite.
Théoriquement, la statistique T2 n’est pas affectée par le bruit, qui est représenté par les
dernières valeurs propres. Elle peut être interprétée comme la mesure des variations normales
du processus. En fait, la violation du seuil de détection indique que ces variations sont en dehors
des limites de contrôle et correspondent à un fonctionnement anormal.
4.2.3 Indice combiné
En utilisant la complémentarité des indices précédents, et afin d’être sensible à l’espace prin-
cipal et à l’espace résiduel en même temps, un nouvel indice, appelé indice combiné, est alors
présenté par Yue et Qin, (2001). Ce dernier combine les indices SPE et T2 en un seul indice
comme suit :
φ(k) =SPE(k)
δ2+
T2(k)
τ 2= xT (k)Ψx(k). (4.6)
avec,
Ψ =C
δ2+D
τ 2(4.7)
Le processus est considéré en fonctionnement normal, à l’instant k, si φ ≤ ζ2. Où le seuil ζ2
est donné par l’expression suivante :
ζ2 = gφχ2α(hφ) (4.8)
104

Détection de défauts dans l’espace à noyau
avec, gφ =(l
τ4+θ2δ4
)/
(l
τ2+θ1δ2
), hφ =
(l
τ2+θ1δ2
)2
/
(l
τ4+θ2δ4
).
Le détail de calcul du contrôle limite de cet indice est donné par Qin (2003) en utilisant les
résultats de Box (1954).
4.3 Détection de défauts dans l’espace à noyau
L’ACP à noyau a beaucoup apporté comme outil de surveillance des systèmes non linéaires.
En effet, l’idée de base est de projeter les données de l’espace d’entrée, où leurs relations sont
non linéaires, sur un autre espace où elles sont distribuées linéairement. Cet espace s’appelle
l’espace caractéristique. Ainsi, les techniques de détection de défauts utilisées avec l’ACP linéaire,
peuvent être appliquées dans ce nouvel espace. En effet, les statistiques T2 et SPE dans l’espace
caractéristique H peuvent être interprétées de la même manière. Les indices statistiques dans
l’espace caractéristique H sont définis dans la présente section.
4.3.1 Indice SPE dans H
L’indice de SPE est défini comme étant la norme du vecteur résiduel dans l’espace caracté-
ristique, il est défini comme suit :
SPE =∥∥∥ϕ(x) − ϕl(x)
∥∥∥2
=n∑
j=1
t2j −l∑
j=1
t2j = ΦT CΦ (4.9)
où, C = Pf PTf est la matrice de projection qui caractérise l’espace résiduel. Soit t, les dernières
composantes principales, et Pf la matrice des directions correspondantes.
t = P Tf Φ = [vl+1, . . . , vl+2, . . . , vn]T Φ (4.10)
L’indice de détection SPE dans l’espace caractéristique est calculé alors par la norme au carré
des composantes résiduelles,
SPE = tT t = ΦT Pf PTf Φ (4.11)
Comme nous ne connaissons pas la dimension de l’espace caractéristique, il n’est pas pos-
sible de connaître le nombre de composantes résiduelles. Ainsi, nous ne pouvons pas calculer
explicitement la matrice de projection P . Cependant, nous pouvons calculer le produit Pf PTf
comme une projection orthogonale de l’espace des composantes principales, qui est donné par :
Cf = Pf PTf = I − PfP
Tf (4.12)
105

Détection de défauts dans l’espace à noyau
cela conduit à
SPE = ΦT (I − PfPTf )Φ = ΦT Φ − ΦTPfP
Tf Φ (4.13)
L’indice SPE est donné en fonction des vecteurs d’entrée, en termes de fonction noyau,
comme suit :
SPE(x) = k(x, x) − ΦTX TPΛ−1P TXΦ (4.14)
= k(x, x) − k(x)TPΛ−1P T k(x) (4.15)
= k(x, x) − k(x)Ck(x) (4.16)
où C = PΛ−1P T .
Le seuil de l’indice de détection de défaut non linéaire SPE est donné ainsi,
δ2 = gSPEχ2α(hSPE) (4.17)
avec, un intervalle de confiance (1−α)×100%, gSPE =∑n
i=l+1 λ2i
(n− 1)∑n
i=l+1 λi, et hSPE =
(∑ni=l+1 λi
)2∑ni=l+1 λ
2i
.
4.3.2 Indice T2 dans H
L’indice T2 de Hotelling est calculé dans l’espace de fonction comme T2 = tT Λ−1t, où la
matrice Λ = diag(λ1, . . . , λl) contient les variances des composantes principales ti dans l’es-
pace des caractéristiques. A partir de l’équation des composantes principales dans l’espace des
caractéristiques, l’indice de détection T2 est calculé en utilisant la fonction noyau comme suit :
T2(x) = k(x)TPΛ−2P T k(x) = k(x)TDk(x) (4.18)
avec D = PΛ−2P T .
Le seuil de l’indice de détection de défauts non linéaires T2 est donné ainsi,
τ 2 = gT2
χ2α(hT2
) (4.19)
avec, un intervalle de confiance (1 − α) × 100%, gT2=
1n− 1
, et hT2= l.
4.3.3 Indice combiné dans H
Yue et Qin (2001) ont proposé l’emploi d’un indice combiné pour la surveillance de l’espace
résiduel et l’espace principal simultanément. Cet indice est une combinaison des deux indices
T 2 et SPE pondérés par leurs seuils. Le même concept est utilisé pour définir un indice de
106

Procédure de surveillance des systèmes dynamiques
détection de défaut permettant la surveillance de l’espace principal et l’espace résiduel dans
l’espace à noyau. Un indice combiné pour la détection de défaut dans l’espace caractéristique a
été proposé par Choi et al. (2005). Cependant, sa définition est différente de celle proposée par
Alcala (2011). L’extension de l’indice combiné dans l’espace caractéristique, proposé par Alcala,
est définie comme suit :
φ(x) =SPE(x)
δ2+
T2(x)
τ 2(4.20)
où δ2 et τ2 sont les seuils de l’indice SPE et l’indice T2, respectivement. L’indice combiné peut
être calculé en terme de fonctions du noyau, comme suit :
φ(x) =k(x, x)δ2
+ k(x)T
[PΛ−2P T
τ2− PΛ−1P T
δ2
]k(x) (4.21)
=k(x, x)δ2
+ k(x)T Ωk(x) (4.22)
où,
Ω =PΛ−2P T
τ 2− PΛ−1P T
δ2=D
τ 2− C
δ2(4.23)
Le seuil de l’indice de détection de défauts non linéaires φ est donné par,
ζ2 = gφχ2α(hφ) (4.24)
avec, un intervalle de confiance (1 − α) × 100%, gφ =l/τ4 +
∑ni=l+1 λ
2i /δ
4
(n− 1)(l/τ2 +
∑ni=l+1 λi/δ2
) , et hφ =(l/τ2 +
∑ni=l+1 λi/δ
2)2(
l/τ4 +∑n
i=l+1 λ2i /δ
4) .
4.4 Procédure de surveillance des systèmes dynamiques
La conduite et la surveillance de procédés industriels nécessitent l’analyse de leur comporte-
ment tel qu’il est perçu par les divers capteurs. Il s’agit essentiellement de détecter toute dévia-
tion par rapport à un comportement de référence, i.e. un modèle. La surveillance des systèmes
dynamiques, nécessite une mise à jour continue du modèle ACP. En effet, les indices de détection
de défauts sont recalculés en ligne à chaque instant qu’un nouvel échantillon de mesure est dis-
ponible. Afin que la technique de surveillance adoptée, basée sur les mécanismes d’adaptation
employés dans les chapitres précédents, soit capable de fonctionner en temps réel et prendre des
décisions correctes sur l’état du système, toute une stratégie de surveillance devra être élaborée.
La mise en place de la procédure complète, permettant de contrôler son fonctionnement et d’en
assurer le suivi, fait l’objet de cette partie.
107

Procédure de surveillance des systèmes dynamiques
Dans ce travail trois algorithmes de surveillance des systèmes variables dans le temps sont
proposés. Le premier algorithme, c’est celui qui a été proposé dans le chapitre 02, ACP linéaire
adaptative, et qui s’appuie sur la règle d’Oja et Sanger. Le deuxième et le troisième sont ceux du
cas non linéaire de la méthode ACP à noyau, KPCA récursive et KPCA neuronale. Les procédures
de détection de chaque méthode proposée sont détaillées dans cette partie.
1) L’algorithme de la méthode ACP-incrémentale proposé se résume comme suit (Chakour
et al. 2014) :
1. Mode hors-ligne :
(a) Acquérir un premier jeu de données Xinit de taille (n × m) issu du fonctionnement
normal du système.
(b) Calculer les valeurs initiales des paramètres de normalisation de la matrice Xinit ;
(c) Normaliser (centrer et réduire) le block de données initiales.
(d) Calculer le modèle ACP initial, i.e. valeurs et vecteurs propres de Xinit ;
(e) Déterminer le nombre (l) de composantes principales (PCs) ;
(f) Calculer les statistiques de surveillance, du modèle initial, et leurs seuils.
(g) Déterminer les valeurs maximales et minimales du facteur d’oubli (αmin, αmax).
2. Mode en ligne : A chaque instant de mesure,
(a) Obtenir le nouvel échantillon de test x(k), et le normaliser (en utilisant les paramètres
de normalisation de l’instant précédent).
(b) Calculer les indices de surveillance, T2(k) et SPE(k).
(c) Évaluer l’indice de surveillance, si le seuil n’est pas dépassé, la mesure x(k) est consi-
dérée normal (i.e. le système fonctionne proprement). Ainsi, elle sera utilisée pour
mettre à jour le modèle ACP, ensuite passer à l’étape 3 où la condition de mise à jour
est satisfaite. Sinon, l’échantillon de mesure x(k) est biaisé (i.e. naissance d’un dé-
faut). Si, ce dépassement de seuil persiste sur plus de trois échantillons consécutifs,
le système est défaillant, donc passer à l’étape 2.
3. Si la condition de mise à jour est satisfaite :
(a) Mettre à jour les paramètres de normalisation, la moyenne et la variance, selon les
équations (2.106) et (2.107) respectivement.
(b) Mettre à jour les vecteurs propres en fonction de la nouvelle mesure x(k), comme
dans l’équation (2.110).
(c) Calculer les valeurs propres λi correspondantes aux nouveaux vecteurs propres (2.110).
108
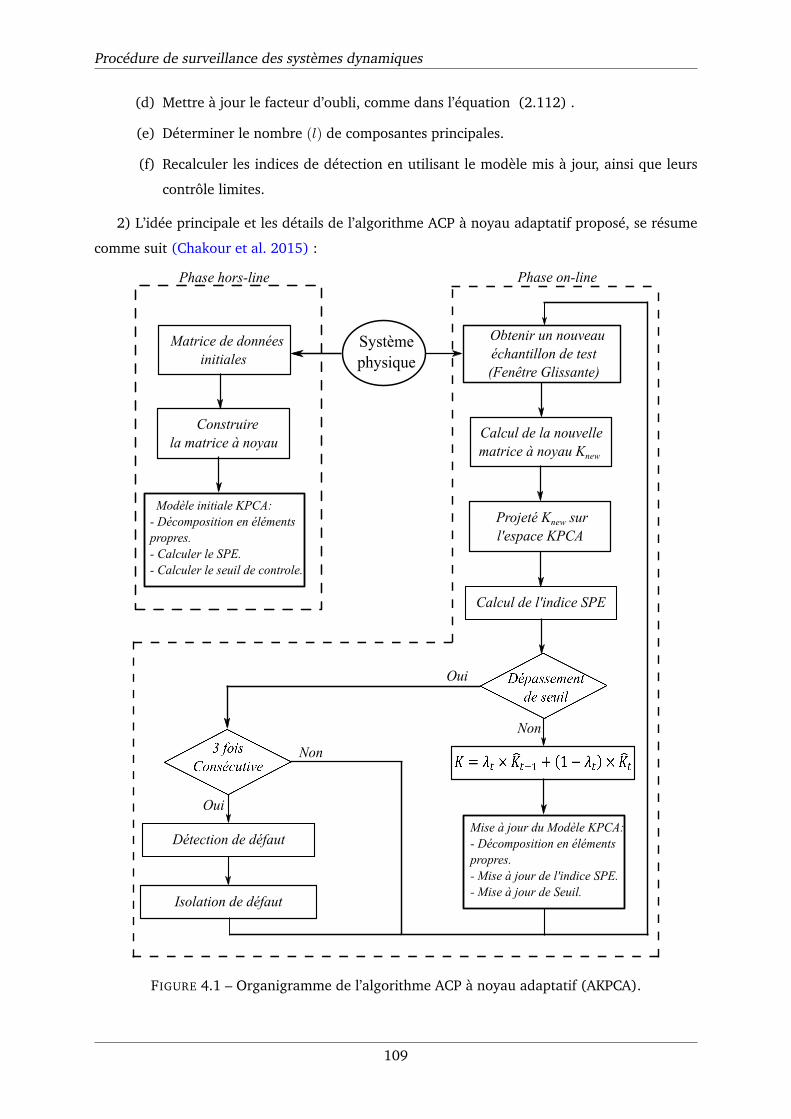
Procédure de surveillance des systèmes dynamiques
(d) Mettre à jour le facteur d’oubli, comme dans l’équation (2.112) .
(e) Déterminer le nombre (l) de composantes principales.
(f) Recalculer les indices de détection en utilisant le modèle mis à jour, ainsi que leurs
contrôle limites.
2) L’idée principale et les détails de l’algorithme ACP à noyau adaptatif proposé, se résume
comme suit (Chakour et al. 2015) :
FIGURE 4.1 – Organigramme de l’algorithme ACP à noyau adaptatif (AKPCA).
109

Procédure de surveillance des systèmes dynamiques
1. Mode hors-ligne :
(a) Acquérir un premier jeu de données Xinit,
(b) Définir les paramètres de la fonction noyau.
(c) Construire la matrice du noyau Kinit, et calculer la matrice noyau centrée (Kinit).
(d) Estimer le modèle KPCA initial (les valeurs et les vecteurs propres de la matrice Kinit).
(e) Calculer les statistiques de surveillance, du modèle initial, et leurs seuils.
(f) Déterminer les valeurs maximales et minimales du facteur d’oubli (βmin, βmax).
2. Mode en ligne :
L’idée de base de la méthode ACP à base de fenêtre glissante consiste à déplacer une
fenêtre le long des données. Elle intègre les nouvelles observations tandis que les plus
anciennes sont exclues.
(a) Obtenir le nouvel échantillon de test x(k) et calculer les paramètres de la fonction
noyau.
(b) Calculer le nouveau vecteur noyau knew et centrer le (knew).
(c) Projeter (knew) dans l’espace KPCA afin d’obtenir son estimé (knew).
(d) Calculer les indices statistiques de surveillance.
(e) Évaluer l’indice de surveillance, si le seuil n’est pas dépassé, la mesure x(k) est consi-
dérée normale (i.e. le système fonctionne proprement). Elle sera utilisée pour mettre
à jour le modèle KPCA, puis passer à l’étape 3 où la condition de mise à jour est sa-
tisfaite. Sinon, l’échantillon de mesure x(k) est biaisé (i.e. naissance d’un défaut). Si,
ce dépassement de seuil persiste sur plus de trois échantillons consécutifs, le système
est défaillant, donc passer à l’étape 2.
3. Si la condition de mise à jour est satisfaite :
(a) Calculer la matrice de Gram adaptative.
K = βk × Kk−1 + (1 − βk) × knewkTnew (4.25)
où βk est un facteur d’oubli flexible.
βk = βmax − (βmax − βmin)[1 − exp
−ϑ(∥Rϕ
k−1∥/∥Rϕnor∥
)n]. (4.26)
(b) Déterminer le nombre (l) de composantes principales.
(c) Mettre à jour le modèle KPCA, calculer les nouvelles valeurs et les nouveaux vecteurs
propres de la matrice de covariance nouvellement adaptée.
110

Procédure de surveillance des systèmes dynamiques
(d) Mettre à jour le facteur d’oubli βk.
(e) Recalculer les indices statistiques de surveillance et leurs seuils correspondants.
3) La stratégie globale de l’algorithme KPCA neuronal que nous avons proposé, pour la
surveillance de processus variable dans le temps se résume comme suit (Chakour et al. 2015b) :
1. Mode hors-ligne :
(a) Acquérir un premier jeu de données Xinit,
(b) Définir les paramètres de la fonction noyau.
(c) Construire la matrice du noyau Kinit, et calculer la matrice noyau centrée (Kinit).
(d) Estimer le modèle KPCA initial (les valeurs et les vecteurs propres de la matrice Kinit).
(e) Calculer les statistiques de surveillance, du modèle initial, et leurs seuils.
(f) Déterminer les valeurs maximales et minimales du facteur d’oubli (βmin, βmax)
2. Mode en ligne :
(a) Obtenir le nouvel échantillon de test x(k), et calculer les paramètre de la fonction
noyau.
(b) Calculer le nouveau vecteur noyau knew et centrez le (knew).
(c) Projeter (knew) dans l’espace KPCA afin d’obtenir son estimé (knew).
(d) Calculer les indices statistiques de surveillance.
(e) Évaluer l’indice de surveillance, si le seuil n’est pas dépassé, la mesure x(k) est consi-
dérée normale (i.e. le système fonctionne proprement). Elle sera utilisée pour mettre
à jour le modèle KPCA, ensuite passer à l’étape 3 où la condition de mise à jour est sa-
tisfaite. Sinon, l’échantillon de mesure x(k) est biaisé (i.e. naissance d’un défaut). Si,
ce dépassement de seuil persiste sur plus de trois échantillons consécutifs, le système
est défaillant, donc passer à l’étape 2.
3. Si la condition de mise à jour est satisfaite :
(a) Calculer les vecteurs propres du nouveau vecteur noyau disponnible knew, en utilisant
l’algorithme KHA.
(b) Ajuster et mettre à jour les vecteurs propres en fonction du nouveau vecteur noyau,
en utilisant l’équation (3.77).
(c) Calculer les valeurs propres λk correspondantes aux nouveaux vecteurs propres ajus-
tés, en utilisant l’équation (3.85).
(d) Recalculer le vecteur gain η(k) de l’algorithme KHA selon l’équation (3.84).
(e) Mettre à jour le facteur d’oubli βk (équation (3.78)).
(f) Déterminer le nombre (l) des composantes principales ;
(g) Recalculer les indices statistiques de surveillance et leurs seuils correspondants.
111

Localisation de défauts
4.5 Localisation de défauts
Une fois qu’un défaut est détecté, il est nécessaire d’identifier les variables qui sont en cause.
Dans la littérature, le thème du diagnostic de défauts n’a pas suscité autant d’intérêt que celui
de la détection de défauts. Le principe général, est de construire en premier lieu un ensemble
de résidus qui dépendent à priori de tous les défauts. Ces résidus sont appelés résidus primaires.
Ils sont ensuite structurés de manière plus évoluée, en les rendant insensibles à certains défauts
(Gertler et al. 1999).
Pour localiser les variables en défauts, plusieurs méthodes utilisant l’analyse en composantes
principales ont été proposées ces dix dernières années. Inspirée des méthodes de localisation à
base de redondance analytique, la localisation de défauts utilisant la structuration des résidus à
partir d’un modèle ACP à été récemment développée. Une extension de cette approche, maxi-
misant la sensibilité des résidus structurés aux défauts, a été proposée par Gertler et al. (1999),
elle utilise une structuration particulière des résidus appelée ACP partielle. Une approche lar-
gement exploitée pour la localisation de défauts avec l’ACP consiste à calculer les contributions
individuelles des variables à l’indice de détection (Nomikos et MacGregor, 1995 ; Yue et Qin,
2001 ; Qin, 2003 ; Alcala et Qin, 2009 ; Kariwala et al., 2010 ; Alcala et Qin, 2011). La variable
ayant la plus forte contribution à l’indice considéré est la variable incriminée. Les contributions
ne permettent pas l’isolation des défauts multiples où plusieurs variables sont simultanément en
défaut en raison de la corrélation entre les variables. Cette corrélation a été la clé d’un diagnos-
tic décisif basé sur l’approche de reconstruction (Dunia et al., 1996 ; Dunia et Qin, 1998b,c,a ;
Yue et Qin, 2001 ; Qin, 2003 ; Alcala et Qin, 2009, 2011). Cette méthode suppose que chaque
capteur qui peut être suspecté est reconstruit. Après la reconstruction de chaque variable un SPE
est calculé. La comparaison du SPE avant et après reconstruction permet de définir la variable
incriminée. Récemment, une nouvelle technique basée sur la contribution par reconstruction
(reconstruction based contribution, RBC) a été proposée par Alcala et Qin, (2009, 2011).
Dans le cas de l’ACP à noyau, les techniques de localisation reposent généralement sur les
méthodes d’estimation de la pré-image, pour ensuite étendre les techniques proposées dans le
cas linéaire, par exemple la localisation par reconstruction et la localisation par structuration des
résidus. Tout récemment en 2011, Alcala et Qin (2011) ont présenté une version de la méthode
des contributions par reconstruction, appliquée au cas non linéaire.
Dans cette partie, nous considérons la détection des défauts simples en utilisant la méthode
de contribution par reconstruction, et l’ACP partielle.
4.5.1 Localisation par calcul des contributions
Le principe des contributions s’appuie généralement sur la quantification de la part de chaque
variable dans le calcul d’un indice de détection donné. Cette méthode est basée sur l’idée que
112

Localisation de défauts
les variables avec les plus grandes contributions à l’indice de détection de défaut sont les plus
susceptibles d’être porteuses du défaut. Elle consiste à déterminer la contribution de chaque
variable à l’indice de détection de défaut utilisé.
Contribution SPE
Les contributions de variables pour l’indice de SPE, qui est la définition proposée par Miller
et al. (1993), sont données par :
cSPEi =
(ξTi Cx(k)
)2
= x2i (4.27)
où, ξi est la i-ième colonne de la matrice d’identité et la direction de xi.
Contribution T2
Les contributions de chaque variable pour l’indice de T2, définies par Wise et al. (2006), sont
données par :
cT2
i =(ξTi D
12 x(k)
)2
(4.28)
Contribution φ
Les contributions de chaque variable pour l’indice φ sont obtenues comme suit :
cφi =(ξTi Ψ
12 x(k)
)2
(4.29)
Cette définition est proposée par Alcala et Qin (2011).
D’après Alcala et Qin (2011), pour tous les indices de détection de défaut, il y a deux pro-
blèmes communs avec la méthode des contributions. En l’absence de défauts, les contributions
des variables dans l’indice de détection, ne sont pas égales. Par conséquent, un défaut dans une
variable qui a une faible contribution dans l’indice de défauts, par rapport aux autres variables,
peut ne pas être détecté, sauf si son amplitude est élevée. Cela peut être une source d’erreur de
diagnostic, avec cette approche. Pour ce fait, la méthode des contributions par reconstruction
présentée par Alcala et Qin (2009), est considérée comme une alternative aux contributions
classiques.
4.5.2 Localisation par contributions à base de reconstruction (RBC)
La méthode de contribution par reconstruction est basée sur une utilisation simultanée du
principe de la contribution et celui de la reconstruction. Cependant, le principe de la méthode
113

Localisation de défauts
de reconstruction est fondé sur l’élimination de l’influence de défauts sur l’indice de détection
par une reconstruction des variables à l’aide d’un modèle ACP. Le principe de la contribution par
reconstruction considère la quantité reconstruite d’un indice de détection le long d’une direction
d’une variable donnée comme étant la contribution d’une telle variable.
Le vecteur de mesures reconstruit le long d’une direction ξi est défini comme suit :
zi = x − ξifi (4.30)
Dunia et Qin (1998a) donnent la reconstruction le long d’une direction arbitraire pour l’in-
dice de détection SPE, et Yue et Qin (2001) donnent les reconstructions pour les indices T2 et φ.
Dans une forme générale, l’indice de détection de défauts de la mesure reconstruite est donné
avec :
Indice(zi) = zTi Mzi = ∥x − ξifi∥2. (4.31)
où, M = C dans le cas du SPE, M = D pour le T2, et M = Ψ pour le cas de l’indice combiné.
La tâche de la reconstruction permet de trouver une valeur fi tel que Indice(zi) est minimisé.
La valeur de fi est calculée comme suit,
fi = (ξTi Mξi)
−1ξTi Mx (4.32)
La contribution par reconstruction de la variable xi dans l’indice de détection de défaut,
RBCIndicei , est la quantité de la reconstruction le long de la direction ξi. Cette quantité peut être
exprimée comme :
RBCIndicei = ∥ξifi∥2 = ∥ξi
(ξTi Mξi
)−1ξTi Mx∥2 (4.33)
= xT Mξi(ξTi Mξi
)−1ξTi Mx. (4.34)
L’indice de detection de défauts reconstruit, Indice(zi), est obtenu en remplaçant la valeur
fi dans l’équation (4.43),
Indice(zi) = xT M[I − ξi(ξT
i Mξi)−1ξTi M]
x (4.35)
= xT Mx − xT Mξi(ξTi Mξi)−1ξT
i Mx (4.36)
= Indice(x) − RBCIndicei (4.37)
donc,
114

Localisation de défauts
Indice(x) = Indice(zi) + RBCIndicei . (4.38)
Dunia et Qin (1998a) utilisent l’indice de détection de défaut, Indice(zi), pour le diagnostic
de pannes, tandis que Alcala et Qin (2011) utilisent la valeur des RBCIndicei pour localiser le
défaut. La variable ayant la plus grande contribution à l’indicateur de détection utilisé est la
variable incriminée.
RBC de l’indice SPE
La contribution par reconstruction de la variable xi à l’indice SPE, RBCSPEi , en remplaçant
M par C dans l’équation (4.34), est donnée comme suit :
RBCSPEi = xT Cξi(ξT
i Cξi)−1ξT
i Cx =(ξT
i Cx)2
cii. (4.39)
où cii = ξTi Cξi est le ieme élément diagonal de C. A partir de l’équation (4.27), la contribution
RBCSPEi peut être exprimée aussi,
RBCSPEi =
x2i
cii=cSPEi
cii. (4.40)
RBC de l’indice T2 et l’indice combiné φ
La contribution par reconstruction de la variable xi à l’indice T2, RBCT2
i , en remplaçant M
par D dans l’équation (4.34), est donnée comme suit :
RBCT2
i = xT Dξid−1ii ξ
Ti Dx =
(ξTi Dx)2
dii
(4.41)
où, dii est le ième élément diagonal de la matrice D.
En ce qui concerne l’indice combiné φ, la valeur RBCφi , est calculée en remplaçant M par Ψ
dans l’équation (4.34), ce qui conduit à,
RBCφi = xT Ψξi
(ξTi Ψξi
)−1ξTi Ψx =
(ξTi Ψx)2
ψii
(4.42)
où, ψii est le ième élément diagonal de la matrice Ψ.
4.5.3 Localisation par ACP partielle
L’ACP partielle est une technique de localisation associée aux méthodes de localisation ba-
sées sur la structuration des résidus. Gertler et al. (1999) ont introduit en premier la méthode
de localisation basée sur la structuration des résidus. Cette approche consiste à chercher une
115

Localisation de défauts
transformation W de telle sorte que chaque résidu transformé soit sensible à certains défauts et
insensible à d’autres ; le but est d’obtenir, pour chaque défaut, une signature théorique permet-
tant de localiser la variable en défaut. Une autre approche de structuration des résidus proposée
par Huang et al. (1999) consiste à utiliser des ACP partielle (ACP avec un nombre réduit de
variables). L’ACP partielle utilise des bancs de modèles ACP avec des ensembles de variables
réduits et différents d’un modèle à un autre.
L’ACP est appliquée sur un vecteur de données, réduit où quelques variables sont écartées
par rapport au vecteur originel. Les résidus deviennent alors sensibles uniquement aux défauts
associés aux variables qui forment le vecteur réduit, et insensibles aux défauts associés aux
variables éliminées. En fait, ces résidus structurés sont générés selon une matrice d’incidence
adéquatement conçue. Bien que les modèles partiels soient construits uniquement en fonction
de l’occurrence des défauts dans les résidus, il est primordial de s’assurer que les modèles éla-
borés ont la capacité de détection de défauts.
La procédure permettant de structurer les résidus est comme suit (Harkat, 2003) :
1. Effectuer une ACP standard à la matrice des données.
2. Construire une matrice d’incidence fortement localisable (Matrice de signatures théo-
riques).
3. Construire un ensemble de modèles d’ACP partielles, chacune correspondant à une ligne
de la matrice d’incidence (prendre les variables ayant un 1 sur cette ligne).
4. Déterminer les seuils pour la détection des défauts.
Le test de la procédure de localisation de défauts en utilisant l’ACP partielle est donné comme
suit :
1. Acquérir un nouveau jeu de données de test.
2. Calculer le SPE pour chacune des ACP partielles.
3. Comparer les indices aux seuils appropriés et former la signature expérimentale du défaut
Sei : Sei = 0 si SPEi 6 seuil(i) et,
Sei = 1 si SPEi > seuil(i),
4. Comparer la signature expérimentale du défaut aux colonnes de la matrice d’incidence
pour arriver à une décision de localisation.
En se basant sur cette idée, Huang et al. (2000) ont proposé une extension de la méthode
ACP non linéaire structurée, où chaque modèle ACP partiel est représenté par un réseau neu-
ronal auto-associatif à cinq couches. Cependant, les modèles de l’ACP partielle non linéaires
construits par des réseaux de neurones sont très compliqués et leur apprentissage est difficile.
116
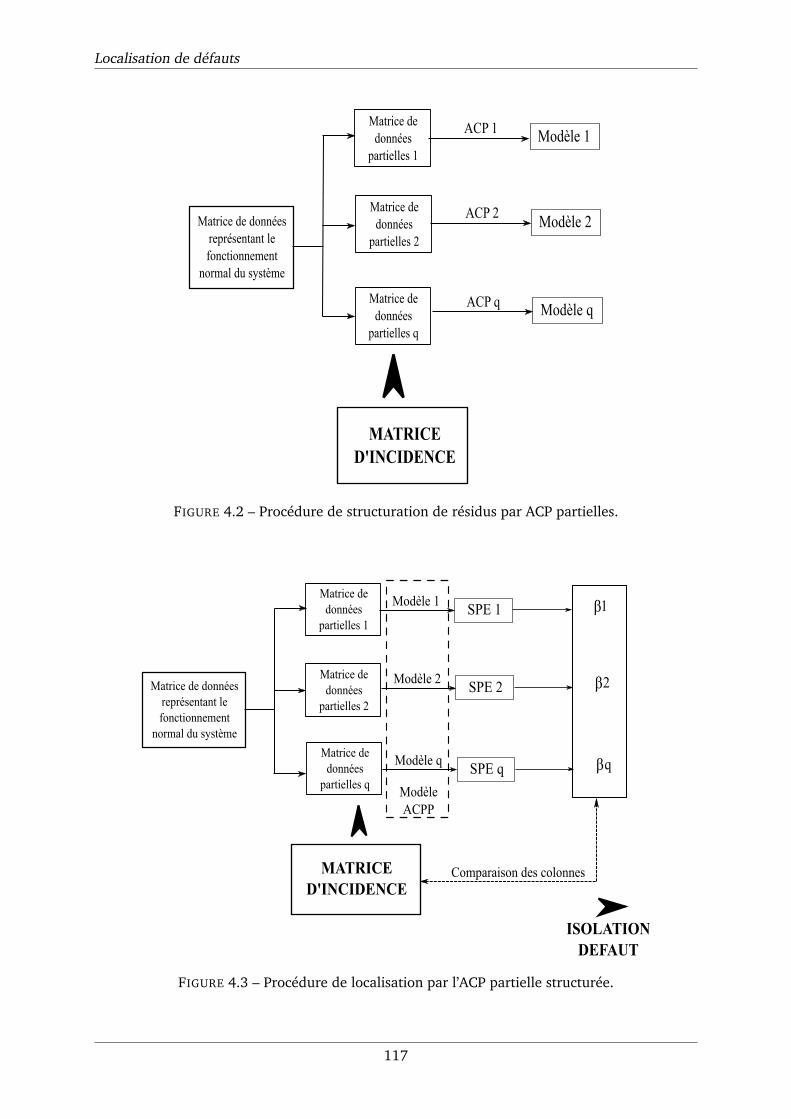
Localisation de défauts
Matrice de données
représentant le
fonctionnement
normal du système
Matrice de
données
partielles 1
MATRICE
D'INCIDENCE
ACP 1Modèle 1
ACP 2
ACP q
Modèle 2
Modèle q
Matrice de
données
partielles 2
Matrice de
données
partielles q
FIGURE 4.2 – Procédure de structuration de résidus par ACP partielles.
FIGURE 4.3 – Procédure de localisation par l’ACP partielle structurée.
117

Localisation dans le cas du noyau par RBC-KPCA
Dans le même contexte, l’extension de l’analyse en composantes principales partielles dans l’es-
pace à noyaux est introduite aussi comme une technique non linéaire de structuration de résidus.
Similairement à la procédure présentée ci-dessus, un ensemble de modèles KPCA sont construits
sur des ensembles réduits de données, structurés, et qui sont définies par la matrice d’incidence.
4.6 Localisation dans le cas du noyau par RBC-KPCA
La méthode de contribution fondée sur la reconstruction, et discutée dans la partie précé-
dente, définit la reconstruction d’un indice de détection de défaut le long de la direction d’une
variable comme étant la contribution de cette variable. L’objectif de RBC est de trouver l’am-
plitude fi d’un vecteur de direction ξi telle que l’indice de détection de défaut de la mesure
reconstruite est minimisée.
zi = x − ξifi (4.43)
Le même concept peut être appliqué à l’ACP à noyau afin de trouver la valeur de fi qui
minimise l’indice de détection associé.
fi = arg min Indice(x − ξifi) (4.44)
D’après l’équation (4.38), la valeur des RBCi est également la différence entre les indices
de détection de la mesure x défectueuse et la mesure zi reconstruite. En raison de la nature de
la méthode KPCA, la valeur RBC ne peut être calculée comme indice de détection de fiξi, mais,
elle peut être calculée seulement comme la différence entre les indices de détection de la mesure
défectueuse et reconstruite. C’est l’approche utilisée pour calculer les valeurs des contributions
lorsqu’il s’agit de l’ACP à noyau.
RBCIndicei = Indice(x) − Indice(zi). (4.45)
Si nous voulons faire la reconstruction le long de la direction d’une variable donnée, la
direction peut être écrite comme ξi = [1 0 0 · · · 0], où 1 est placé à la ième position.
Afin de trouver la valeur RBC le long d’une direction ξi, pour un indice de détection de
défaut, nous devons effectuer une recherche non linéaire de la valeur fi qui minimise Indice(x−
ξifi). Deux méthodes sont étudiées dans Alcala (2011). L’une de ces méthodes, est l’algorithme
itératif du point fixe qui calcule la valeur fi de façon itérative simple, mais il ne fournit pas de
place pour l’analyse de la convergence. L’autre est l’algorithme d’optimisation de Newton, qui
est en mesure de fournir les conditions dans lesquelles l’algorithme converge.
118

Localisation dans le cas du noyau par RBC-KPCA
4.6.1 Algorithme itératif du point fixe
L’équation (4.44) peut être résolue par l’obtention de la première dérivée de l’indice de
détection de défaut par rapport à fi égale à zero. Toutefois, l’expression résultante n’est pas
une solution explicite pour fi, elle doit être répétée jusqu’à ce que fi converge. La dérivée de
l’expression de fi pour l’indice général de détection dans le cas non linéaire à noyau de l’ACP,
est donneée comme suit :
fi =ξTi BT [a1n + Mk(zi)]
kT (zi)[a1n + Mk(zi)](4.46)
où, le paramètre a = 1 lorsque l’indice utilisé est le SPE, a = 0 pour le T2, ainsi égale à 1δ2 pour
l’indice combiné.
La matrice B est donnée par,
B =
k(zi, x1)(x − x1)
T
k(zi, x2)(x − x2)T
...
k(zi, xn)(x − xn)T
(4.47)
La dérivation détaillée de f est donnée dans Alcala (2011). Dans le prochain paragraphe,
fi est calculé avec la méthode d’optimisation de Newton, et une analyse de sa convergence est
réalisée.
4.6.2 Méthode d’optimisation de Newton
Dans le procédé d’optimisation de Newton, fi est mise à jour en tant que :
f j+1i = f j
i − g′(f ji )
g′′(f ji )
(4.48)
avec, les termes g′(f ji ) et g′′(f j
i ) représentant la première et la seconde dérivation de Indice(x−
ξifi) par rapport à fi, respectivement. Celles-ci sont calculées ainsi,
g′(f ji ) =
−4
c
[a1n + Mk(zi)
]TQk(zi). (4.49)
g′′(f ji ) =
8
c2[a1n + Mk(zi)
]T ( c2− I − Q2
)k(zi) +
8
c2k(zi)
T QMQk(zi). (4.50)
où, le paramètre c est le coefficient de mise à l’échelle (dispersion) de la fonction noyau. Pour
des raisons de convergence, cet algorithme exige une valeur très grande de ce paramètre. Ainsi,
la matrice Q est définie comme suit,
119

Conclusion
Q =
(x − x1)
T ξi − fi 0 . . . 0
0 (x − x2)T ξi − fi . . . 0
...... . . . ...
0 0 . . . (x − xn)T ξi − fi
(4.51)
Après développement mathématique, discuté en détail dans Alcala (2011), en remplaçant les
deux dérivés dans l’expression (4.48) de fi, on obtient :
f j+1i = f j
i −[a1n + Mk(zi)
]TQk(zi)[
a1n + Mk(zi)]T
k(zi)(4.52)
=
[a1n + Mk(zi)
]T (f j
i I − Q)
k(zi)[a1n + Mk(zi)
]Tk(zi)
(4.53)
De même que pour le cas de la méthode du point fixe, cette expression peut être écrite sous
la forme suivante,
f j+1i =
[a1n + Mk(zi)
]TBξi[
a1n + Mk(zi)]T
k(zi)(4.54)
avec, Bξi =(f j
i I − Q)
k(zi).
Enfin, l’algorithme du point fixe est un cas particulier de l’algorithme de Newton.
4.7 Conclusion
Ce chapitre a été consacré à la détection et localisation de défauts par analyse en compo-
santes principales linéaires dans une première partie. Les indices de détection de défauts qui
sont souvent utilisés dans le cas de l’ACP linéaire, ont été présentés. La statistique T2 de Hotel-
ling calculée à partir des premières composantes principales et l’erreur quadratique d’estimation
SPE, ainsi que l’indice combiné de ces deux derniers, sont aussi exposés. Les procédures de dé-
tection et de surveillance des systèmes dynamiques en temps réel ont été explicitées. A cette
fin, trois algorithmes, sur les stratégies de surveillance ont été proposés. Le premier, concerne
l’ACP adaptative linéaire, tandis que le deuxième et le troisième sont focalisés sur l’ACP à noyau,
adaptative.
Pour la localisation de défaut, plusieurs approches ont été exposées. La première est d’es-
sence classique, utilisant les bancs de modèles, comme l’ACP partielle, exploitant des ensembles
réduit de variables. La seconde s’appuie sur le calcul des contributions des variables à l’indice
120

Conclusion
de détection. La dernière fait la combinaison entre la méthode de calcul des contributions et
celle qui repose sur le principe de la reconstruction, appelée méthode de reconstruction à base
de contribution (RBC).
Dans la deuxième partie de ce chapitre, la détection et localisation de défauts par analyse en
composantes principales non-linéaires à noyau sont présentés. Les trois indices utilisés dans la
détection de déauts dans le cas linéaire ont été étendu à l’ACP à noyau. L’extension des méthodes
de localisation de défauts du cas linéaire au cas non linéaire de l’ACP à noyau n’est toujours pas
vérifiée. Cette tache, repose généralement sur les méthodes non linéaires d’estimation de la pré-
image. Dans notre cas, on a utilisé la méthode de localisation par l’ACP à noyaux partielles et la
méthode de reconstruction à base de contribution.
Le chapitre suivant est consacré à la mise en évidence de l’intérêt de l’application de l’ACP
dans les domaines de surveillance et de diagnostic dans les systèmes industriels.
121

Chapitre 5Application
Sommaire5.1 Exemple illustratif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
5.2 Application au processus de Tennessee Eastman (TE) . . . . . . . . 131
5.2.1 Description du TE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
5.2.2 Résultats de simulation . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
5.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
5.1 Exemple illustratif
Nous présentons dans cette section l’application de la méthode ACP sur un exemple de syn-
thèse. Les différents principes exposés précédemment sont appliqués pour montrer leur intérêt
et aussi bien expliciter leur mise en œuvre.
Soit un système statique représenté par six (06) variables obtenues à partir d’une combinai-
son linéaire de deux signaux, u1 et u2 sous forme de créneaux. L’amplitude de ces variables se
situe dans une plage de variation comprise entre -2 et +2, et elles sont entachées de bruit blanc,
uniformément réparti εi. Le système est alors décrit par les équations suivantes :
x1 = u1(t) + ε1
x2 = u2(t) + ε2
x3 = x1(t) + 2 ∗ u2(t− 1) + ε3
x4 = x1(t) + 0.7 ∗ x2(t) + ε4
x5 = u1(t− 1) + 3 ∗ u2(t− 2) + ε5
x6 = u1(t− 1) + ε6
122
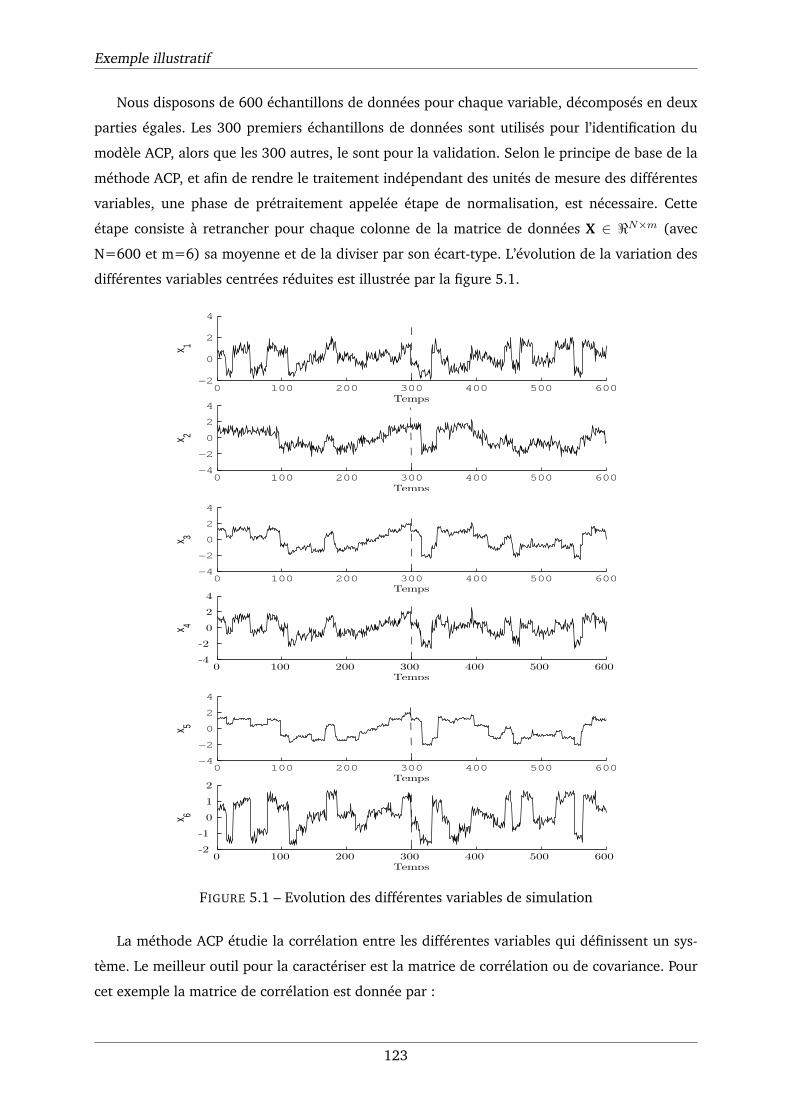
Exemple illustratif
Nous disposons de 600 échantillons de données pour chaque variable, décomposés en deux
parties égales. Les 300 premiers échantillons de données sont utilisés pour l’identification du
modèle ACP, alors que les 300 autres, le sont pour la validation. Selon le principe de base de la
méthode ACP, et afin de rendre le traitement indépendant des unités de mesure des différentes
variables, une phase de prétraitement appelée étape de normalisation, est nécessaire. Cette
étape consiste à retrancher pour chaque colonne de la matrice de données X ∈ ℜN×m (avec
N=600 et m=6) sa moyenne et de la diviser par son écart-type. L’évolution de la variation des
différentes variables centrées réduites est illustrée par la figure 5.1.
0 100 200 300 400 500 600−2
0
2
4
Temps
x 1
0 100 200 300 400 500 600−4
−2
0
2
4
Temps
x 2
0 100 200 300 400 500 600−4
−2
0
2
4
x 3
Temps
0 100 200 300 400 500 600-4
-2
0
2
4
x 4
Temps
0 100 200 300 400 500 600−4
−2
0
2
4
x 5
Temps
0 100 200 300 400 500 600-2
-1
0
1
2
x 6
Temps
FIGURE 5.1 – Evolution des différentes variables de simulation
La méthode ACP étudie la corrélation entre les différentes variables qui définissent un sys-
tème. Le meilleur outil pour la caractériser est la matrice de corrélation ou de covariance. Pour
cet exemple la matrice de corrélation est donnée par :
123

Exemple illustratif
Σ =
1 −0.04 0.35 0.75 0.17 0.85
−0.04 1 0.84 0.62 0.85 −0.03
0.35 0.84 1 0.83 0.94 0.32
0.75 0.62 0.83 1 0.70 0.64
0.17 0.85 0.94 0.70 1 0.23
0.85 −0.03 0.32 0.64 0.23 1
(5.1)
Il s’agit maintenant d’identifier les vecteurs et valeurs propres de cette matrice, qui sont
respectivement les directions du nouvel espace orthonormé et les variances correspondant à la
projection des données X sur ces directions. Les matrices des valeurs et vecteurs propres sont
données respectivement par :
Λ =
3.80 0 0 0 0 0
0 1.83 0 0 0 0
0 0 0.21 0 0 0
0 0 0 0.12 0 0
0 0 0 0 0.02 0
0 0 0 0 0 0.00
(5.2)
P =
0, 30 0, 57 0, 39 0, 29 −0, 18 0, 54
0, 38 −0, 45 0, 18 −0, 62 −0, 01 0, 46
0, 48 −0, 20 −0, 02 0, 41 0, 74 0.00
0, 49 0, 14 0, 43 −0, 18 −0, 15 −0, 69
0, 44 −0, 30 −0, 46 0, 37 −0, 59 0.00
0, 29 0, 55 −0, 63 −0, 41 0, 16 0.00
(5.3)
Maintenant, une fois que les directions du nouvel sous-espace orthonormé sont définies, on
effectue un changement de base qui permet de projeter les variables inter-corrélées (x1, x2, ..., x6)
sur les directions P . Un autre nombre de variables réduites expliquent au mieux la variabilité
des données originales est obtenu. Ces nouvelles variables sont appelées composantes princi-
pales ti. Leur évolution est alors tracée dans la figure 5.2.
Après la phase de diagonalisation de la matrice de corrélation, il faudra passer à l’étape
de détermination des composantes principales. Cette phase est très importante puisqu’elle est
directement liée à l’élaboration de la structure optimale du modèle.
Après avoir présenté la phase de diagonalisation de la matrice de corrélation, la détermina-
tion du nombre de composantes principales est une étape cruciale dans la méthode ACP, puis-
qu’elle permet d’identifier la structure optimale du modèle. Les figures 5.3, 5.4 et 5.5 montrent
124
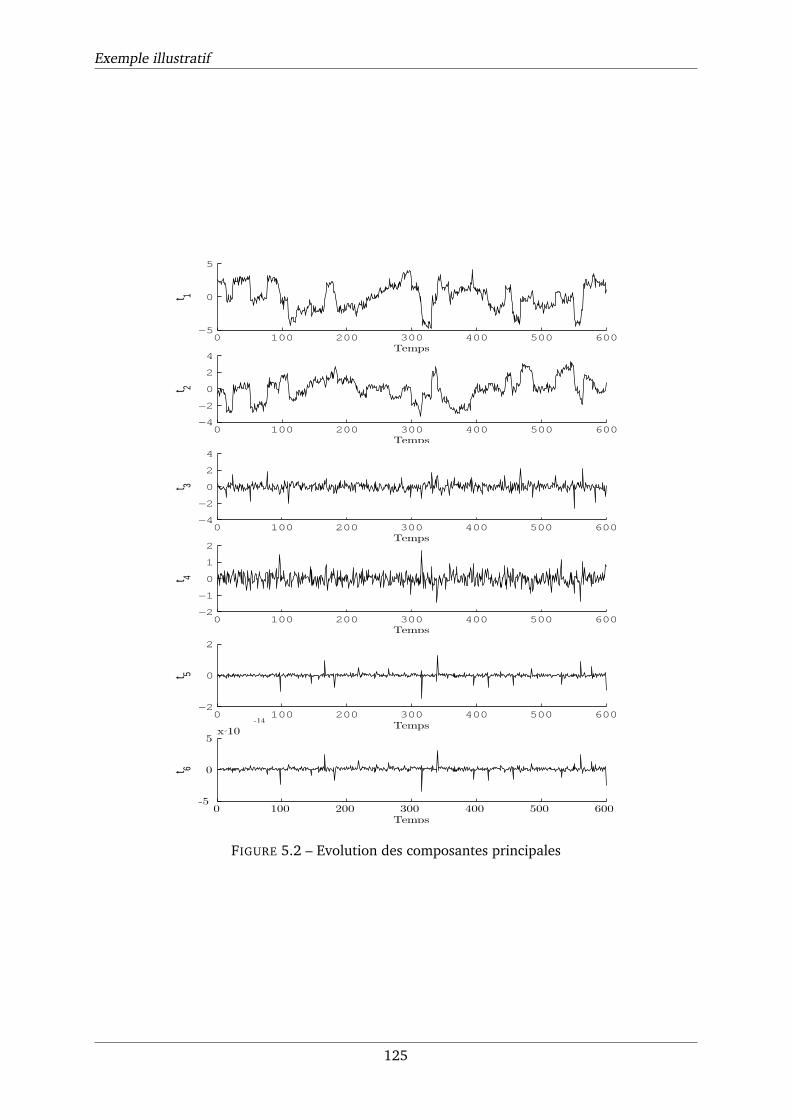
Exemple illustratif
0 100 200 300 400 500 600−5
0
5
Temps
t 1
0 100 200 300 400 500 600−4
−2
0
2
4
Temps
t 2
0 100 200 300 400 500 600−4
−2
0
2
4
Temps
t 3
0 100 200 300 400 500 600−2
−1
0
1
2
Temps
t 4
0 100 200 300 400 500 600−2
0
2
t 5
Temps
0 100 200 300 400 500 600-5
0
5x 10
-14
t 6
Temps
FIGURE 5.2 – Evolution des composantes principales
125

Exemple illustratif
les trois (03) approches fréquemment rencontrées dans la littérature pour la sélection du nombre
de composantes principales. On remarque que le nombre de composantes à retenir est égal à
deux pour l’ensemble des critères représentés.
Tout en respectant l’idée de base de la méthode ACP, c’est à dire avoir une représentation
réduite et optimale de l’information, les composantes principales retenues correspondent seule-
ment aux directions de plus grande dispersion dont la variation maximale des données initiales
est satisfaite. Comme pour le cas de la méthode du pourcentage cumulé (PCV), la figure illustre
qu’à partir de la deuxième composante principale, on capture presque une variance maximale
de 95% de la variance totale de données. Le même cas pour la méthode des validations croisées,
il est montré que la quantité PRESS diminue en fonction du nombre de composantes. Tout en
conservant le minimum de composantes principales, la variation maximale des données, PRESS
donne un nombre de composantes principales minimal égal à deux. Le critère VNR (Variance
Non Reconstruite) donne le même nombre de composantes principales comme les deux critères
précédents. Cependant ce critère est plus intéressant pour des objectifs de diagnostic de dé-
fauts, car il tient compte de la redondance existante entre les différentes variables en utilisant
le principe de reconstruction.
Le modèle ACP est identifié une fois que le nombre optimal de composantes principales l est
déterminé. La matrice qui caractérise ce modèle est donnée comme suit :
C =
0.42 −0.14 0.03 0.23 −0.03 0.40
−0.14 0.35 0.27 0.12 0.30 −0.14
0.03 0.27 0.27 0.20 0.27 0.03
0.23 0.12 0.20 0.26 0.17 0.22
−0.03 0.30 0.27 0.17 0.29 −0.03
0.40 −0.14 0.03 0.22 −0.03 0.39
(5.4)
Pour tester le modèle reconstruit, un jeu de données de validation de 300 échantillons est
utilisé. En fait, la matrice des observations X peut être donc estimée à partir des l composantes
principales sélectionnées (l = 2) correspondantes aux l plus grandes valeurs propres (porteuses
de l’information) de la matrice de covariance. L’évolution des données et leur estimation est
illustré par la figure 5.6. Pour le reste des (m − l) composantes, constituant l’espace résiduel,
elles ne retiennent que les bruits de mesure des différentes variables, et sont très utiles pour
diagnostiquer les défauts. La matrice qui décrit le modèle résiduel est :
126
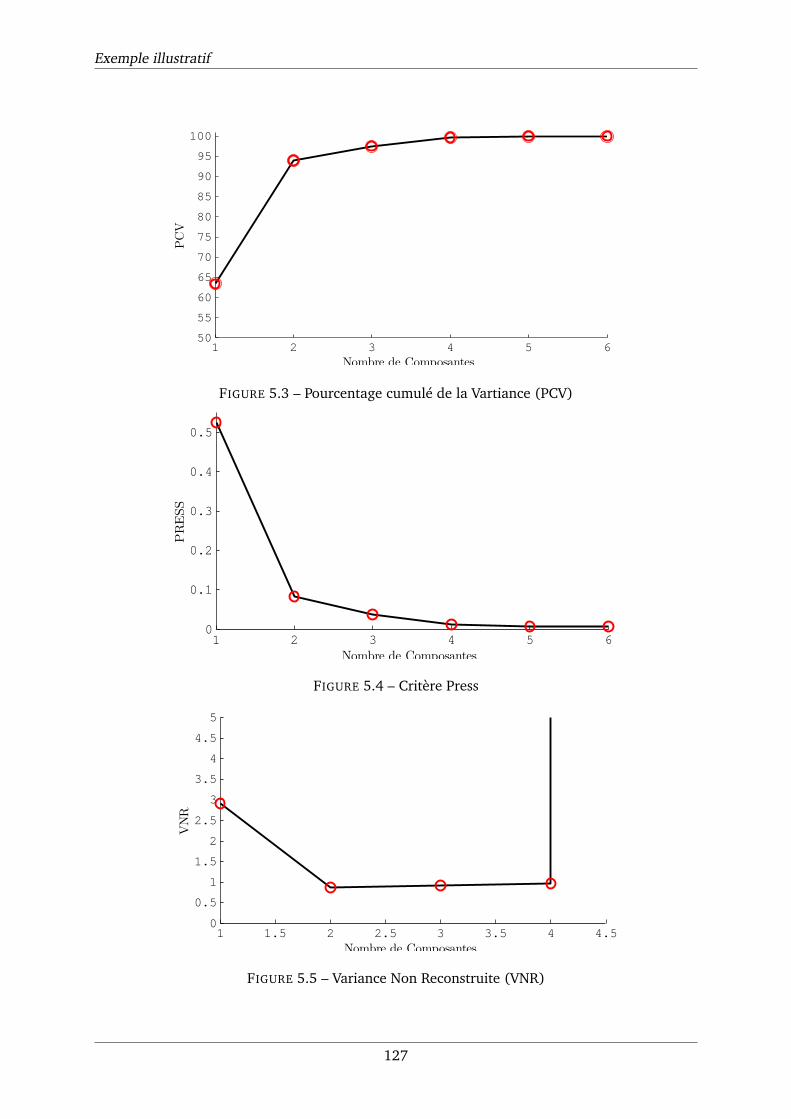
Exemple illustratif
1 2 3 4 5 650
55
60
65
70
75
80
85
90
95
100
Nombre de Composantes
PC
V
FIGURE 5.3 – Pourcentage cumulé de la Vartiance (PCV)
1 2 3 4 5 60
0.1
0.2
0.3
0.4
0.5
Nombre de Composantes
PR
ESS
FIGURE 5.4 – Critère Press
1 1.5 2 2.5 3 3.5 4 4.50
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
Nombre de Composantes
VN
R
FIGURE 5.5 – Variance Non Reconstruite (VNR)
127
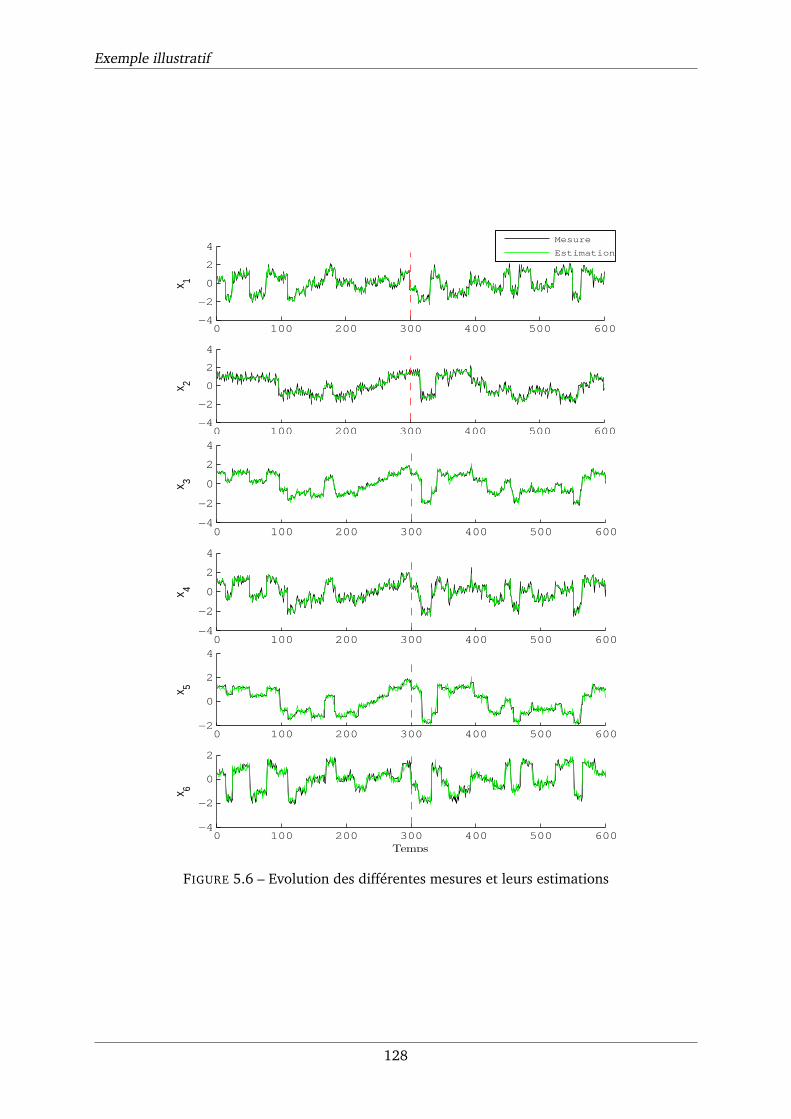
Exemple illustratif
0 100 200 300 400 500 600−4
−2
0
2
4
x 1
0 100 200 300 400 500 600−4
−2
0
2
4
x 2
Mesure
Estimation
0 100 200 300 400 500 600−4
−2
0
2
4
x 3
0 100 200 300 400 500 600−4
−2
0
2
4
x 4
0 100 200 300 400 500 600−2
0
2
4
x 5
0 100 200 300 400 500 600−4
−2
0
2
x 6
Temps
FIGURE 5.6 – Evolution des différentes mesures et leurs estimations
128

Exemple illustratif
C =
0.57 0.14 −0.03 −0.23 0.03 −0.40
0.14 0.64 −0.27 −0.12 −0.30 0.14
−0.03 −0.27 0.72 −0.20 −0.27 −0.03
−0.23 −0.12 −0.20 0.73 −0.17 −0.22
0.03 −0.30 −0.27 −0.17 0.70 0.03
−0.40 0.14 −0.03 −0.22 0.03 0.60
(5.5)
On peut remarquer sur la figure 5.6 que les estimations sont conformes aux données initiales
ainsi que les erreurs d’estimation de toutes les variables sont presque nulles. Ceci montre que
le modèle ACP donne une estimation assez correcte des différentes mesures en utilisant deux
composantes principales.
Pour bien montrer la sensibilité du modèle au nombre de composantes principales l, on a
réduit ce nombre à 1, et on reprend la même procédure. Après avoir reconstruit le modèle en
utilisant une seule composante dans le sous-espace principal, une projection des données dans ce
dernier est effectuée ainsi qu’une estimation des différentes variables est obtenue. L’estimation
ou la reconstruction de ces variables en utilisant ce modèle réduit est illustrée par la figure 5.7.
Elle montre les limitations du modèle pour reconstruire ou estimer toute la variation de la
matrice de données X. L’ensemble des variables x1 et x6 ne sont pas bien modélisés à cause
du manque d’information dans le sous-espace principal. La seconde composante contenant de
l’information utile sur les variables x1 et x6, est projetée dans le sous espace résiduel. Ce der-
nier, donc, ne comporte pas seulement que des bruits mais aussi de l’information. Cette quan-
tité de l’information projetée dans le sous espace résiduel représente l’erreur de modélisation.
D’après l’approche du pourcentage de la variance cumulée, l’information couverte par un mo-
dèle construit à partir d’une seule composante est de 63% de l’information globale de données.
Donc plus de 36% de l’information est projetée dans l’espace résiduel, ce qui rend le modèle ACP
incapable de couvrir ou d’estimer presque 37% de la variation totale de variables. En l’absence
de défauts, des résidus entachés d’erreurs de modélisation vont engendrer non seulement des
fausses alarmes mais aussi la non détection des défauts de faible amplitude. Ceci, influence la
sensibilité de détection de la méthode ACP.
Dans cette partie une description détaillée du principe de modélisation à base de la méthode
ACP a été explicitée. Les différentes démarches à suivre pour disposer d’un bon modèle ACP ont
été présentées. Un exemple de simulation défini avec six (06) variables inter-corrélées linéaire-
ment, a permis de montrer l’intérêt de la méthode ACP, pour modéliser les comportements des
systèmes réels. Mais la plupart des processus industriels sont dynamiques, et leurs comporte-
ments et/ou leurs caractéristiques statistiques varient dans le temps. De ce fait, la méthode ACP
statique, peut s’avérer incapable d’offrir des résultats probants. C’est pourquoi, nous consacrons
la prochaine partie à cette problématique, de la prise en charge de cette réalité par l’ACP.
129
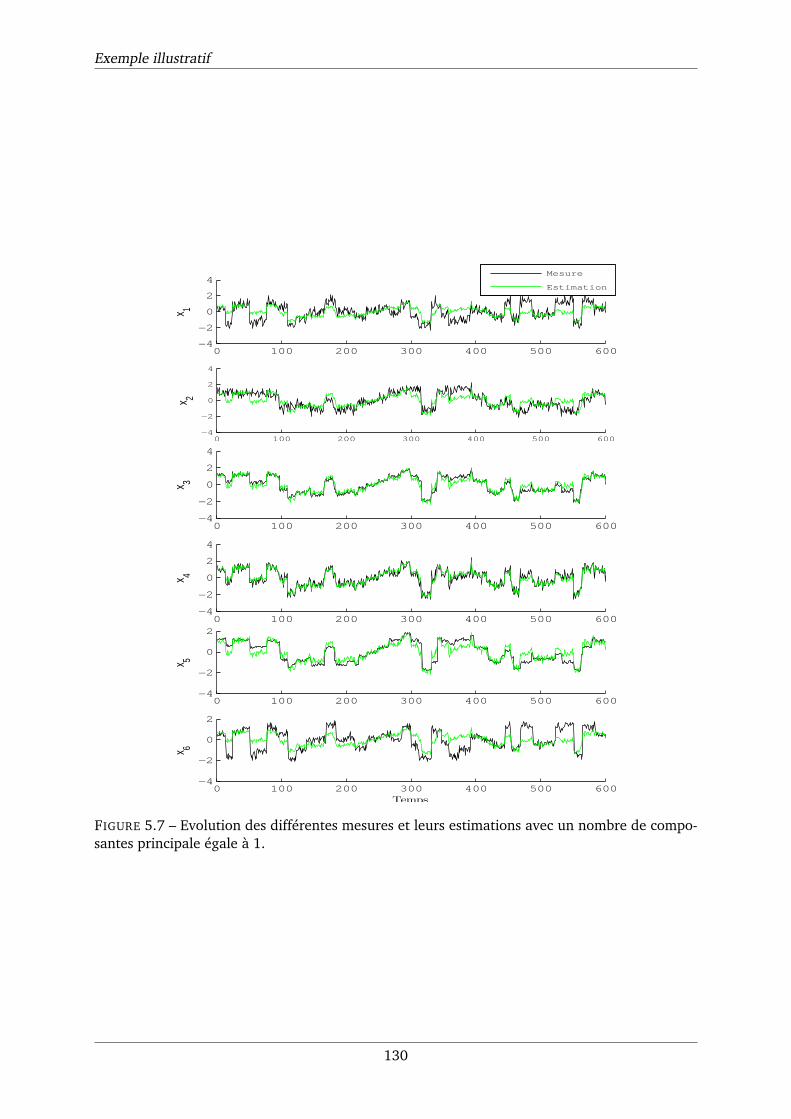
Exemple illustratif
0 100 200 300 400 500 600−4
−2
0
2
4
x 1
0 100 200 300 400 500 600−4
−2
0
2
4
x 2
Mesure
Estimation
0 100 200 300 400 500 600−4
−2
0
2
4
x 3
0 100 200 300 400 500 600−4
−2
0
2
4
x 4
0 100 200 300 400 500 600−4
−2
0
2
x 5
0 100 200 300 400 500 600−4
−2
0
2
x 6
Temps
FIGURE 5.7 – Evolution des différentes mesures et leurs estimations avec un nombre de compo-santes principale égale à 1.
130

Application au processus de Tennessee Eastman (TE)
5.2 Application au processus de Tennessee Eastman (TE)
5.2.1 Description du TE
Le simulateur du processus chimique Tennesse Estman Challange Process (TE), est considéré
comme une installation pilote de l’industrie chimique conçue par Eastman company. Il est lar-
gement utilisé par la communauté scientifique pour évaluer les performances des algorithmes
de commande et de diagnostic. Le TE est un réacteur chimique non linéaire et de grande di-
mension. Ce processus fournit les produits chimiques finis G et H à partir de quatre réactifs A
, C, D et E. L’installation possède 7 modes de fonctionnement opératoires, 41 variables mesu-
rées et 12 variables manipulées. De plus, il existe 20 perturbations IDV1 à IDV20 qui peuvent
être simulées pour perturber le fonctionnement du système. Les 41 variables mesurées sont un
mélange de signaux continus et discrets, 22 variables sont continues (chaque seconde) et le
reste, 19 variables sont les mesures de concentration de l’alimentation du réacteur, avec diffé-
rentes fréquences d’échantillonnage de 6 ou 15 minutes. Ce processus représente un défi pour
la communauté scientifique, sur l’identification, la commande et la surveillance des procéssus
industriels. Un diagramme simplifié du processus est montré sur la figure (5.8).
FIGURE 5.8 – Processus de Tennessee Eastman
Dans ce travail, les premières 16 variables mesurées d’une façon continue sont utilisées pour
construire la matrice des données. Ces variables sont listées dans le tableau (5.1). L’ACP adap-
tative, la MWPCA et la EWPCA du cas linéaire, ainsi que l’ACP non linéaire à noyau adaptative,
la MWKPCA, la RKPCA et la NKPCA sont utilisées pour modéliser ces données et diagnostiquer
leurs défauts. Une étude comparative entres ces différentes techniques est proposée.
131

Application au processus de Tennessee Eastman (TE)
Nvar Description des variables Unité
x1 Débit d’alimentation en A Kscmh
x2 Température du réacteur C
x3 Débit d’alimentation en E kgh−1
x4 Débit d’alimentation total Kscmh
x5 Débit de recyclage Kscmh
x6 Débit d’alimentation du réacteur Kscmh
x7 Débit d’alimentation an D kgh−1
x8 Pression du réacteur kPa
x9 Niveau du réacteur %
x10 Débit de purge Kscmh
x11 Température du séparateur C
x12 Pression du séparateur kPa
x13 Débit du séparateur m3h−1
x14 Niveau de purification %
x15 Pression du purificateur kPa
x16 Débit du purificateur m3h−1
TABLE 5.1 – Les variables sélectionnées pour l’application
132
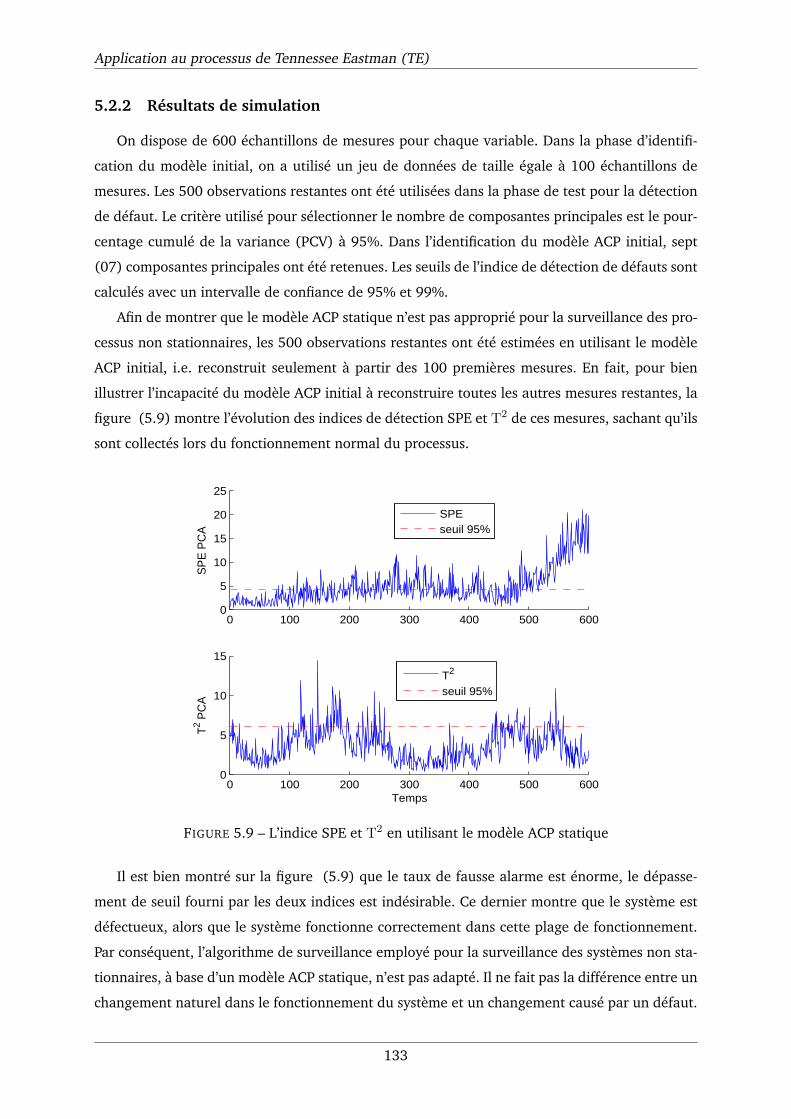
Application au processus de Tennessee Eastman (TE)
5.2.2 Résultats de simulation
On dispose de 600 échantillons de mesures pour chaque variable. Dans la phase d’identifi-
cation du modèle initial, on a utilisé un jeu de données de taille égale à 100 échantillons de
mesures. Les 500 observations restantes ont été utilisées dans la phase de test pour la détection
de défaut. Le critère utilisé pour sélectionner le nombre de composantes principales est le pour-
centage cumulé de la variance (PCV) à 95%. Dans l’identification du modèle ACP initial, sept
(07) composantes principales ont été retenues. Les seuils de l’indice de détection de défauts sont
calculés avec un intervalle de confiance de 95% et 99%.
Afin de montrer que le modèle ACP statique n’est pas approprié pour la surveillance des pro-
cessus non stationnaires, les 500 observations restantes ont été estimées en utilisant le modèle
ACP initial, i.e. reconstruit seulement à partir des 100 premières mesures. En fait, pour bien
illustrer l’incapacité du modèle ACP initial à reconstruire toutes les autres mesures restantes, la
figure (5.9) montre l’évolution des indices de détection SPE et T2 de ces mesures, sachant qu’ils
sont collectés lors du fonctionnement normal du processus.
0 100 200 300 400 500 6000
5
10
15
20
25
SP
E P
CA
0 100 200 300 400 500 6000
5
10
15
Temps
T2 P
CA
SPEseuil 95%
T2
seuil 95%
FIGURE 5.9 – L’indice SPE et T2 en utilisant le modèle ACP statique
Il est bien montré sur la figure (5.9) que le taux de fausse alarme est énorme, le dépasse-
ment de seuil fourni par les deux indices est indésirable. Ce dernier montre que le système est
défectueux, alors que le système fonctionne correctement dans cette plage de fonctionnement.
Par conséquent, l’algorithme de surveillance employé pour la surveillance des systèmes non sta-
tionnaires, à base d’un modèle ACP statique, n’est pas adapté. Il ne fait pas la différence entre un
changement naturel dans le fonctionnement du système et un changement causé par un défaut.
133
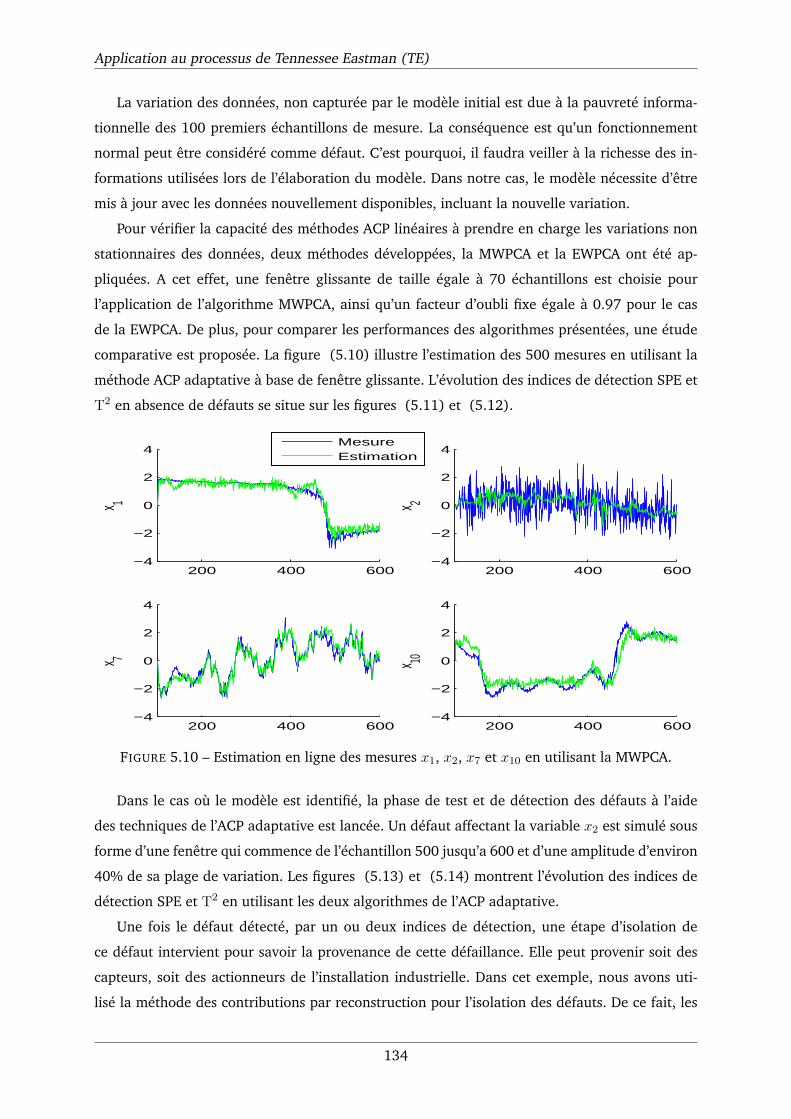
Application au processus de Tennessee Eastman (TE)
La variation des données, non capturée par le modèle initial est due à la pauvreté informa-
tionnelle des 100 premiers échantillons de mesure. La conséquence est qu’un fonctionnement
normal peut être considéré comme défaut. C’est pourquoi, il faudra veiller à la richesse des in-
formations utilisées lors de l’élaboration du modèle. Dans notre cas, le modèle nécessite d’être
mis à jour avec les données nouvellement disponibles, incluant la nouvelle variation.
Pour vérifier la capacité des méthodes ACP linéaires à prendre en charge les variations non
stationnaires des données, deux méthodes développées, la MWPCA et la EWPCA ont été ap-
pliquées. A cet effet, une fenêtre glissante de taille égale à 70 échantillons est choisie pour
l’application de l’algorithme MWPCA, ainsi qu’un facteur d’oubli fixe égale à 0.97 pour le cas
de la EWPCA. De plus, pour comparer les performances des algorithmes présentées, une étude
comparative est proposée. La figure (5.10) illustre l’estimation des 500 mesures en utilisant la
méthode ACP adaptative à base de fenêtre glissante. L’évolution des indices de détection SPE et
T2 en absence de défauts se situe sur les figures (5.11) et (5.12).
200 400 600−4
−2
0
2
4
x 1
200 400 600−4
−2
0
2
4
x 2
200 400 600−4
−2
0
2
4
x 7
200 400 600−4
−2
0
2
4
x 10
MesureEstimation
FIGURE 5.10 – Estimation en ligne des mesures x1, x2, x7 et x10 en utilisant la MWPCA.
Dans le cas où le modèle est identifié, la phase de test et de détection des défauts à l’aide
des techniques de l’ACP adaptative est lancée. Un défaut affectant la variable x2 est simulé sous
forme d’une fenêtre qui commence de l’échantillon 500 jusqu’a 600 et d’une amplitude d’environ
40% de sa plage de variation. Les figures (5.13) et (5.14) montrent l’évolution des indices de
détection SPE et T2 en utilisant les deux algorithmes de l’ACP adaptative.
Une fois le défaut détecté, par un ou deux indices de détection, une étape d’isolation de
ce défaut intervient pour savoir la provenance de cette défaillance. Elle peut provenir soit des
capteurs, soit des actionneurs de l’installation industrielle. Dans cet exemple, nous avons uti-
lisé la méthode des contributions par reconstruction pour l’isolation des défauts. De ce fait, les
134
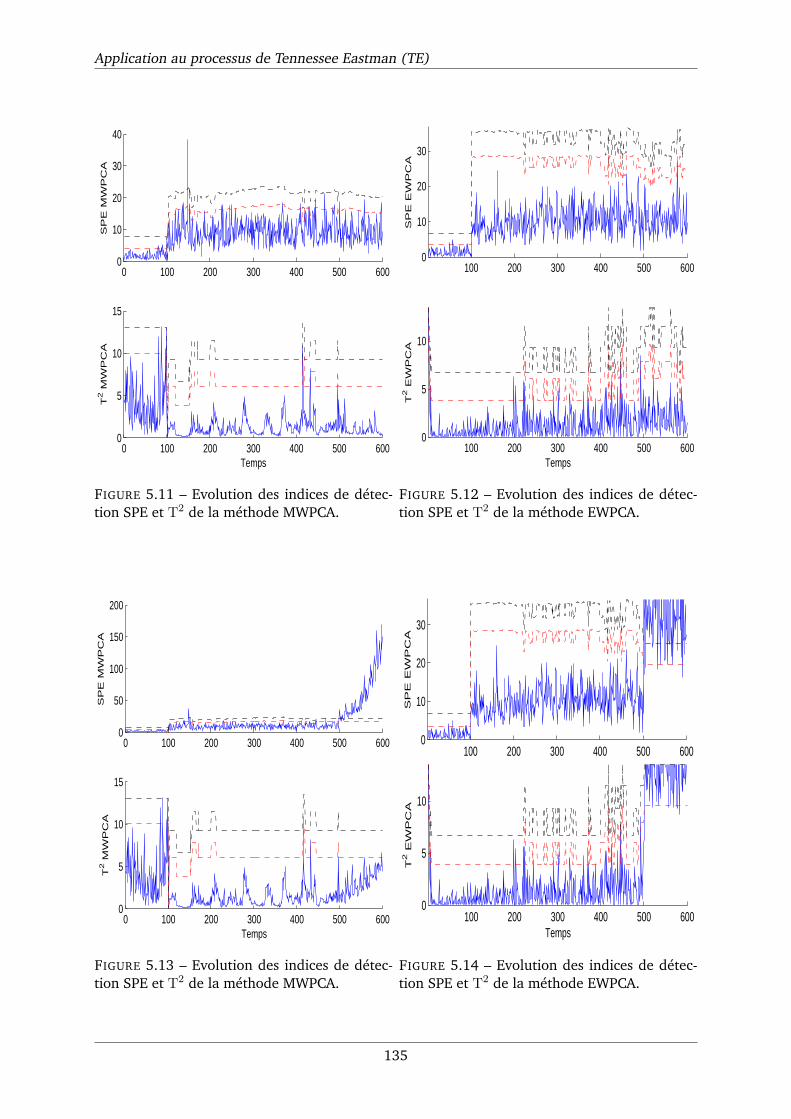
Application au processus de Tennessee Eastman (TE)
0 100 200 300 400 500 6000
10
20
30
40
SP
E M
WP
CA
0 100 200 300 400 500 6000
5
10
15
Temps
T2 M
WP
CA
FIGURE 5.11 – Evolution des indices de détec-tion SPE et T2 de la méthode MWPCA.
100 200 300 400 500 6000
10
20
30
SP
E E
WP
CA
100 200 300 400 500 6000
5
10
T2 E
WP
CA
Temps
FIGURE 5.12 – Evolution des indices de détec-tion SPE et T2 de la méthode EWPCA.
0 100 200 300 400 500 6000
50
100
150
200
SP
E M
WP
CA
0 100 200 300 400 500 6000
5
10
15
Temps
T2 M
WP
CA
FIGURE 5.13 – Evolution des indices de détec-tion SPE et T2 de la méthode MWPCA.
100 200 300 400 500 6000
10
20
30
SP
E E
WP
CA
100 200 300 400 500 6000
5
10
T2 E
WP
CA
Temps
FIGURE 5.14 – Evolution des indices de détec-tion SPE et T2 de la méthode EWPCA.
135
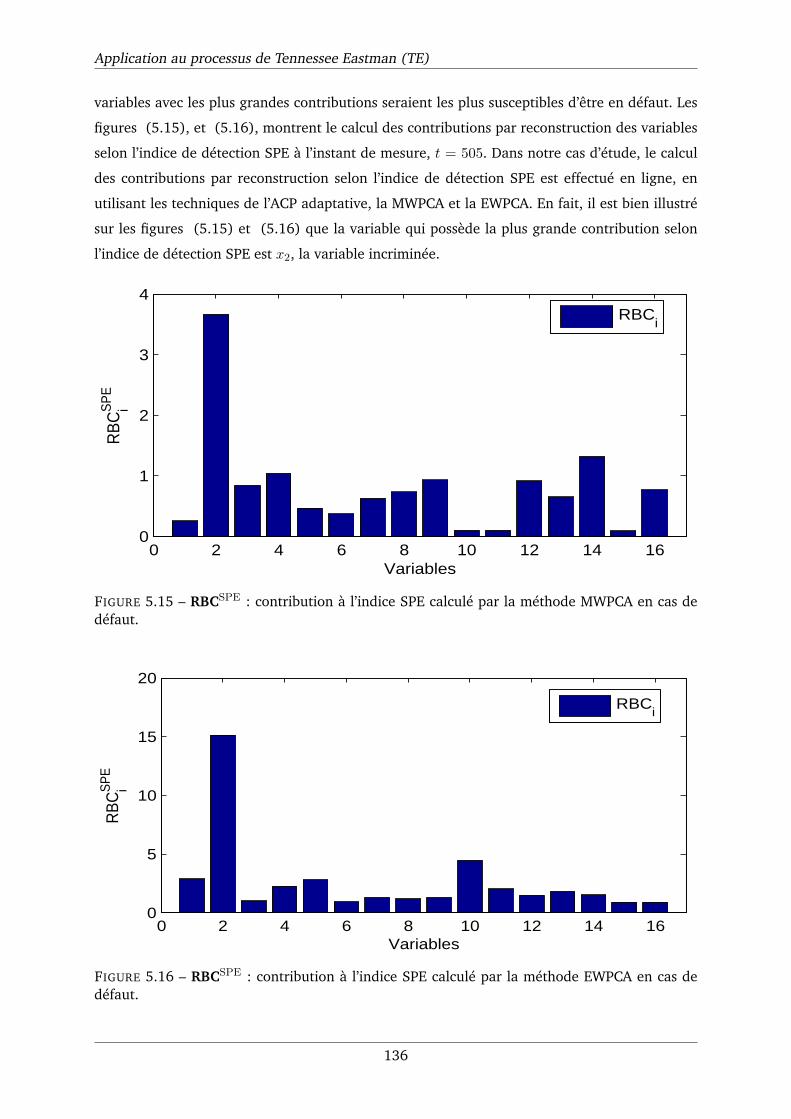
Application au processus de Tennessee Eastman (TE)
variables avec les plus grandes contributions seraient les plus susceptibles d’être en défaut. Les
figures (5.15), et (5.16), montrent le calcul des contributions par reconstruction des variables
selon l’indice de détection SPE à l’instant de mesure, t = 505. Dans notre cas d’étude, le calcul
des contributions par reconstruction selon l’indice de détection SPE est effectué en ligne, en
utilisant les techniques de l’ACP adaptative, la MWPCA et la EWPCA. En fait, il est bien illustré
sur les figures (5.15) et (5.16) que la variable qui possède la plus grande contribution selon
l’indice de détection SPE est x2, la variable incriminée.
0 2 4 6 8 10 12 14 160
1
2
3
4
Variables
RB
CiS
PE
RBC
i
FIGURE 5.15 – RBCSPE : contribution à l’indice SPE calculé par la méthode MWPCA en cas dedéfaut.
0 2 4 6 8 10 12 14 160
5
10
15
20
Variables
RB
CiS
PE
RBCi
FIGURE 5.16 – RBCSPE : contribution à l’indice SPE calculé par la méthode EWPCA en cas dedéfaut.
136

Application au processus de Tennessee Eastman (TE)
Une étude comparative des algorithmes de mise à jour en ligne du modèle ACP (MWPCA,
EWPCA) pour le diagnostic des systèmes linéaires dynamique est menée sur le tableau 5.2. La
comparaison porte essentiellement sur le taux de fausses alarmes (TFA), et le taux de bonne
détection (TBD).
1. Le taux de fausses alarmes (TFA) : il reflète la suspicion accordée à un système de diag-
nostic. Il est exprimé par :
TFA =nombre d’alarmes
nombre d’observations saines(5.6)
2. Le taux de bonne détection (TBD) : il évalue l’aptitude d’un système de diagnostic à dé-
tecter les défauts. Il est exprimé par :
TBD =nombre d’alarmes
nombre d’observations en défauts(5.7)
Le tableau qui résume les performances évaluées des ces deux algorithmes est donné comme
suit :
MWPCA EWPCA
95% 99% 95% 99%
défaut sur x2 100 99 94 81
TBD % défaut sur x4 100 100 74 50
défaut sur x9 100 97 89 69
TFA % 5 2 0 0
TABLE 5.2 – Performance des algorithmes MWPCA et EWPCA dans le cas de l’indice SPE.
D’après les résultats affichés sur le tableau ci-dessus, la méthode EWPCA est plus robuste
aux fausses alarmes que la méthode MWPCA, par contre la méthode MWPCA est plus sensible à
la détection de défauts par rapport à celle de la EWPCA.
Selon les résultats de simulation présentés précédemment, les données de mesure collectées
lors du fonctionnement normal du processus TE ne sont pas adéquatement modélisées par les
techniques adaptatives de la méthode ACP linéaire. En effet, les non linéarités entre les données
n’a pas été pris en compte. C’est pourquoi, un étude similaire, avec les mêmes données, sera
effectuée à l’aide des techniques adaptatives de l’ACP à noyau, prenant en compte l’aspect non
linéaire. C’est l’objet de la seconde partie de cette section.
137
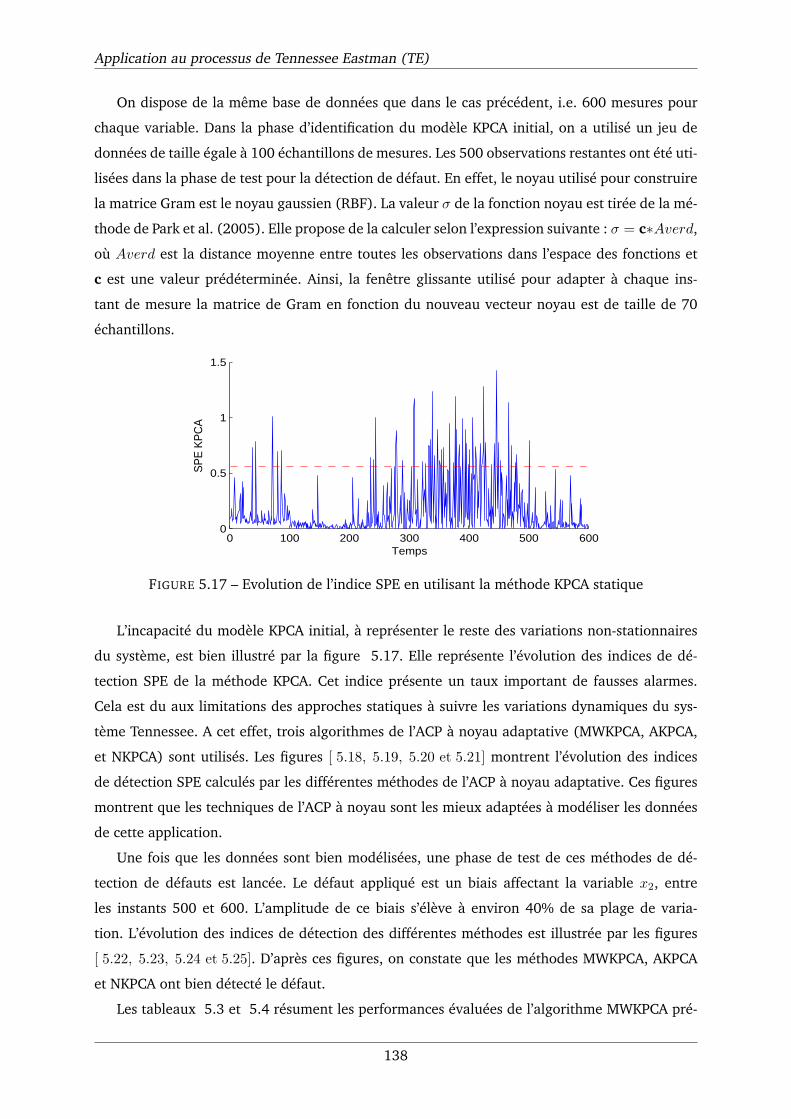
Application au processus de Tennessee Eastman (TE)
On dispose de la même base de données que dans le cas précédent, i.e. 600 mesures pour
chaque variable. Dans la phase d’identification du modèle KPCA initial, on a utilisé un jeu de
données de taille égale à 100 échantillons de mesures. Les 500 observations restantes ont été uti-
lisées dans la phase de test pour la détection de défaut. En effet, le noyau utilisé pour construire
la matrice Gram est le noyau gaussien (RBF). La valeur σ de la fonction noyau est tirée de la mé-
thode de Park et al. (2005). Elle propose de la calculer selon l’expression suivante : σ = c∗Averd,
où Averd est la distance moyenne entre toutes les observations dans l’espace des fonctions et
c est une valeur prédéterminée. Ainsi, la fenêtre glissante utilisé pour adapter à chaque ins-
tant de mesure la matrice de Gram en fonction du nouveau vecteur noyau est de taille de 70
échantillons.
0 100 200 300 400 500 6000
0.5
1
1.5
Temps
SP
E K
PC
A
FIGURE 5.17 – Evolution de l’indice SPE en utilisant la méthode KPCA statique
L’incapacité du modèle KPCA initial, à représenter le reste des variations non-stationnaires
du système, est bien illustré par la figure 5.17. Elle représente l’évolution des indices de dé-
tection SPE de la méthode KPCA. Cet indice présente un taux important de fausses alarmes.
Cela est du aux limitations des approches statiques à suivre les variations dynamiques du sys-
tème Tennessee. A cet effet, trois algorithmes de l’ACP à noyau adaptative (MWKPCA, AKPCA,
et NKPCA) sont utilisés. Les figures [ 5.18, 5.19, 5.20 et 5.21] montrent l’évolution des indices
de détection SPE calculés par les différentes méthodes de l’ACP à noyau adaptative. Ces figures
montrent que les techniques de l’ACP à noyau sont les mieux adaptées à modéliser les données
de cette application.
Une fois que les données sont bien modélisées, une phase de test de ces méthodes de dé-
tection de défauts est lancée. Le défaut appliqué est un biais affectant la variable x2, entre
les instants 500 et 600. L’amplitude de ce biais s’élève à environ 40% de sa plage de varia-
tion. L’évolution des indices de détection des différentes méthodes est illustrée par les figures
[ 5.22, 5.23, 5.24 et 5.25]. D’après ces figures, on constate que les méthodes MWKPCA, AKPCA
et NKPCA ont bien détecté le défaut.
Les tableaux 5.3 et 5.4 résument les performances évaluées de l’algorithme MWKPCA pré-
138
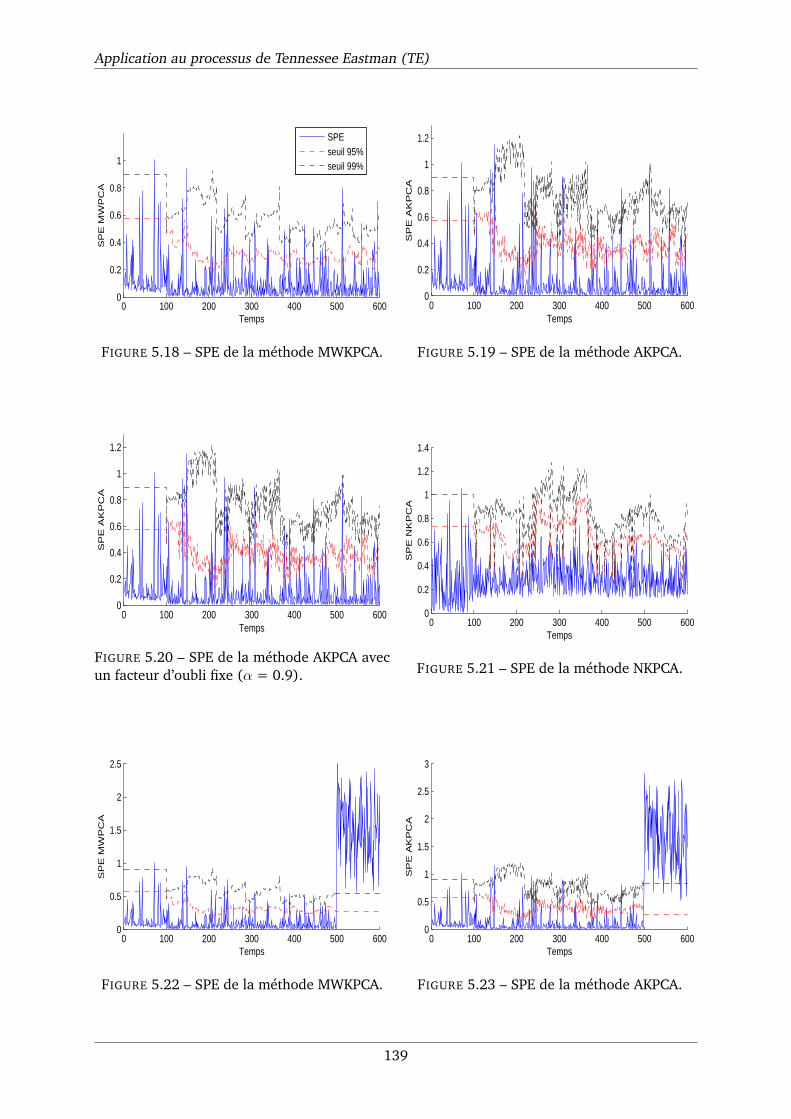
Application au processus de Tennessee Eastman (TE)
0 100 200 300 400 500 6000
0.2
0.4
0.6
0.8
1
Temps
SP
E M
WP
CA
SPEseuil 95%seuil 99%
FIGURE 5.18 – SPE de la méthode MWKPCA.
0 100 200 300 400 500 6000
0.2
0.4
0.6
0.8
1
1.2
Temps
SP
E A
KP
CA
FIGURE 5.19 – SPE de la méthode AKPCA.
0 100 200 300 400 500 6000
0.2
0.4
0.6
0.8
1
1.2
Temps
SP
E A
KP
CA
FIGURE 5.20 – SPE de la méthode AKPCA avecun facteur d’oubli fixe (α = 0.9).
0 100 200 300 400 500 6000
0.2
0.4
0.6
0.8
1
1.2
1.4
Temps
SP
E N
KP
CA
FIGURE 5.21 – SPE de la méthode NKPCA.
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
Temps
SP
E M
WP
CA
FIGURE 5.22 – SPE de la méthode MWKPCA.
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
3
Temps
SP
E A
KP
CA
FIGURE 5.23 – SPE de la méthode AKPCA.
139
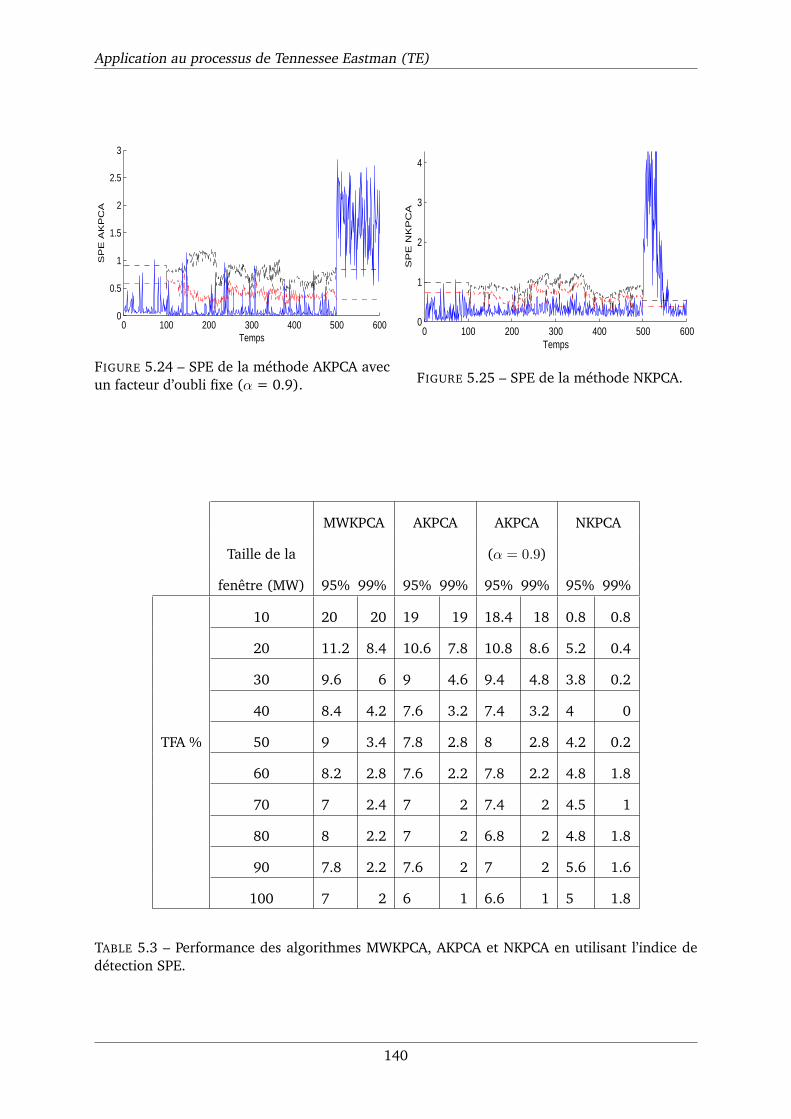
Application au processus de Tennessee Eastman (TE)
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
3
Temps
SP
E A
KP
CA
FIGURE 5.24 – SPE de la méthode AKPCA avecun facteur d’oubli fixe (α = 0.9).
0 100 200 300 400 500 6000
1
2
3
4
Temps
SP
E N
KP
CA
FIGURE 5.25 – SPE de la méthode NKPCA.
MWKPCA AKPCA AKPCA NKPCA
Taille de la (α = 0.9)
fenêtre (MW) 95% 99% 95% 99% 95% 99% 95% 99%
10 20 20 19 19 18.4 18 0.8 0.8
20 11.2 8.4 10.6 7.8 10.8 8.6 5.2 0.4
30 9.6 6 9 4.6 9.4 4.8 3.8 0.2
40 8.4 4.2 7.6 3.2 7.4 3.2 4 0
TFA % 50 9 3.4 7.8 2.8 8 2.8 4.2 0.2
60 8.2 2.8 7.6 2.2 7.8 2.2 4.8 1.8
70 7 2.4 7 2 7.4 2 4.5 1
80 8 2.2 7 2 6.8 2 4.8 1.8
90 7.8 2.2 7.6 2 7 2 5.6 1.6
100 7 2 6 1 6.6 1 5 1.8
TABLE 5.3 – Performance des algorithmes MWKPCA, AKPCA et NKPCA en utilisant l’indice dedétection SPE.
140
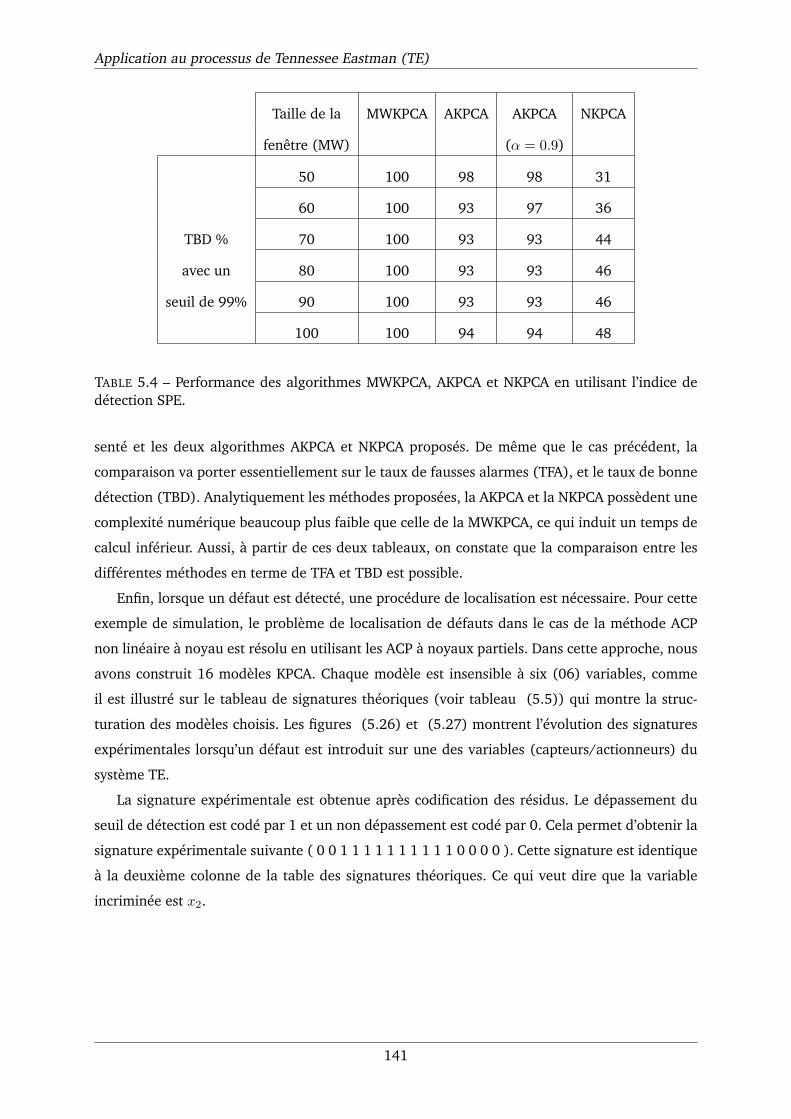
Application au processus de Tennessee Eastman (TE)
Taille de la MWKPCA AKPCA AKPCA NKPCA
fenêtre (MW) (α = 0.9)
50 100 98 98 31
60 100 93 97 36
TBD % 70 100 93 93 44
avec un 80 100 93 93 46
seuil de 99% 90 100 93 93 46
100 100 94 94 48
TABLE 5.4 – Performance des algorithmes MWKPCA, AKPCA et NKPCA en utilisant l’indice dedétection SPE.
senté et les deux algorithmes AKPCA et NKPCA proposés. De même que le cas précédent, la
comparaison va porter essentiellement sur le taux de fausses alarmes (TFA), et le taux de bonne
détection (TBD). Analytiquement les méthodes proposées, la AKPCA et la NKPCA possèdent une
complexité numérique beaucoup plus faible que celle de la MWKPCA, ce qui induit un temps de
calcul inférieur. Aussi, à partir de ces deux tableaux, on constate que la comparaison entre les
différentes méthodes en terme de TFA et TBD est possible.
Enfin, lorsque un défaut est détecté, une procédure de localisation est nécessaire. Pour cette
exemple de simulation, le problème de localisation de défauts dans le cas de la méthode ACP
non linéaire à noyau est résolu en utilisant les ACP à noyaux partiels. Dans cette approche, nous
avons construit 16 modèles KPCA. Chaque modèle est insensible à six (06) variables, comme
il est illustré sur le tableau de signatures théoriques (voir tableau (5.5)) qui montre la struc-
turation des modèles choisis. Les figures (5.26) et (5.27) montrent l’évolution des signatures
expérimentales lorsqu’un défaut est introduit sur une des variables (capteurs/actionneurs) du
système TE.
La signature expérimentale est obtenue après codification des résidus. Le dépassement du
seuil de détection est codé par 1 et un non dépassement est codé par 0. Cela permet d’obtenir la
signature expérimentale suivante ( 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 0 ). Cette signature est identique
à la deuxième colonne de la table des signatures théoriques. Ce qui veut dire que la variable
incriminée est x2.
141
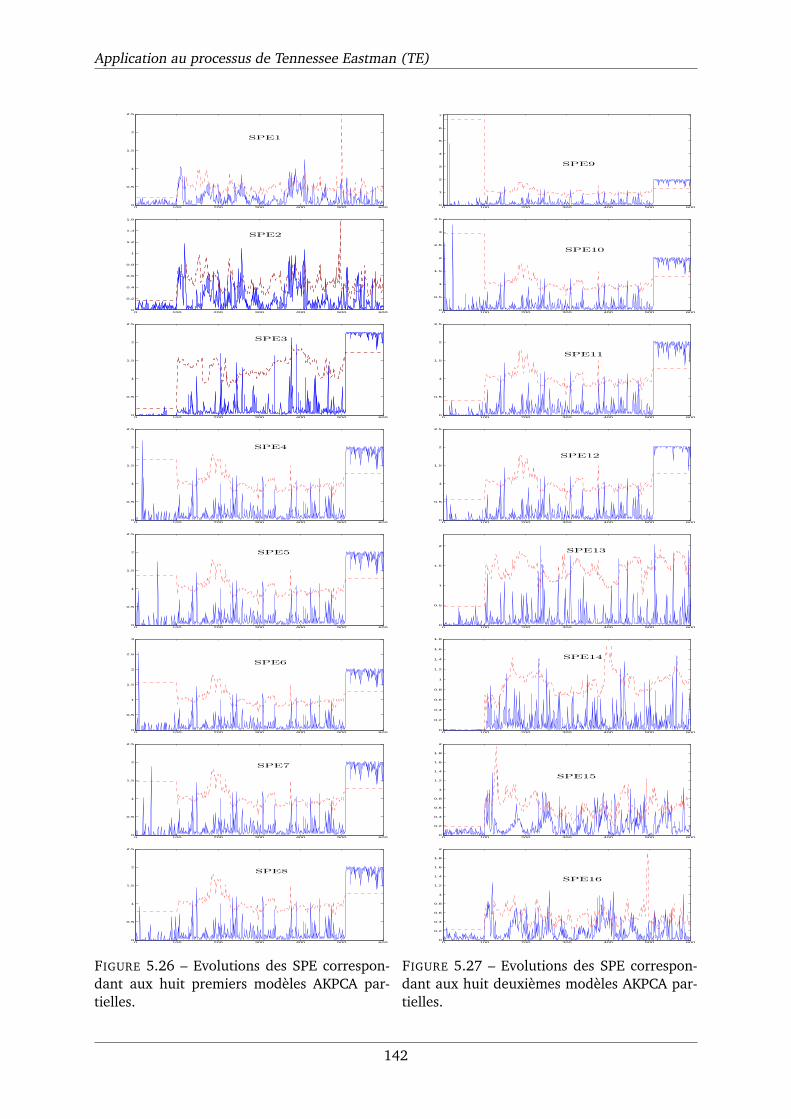
Application au processus de Tennessee Eastman (TE)
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
SPE1
0 100 200 300 400 500 6000
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
SPE2
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
SPE3
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
SPE4
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
SPE5
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
3
SPE6
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
SPE7
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
SPE8
FIGURE 5.26 – Evolutions des SPE correspon-dant aux huit premiers modèles AKPCA par-tielles.
0 100 200 300 400 500 6000
1
2
3
4
5
6
7
SPE9
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
3
3.5
SPE10
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
SPE11
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
SPE12
0 100 200 300 400 500 6000
0.5
1
1.5
2
SPE13
0 100 200 300 400 500 6000
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
SPE14
0 100 200 300 400 500 6000
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
SPE15
0 100 200 300 400 500 6000
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
SPE16
FIGURE 5.27 – Evolutions des SPE correspon-dant aux huit deuxièmes modèles AKPCA par-tielles.
142
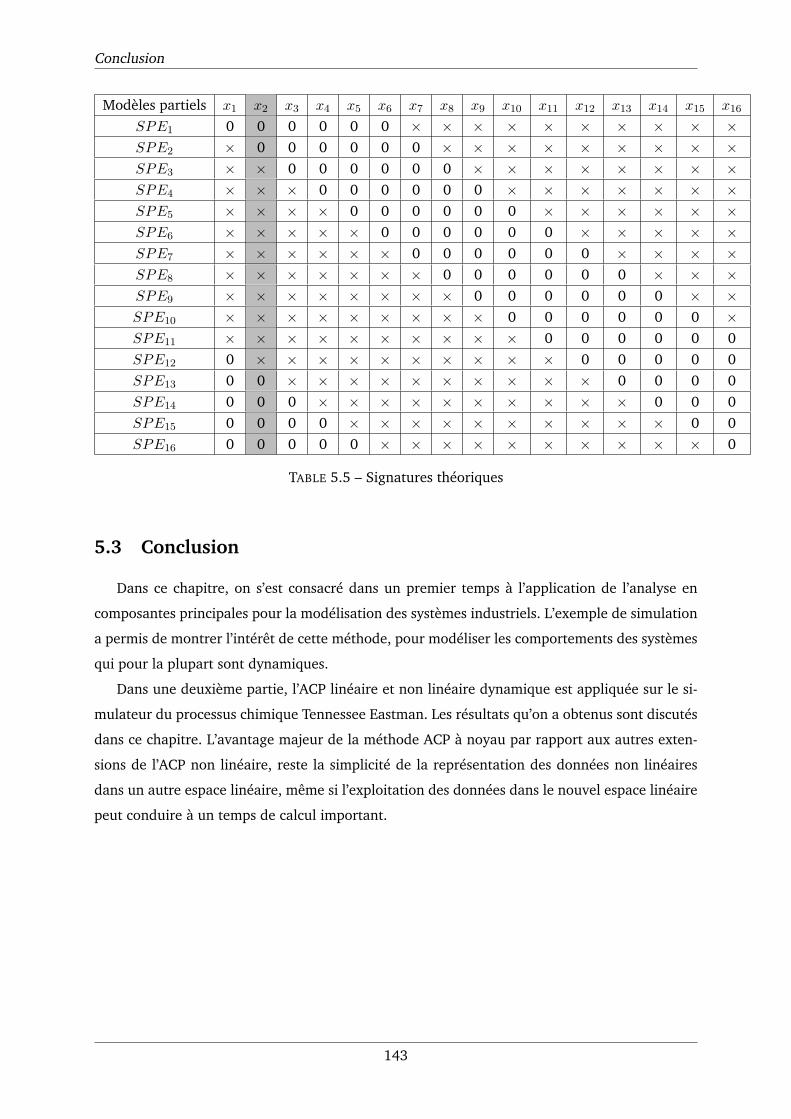
Conclusion
Modèles partiels x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16
SPE1 0 0 0 0 0 0 × × × × × × × × × ×SPE2 × 0 0 0 0 0 0 × × × × × × × × ×SPE3 × × 0 0 0 0 0 0 × × × × × × × ×SPE4 × × × 0 0 0 0 0 0 × × × × × × ×SPE5 × × × × 0 0 0 0 0 0 × × × × × ×SPE6 × × × × × 0 0 0 0 0 0 × × × × ×SPE7 × × × × × × 0 0 0 0 0 0 × × × ×SPE8 × × × × × × × 0 0 0 0 0 0 × × ×SPE9 × × × × × × × × 0 0 0 0 0 0 × ×SPE10 × × × × × × × × × 0 0 0 0 0 0 ×SPE11 × × × × × × × × × × 0 0 0 0 0 0SPE12 0 × × × × × × × × × × 0 0 0 0 0SPE13 0 0 × × × × × × × × × × 0 0 0 0SPE14 0 0 0 × × × × × × × × × × 0 0 0SPE15 0 0 0 0 × × × × × × × × × × 0 0SPE16 0 0 0 0 0 × × × × × × × × × × 0
TABLE 5.5 – Signatures théoriques
5.3 Conclusion
Dans ce chapitre, on s’est consacré dans un premier temps à l’application de l’analyse en
composantes principales pour la modélisation des systèmes industriels. L’exemple de simulation
a permis de montrer l’intérêt de cette méthode, pour modéliser les comportements des systèmes
qui pour la plupart sont dynamiques.
Dans une deuxième partie, l’ACP linéaire et non linéaire dynamique est appliquée sur le si-
mulateur du processus chimique Tennessee Eastman. Les résultats qu’on a obtenus sont discutés
dans ce chapitre. L’avantage majeur de la méthode ACP à noyau par rapport aux autres exten-
sions de l’ACP non linéaire, reste la simplicité de la représentation des données non linéaires
dans un autre espace linéaire, même si l’exploitation des données dans le nouvel espace linéaire
peut conduire à un temps de calcul important.
143

Conclusion générale
L’analyse de données multi variées pour l’identification des états de fonctionnement d’un
processus présente des résultats intéressants pour les systèmes où il est difficile voire impossible
de leur établir un modèle complet. L’utilisation des méthodes statistiques pour un diagnostic de
défauts de processus est une alternative plus prometteuse qu’une utilisation des méthodes qui
se basent sur un modèle mathématique. Puisque l’objectif d’un diagnostic est de constater l’ap-
parition de défauts puis d’en trouver les causes, l’analyse des mesures des variables de processus
permet d’identifier les causes car les états de défaillance sont directement liés aux variables.
Parmi les méthodes à base des statistiques utilisées pour la surveillance des systèmes, celle re-
tenue pour ce travail est l’analyse en composantes principales. L’analyse en composantes princi-
pales est très intéressante pour la mise en évidence des corrélations linéaires existantes entre les
variables du processus, sans pour autant formuler de façon explicite un modèle entrées/sorties
du système. En premier lieu, nous avons présenté le principe de l’ACP. Cette technique permet
de privilégier les directions d’un espace de données porteuses d’un maximum d’informations
au sens de la maximisation des variances de projection. L’ACP cherche à identifier les vecteurs
propres et les valeurs propres de la matrice de corrélation des variables de départ. Cependant,
pour l’obtention de la structure du modèle, il faut déterminer le nombre de composantes princi-
pales à retenir dans celui-ci.
La plupart des processus industriels sont non linéaires et dynamiques. En effet, l’application
de l’ACP linéaire n’est pas très adaptée pour ce type de systèmes, et peut donner donc de mau-
vaises interprétations sur l’état du système. L’ACP à noyau (Kernel PCA) peut être une généra-
lisation de l’ACP linéaire. Elle est particulièrement appropriée pour extraire des caractéristiques
non-linéaires des données à modéliser. Dans une seconde partie, nous avons présenté l’approche
Kernel PCA pour la détection et la localisation des défauts. L’avantage majeur de cette méthode
par rapport aux autres extensions de l’ACP linéaire, reste la simplicité de la représentation des
données non linéaires dans un autre espace linéaire, même si l’explosion de la base de données
dans le nouvel espace linéaire peut conduire à un temps de calcul important.
Cependant, une limitation importante liée à la méthode ACP et ACP à noyau dans sa version
144

Conclusion
classique, est l’invariance du modèle (statique), alors que la nature de la plupart des proces-
sus industriels est dynamique. Leurs comportements et/ou leurs caractéristiques statistiques
changent dans le temps, et ne sont pas préalablement connus ou entièrement compris, en raison
des incertitudes sur le système, et des changements dans les conditions de fonctionnement, . . .
etc. En fait, un modèle ACP ou ACP à noyau dans sa version statique, est incapable de représen-
ter toute variation future possible des données. Pour cette raison, plusieurs approches ont été
proposées pour résoudre ce problème. Il s’agit de l’ACP à noyau dynamique qui est abordée dans
une deuxième partie du deuxième et troisième chapitre. Le challenge majeur de ces techniques
est de surpasser la complexité de calcul, élevée. À cet effet, une nouvelle approche est proposée
comme étant une alternative qui permet l’adaptation à ce problème. L’intérêt donné à la mé-
thode ACP à noyau et son extension dans le cas dynamique a été explicité pour la modélisation
et la surveillance des processus industriels.
Une fois qu’un modèle est bien identifié (modèle statique linéaire/non-linéaire ou modèle
dynamique linéaire/non-linéaire), la construction des indices de détection sensibles aux défauts
est envisagée. La première étape du diagnostic, c’est la génération des résidus (indices de dé-
tection) par deux indices tel que la SPE (squared prédiction Error), et l’indice T2. Dans la partie
qui concerne la localisation des défauts, nous avons présenté deux approches différentes ; loca-
lisation par structuration des résidus (ACP partielles), et la méthode de calcul des contributions
par reconstruction des variables. Le dernier chapitre est consacré à l’application de tous les
algorithmes développés sur un simulateur du processus chimique Tennesse Estman Challange
Process (TE).
Notre objectif futur, est d’adapter la procédure de localisation proposée en ACP linéaire, qui
est basée sur le principe de reconstruction, à partir de l’espace caractéristique (Feature space),
vers l’espace de la pré-image. Il y a aussi l’étude du problème d’optimisation des fonctions
noyaux utilisées pour le cas de l’ACP à noyau, qui a un impact significatif sur la sensibilité
de détection de défauts. Une autre question mérite que l’on s’y consacre, c’est la normalisation
de la matrice noyau dans l’espace des caractéristiques.
145

Bibliographie
Alcala, C. F., and Qin, S. J. (2009). Reconstruction-based contribution for process monito-
ring. Automatica, 45(7), 1593-1600.
Alcala, C. F., and Qin, S. J. (2011). Analysis and generalization of fault diagnosis methods
for process monitoring. Journal of Process Control, 21(3), 322-330.
Aldrich, C., and Auret, L. (2013). Unsupervised process monitoring and fault diagnosis
with machine learning methods. Springer.
Ayech, N., Chakour, C., and Harkat, M. F. (2012, August). New Adaptive Moving Window
PCA for Process Monitoring. In Fault Detection, Supervision and Safety of Technical
Processes (Vol. 8, No. 1, pp. (606-611).
Bakir, G. H., Weston, J., and Schölkopf, B. (2004). Learning to find pre-images. Advances
in neural information processing systems, 16(7), 449-456.
Benchimol G., P. Lévine, J.C. Pomerol (1986). Systèmes experts dans l’entreprise. Hermès
éditions 1986.
Besse, P., and Ferre, L. (1993). Sur l’usage de la validation croisée en analyse en compo-
santes principales. Revue de statistique appliquée, 41(1), 71-76.
Box, G. E. (1954). Some theorems on quadratic forms applied in the study of analysis of
variance problems, I. Effect of inequality of variance in the one-way classification. The
annals of mathematical statistics, 25(2), 290-302.
Carlos Felipe Alcala Perez (2011). Fault diagnosis with reconstruction-based contributions
for statistical process monitoring (Doctoral dissertation, university of Southern Califor-
nia).
Carpenter, G. A., Grossberg, S., and Lesher, G. W. (1998). The what-and-where filter : a
spatial mapping neural network for object recognition and image understanding. Com-
puter Vision and Image Understanding, 69(1), 1-22.
146

BIBLIOGRAPHIE
Chakour C., Harkat M-F., and Djeghaba M. (2013). Adaptive kernel principal component
analysis for nonlinear dynamic process monitoring. In Control Conference (ASCC), 2013
9th Asian (pp. 1-6).
Chakour C., Harkat M-F., Djeghaba M (2014). Dynamic process monitoring based on neu-
ronal principal component analysis. The Second International Conference on Electrical
Engineering And Control Applications (ICEECA), November, 18-20, Constantine, Alge-
ria.
Chakour C., Harkat M-F., Djeghaba M (2015b). Neuronal Principal Component Analysis
for Nonlinear Time-Varying Processes Monitoring. Safe Process 9th IFAC Symposium on
Fault Detection, Supervision and Safety of Technical Processes. September 2-4, 2015,
Paris.
Chakour, C., Harkat, M. F., and Djeghaba, M. (2015a). New Adaptive Kernel Principal Com-
ponent Analysis for Nonlinear Dynamic Process Monitoring. Appl. Math, 9(4), 1833-
1845.
Chen, J. and R. J. Patton (1999). Robust Model-Based Fault Diagnosis for Dynamic Sys-
tems. Kluwer Academic Publishers.
Chen, J. and R. J. Patton (1999). Robust Model-Based Fault Diagnosis for Dynamic Sys-
tems. Kluwer Academic Publishers.
Choi S.W., Elaine B. Martin, A. Julian Morris, and In-Beum Lee (2006). Adaptive Mul-
tivariate Statistical Process Control for Monitoring Time-Varying Processes. Industrial.
Engineering Chemical Research, Vol. 45, No. 9, 3108-3118.
Choi, S. W., and Lee, I. B. (2004). Nonlinear dynamic process monitoring based on dyna-
mic kernel PCA. Chemical engineering science, 59(24), 5897-5908.
Chow, E. Y. and A. S. Willsky (1984). Analytical redundancy and the design of robust
etection systems. IEEE Trans. Automatic Control 29(7), 603-614.
Chow, E. Y. and A. S. Willsky (1984). Analytical redundancy and the design of robust
detection systems. IEEE Trans. Automatic Control 29(7), 603-614.
Chris Aldrich, Lidia Auret (2013). Unsupervised Process Monitoring and Fault Diagnosis
with Machine Learning Methods. Springer London Heidelberg New York Dordrecht.
Darken, C. J., and Jones, B. E. (2007). Computer graphics-based target detection for syn-
thetic soldiers. NAVAL POSTGRADUATE SCHOOL MONTEREY CA.
Didier MAQUIN (2005). Rapport sur la Surveillance des processus.
Dimitrios Fragkoulis (2008). Détection et localisation des défauts provenant des action-
neurs et des capteurs : application sur un système non linéaire. Thèse de doctorat de
l’université Toulouse 3 - Paul Sabatier.
147

BIBLIOGRAPHIE
Ding, M., Tian, Z., and Xu, H. (2010). Adaptive kernel principal component analysis. Signal
Processing, 90(5), 1542-1553.
Dominique Besbois (2000). Rapport : Introduction à la régression des moindres carrées
partiels avec la procédure PLS de SAS.
Dong, D., and McAvoy, T. J. (1996). Nonlinear principal component analysis-based on
principal curves and neural networks. Computers and Chemical Engineering, 20(1), 65-
78.
Duda, R. O., Hart, P. E., and Stork, D. G. (2001). Unsupervised learning and clustering.
Pattern classification, 519-598.
Dunia, R., and Qin, S. J. (1998). Joint diagnosis of process and sensor faults using principal
component analysis. Control Engineering Practice, 6(4), 457-469.
Dunia, R., and Joe Qin, S. (1998). Joint diagnosis of process and sensor faults using prin-
cipal component analysis. Control Engineering Practice, 6(4), 457-469.
Dunia, R., and Joe Qin, S. (1998). Subspace approach to multidimensional fault identifi-
cation and reconstruction. AIChE Journal, 44(8), 1813-1831.
Dunia, R., and Qin, S. J. (1998). A unified geometric approach to process and sensor
fault identification and reconstruction : the unidimensional fault case. Computers and
Chemical Engineering, 22(7), 927-943.
Dunia, R., Qin, S. J., Edgar, T. F., and McAvoy, T. J. (1996). Identification of faulty sensors
using principal component analysis. AIChE Journal, 42(10), 2797-2812.
Dunia, R., Qin, S. J., Edgar, T. F., and McAvoy, T. J. (1996). Identification of faulty sensors
using principal component analysis. AIChE Journal, 42(10), 2797-2812.
Eastment, H. T., and Krzanowski, W. J. (1982). Cross-validatory choice of the number of
components from a principal component analysis. Technometrics, 24(1), 73-77.
Elshenawy, L. M., Yin, S., Naik, A. S., and Ding, S. X. (2009). Efficient recursive princi-
pal component analysis algorithms for process monitoring. Industrial and Engineering
Chemistry Research, 49(1), 252-259.
Fatma Sallem (2013). Détection et isolation de défauts actionneurs basées surun modèle
de l’organe de commande. Thèse de doctorat de l’université Toulouse III - Paul Sabatier.
Fortescue, T. R., Kershenbaum, L. S., and Ydstie, B. E. (1981). Implementation of self-
tuning regulators with variable forgetting factors. Automatica, 17(6), 831-835.
Frank, P. M., Steven X. Ding and Birgit Kopper-Seliger (2000). Current Developments in
the Theory of FDI. In : SAFEPROCESS’00 : Preprints of the IFAC Symposium on Fault
Detection, Supervision and Safety for Technical Processes. Vol. 1. Budapest, Hungary.
pp. 16-27.
148

BIBLIOGRAPHIE
French, R. (1999). Catastrophic forgetting in connectionist networks : Causes, conse-
quences and solutions. Trends in Cognitive Sciences, 3(4), 128-135.
Gertler, J. (1988). Survey of model-based failure detection and isolation in complex plants.
IEEE Control System Magazine pp. 3-11.
Gertler, J. and D. Singer (1990). A new structural framework for parity equation-based
failure detection and isolation. Automatica 26(2), 381-388.
Gertler, J. J (1992). Analytical redundancy methods in fault detection and isolation-survey
and synthesis. IFAC symposium on online fault detection and supervision in the chemical
process industries.
Gertler, J. J (1998). Fault Detection and Diagnosis in Engineering Systems. New York :
Marcel Dekker.
Gertler, J., Li, W., Huang, Y., and McAvoy, T. (1999). Isolation enhanced principal com-
ponent analysis. AIChE Journal, 45(2), 323-334.
Graybill, F. A. (1958). Determining sample size for a specified width confidence interval.
The Annals of Mathematical Statistics, 282-287.
Graybill, F. A., and Connell, T. L. (1964). Sample size required to estimate the parameter in
the uniform density within d units of the true value. Journal of the American Statistical
Association, 59(306), 550-556.
Graybill, F. A., and Morrison, R. D. (1960). Sample size for a specified width confidence
interval on the variance of a normal distribution. Biometrics, 16(4), 636-641.
Greenwood, J. A., and Sandomire, M. M. (1950). Sample size required for estimating the
standard deviation as a per cent of its true value. Journal of the American Statistical
Association, 45(250), 257-260.
Haithem Derbel (2009). Diagnostic à base de modèles des systèmes temporisés et d’une
sous-classe de systèmes dynamiques hybrides. Thèse de doctorat de l’université de Jo-
seph Fourier - Grenoble 1 et l’école de nationale des science de l’informatique de Tunisie.
Hall P., Marshall D., Martin R. (2002). Adding and subtracting eigenspaces with eigenvalue
decomposition and singular value decomposition. Image and Vision Computing, 20 (13-
14) , 1009-1016.
Hall P., Marshall D.,. Martin R (2000). Merging and splitting eigenspace models. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 22 (9), 1042-1049.
Harkat, M. F. (2003). Détection et localisation de défauts par analyse en composantes
principales (Doctoral dissertation, Institut National Polytechnique de Lorraine-INPL).
Hastie, T., and Stuetzle, W. (1989). Principal curves. Journal of the American Statistical
Association, 84(406), 502-516.
149

BIBLIOGRAPHIE
Haykin S. (1994). Neural Networks : A Comprehensive Foundation Macmillan College
Publishing.
Honeine, P., and Richard, C. (2011). Preimage problem in kernel-based machine learning.
Signal Processing Magazine, IEEE, 28(2), 77-88.
Hu Zhi-kun, Chen Zhi-wen, Gui Wei-Hua, Yang Chun-hua, Yin Lin-zi, and Peng Xiao-qi
(2013). An Efficient Multi-PCA Based On-line Monitoring Scheme for Multi-Stages Im-
perial Smelting Process. International Journal of Control, Automation, and Systems,
11(2) :317-324.
Huang, Y., Gertler, J., and McAvoy, T. (1999). Fault isolation by partial PCA and partial
NLPCA.
Huang, Y., Gertler, J., and McAvoy, T. J. (2000). Sensor and actuator fault isolation by
structured partial PCA with nonlinear extensions. Journal of Process Control, 10(5),
459-469.
Irwin Issury (2011). Contribution au développement d’une stratégie de diagnostic global
en fonction des diagnostiqueurs locaux - Application à une mission spatiale - . Thèse de
doctorat de l’université de Bordeaux 1, école doctorale des sciences et de l’ingénieur.
Isermann, R. (1997). Supervision, fault detection and fault diagnosis methods : an intro-
duction. Control Engineering Practice 5(5), 639-652.
Isermann, R. and P. Ball´e (1997). Trends in the application of model-based fault detection
and diagnosis of technical processes. Control Engineering Practice 5(5), 709-719.
Jackson J.E. (1991). A user’s guide to principal components, Wiley-Interscience, New York.
Jia, M., Xu, H., Liu, X., and Wang, N. (2012). The optimization of the kind and parameters
of kernel function in KPCA for process monitoring. Computers and Chemical Enginee-
ring, 46, 94-104.
Joe Qin, S. (2003). Statistical process monitoring : basics and beyond. Journal of chemo-
metrics, 17, 480-502.
Jolliffe (2002). Principal component analysis, Wiley Online Library.
Julien Marzat (2011). Diagnostic des systèmes aéronautiques et réglage automatique pour
la comparaison de méthodes. Thèse de doctorat de l’ université Paris-Sud XI, Faculté des
Sciences d’Orsay.
Kadlec, P., Grbi, R., and Gabrys, B. (2011). Review of adaptation mechanisms for data-
driven soft sensors. Computers and chemical engineering, 35(1), 1-24.
Kallas, M. (2012). Méthodes à noyaux en reconnaissance de formes, prédiction et classifi-
cation. Applications aux biosignaux (Doctoral dissertation, Université de Technologie de
Troyes).
150

BIBLIOGRAPHIE
Kano M., H. Ohno, S. Hasebe, I. Hashimoto (2001). A new statistical process monitoring
method using principal component analysis. Computers and Chemical Engineering, 25,
1103-1113.
Kariwala, V., Odiowei, P. E., Cao, Y., and Chen, T. (2010). A branch and bound method
for isolation of faulty variables through missing variable analysis. Journal of Process
Control, 20(10), 1198-1206.
Khediri, I. B., Limam, M., and Weihs, C. (2011). Variable window adaptive kernel princi-
pal component analysis for nonlinear nonstationary process monitoring. Computers and
Industrial Engineering, 61(3), 437-446.
Khediri, I. B., Limam, M., and Weihs, C. (2011). Variable window adaptive kernel princi-
pal component analysis for nonlinear nonstationary process monitoring. Computers and
Industrial Engineering, 61(3), 437-446.
Kim, K. I., Franz, M. O., and Schölkopf, B. (2005). Iterative kernel principal component
analysis for image modeling. Pattern Analysis and Machine Intelligence, IEEE Transac-
tions on, 27(9), 1351-1366.
Kramer, M. A. (1991). Nonlinear principal component analysis using autoassociative neu-
ral networks. AIChE journal, 37(2), 233-243.
Kresta, J. V., MacGregor, J. F., and Marlin, T. E. (1991). Multivariate statistical monito-
ring of process operating performance. The Canadian Journal of Chemical Engineering,
69(1), 35-47.
Kresta, J.V., J.F. MacGregor and T.E. Marlin (1991). Multivariate statistical monitoring
of process operating performance. The Canadian Journal of Chemical Engineering, 69,
35-47.
Kruger, U., and Xie, L. (2012). Advances in statistical monitoring of complex multivariate
processes : with applications in industrial process control. John Wiley and Sons.
Kwok, J. T. Y., and Tsang, I. W. H. (2004). The pre-image problem in kernel methods.
Neural Networks, IEEE Transactions on, 15(6), 1517-1525.
L. Hoegaerts, L.D. Lathauwer, I. Goethals, J.A.K. Suykens, J. Vandewalle, B.D. Moor
(2007). Efficiently updating and tracking the dominant kernel principal components.
Neural Networks, 20 (2), 220-229.
Lee, J. M., Yoo, C., and Lee, I. B. (2004). Statistical monitoring of dynamic processes based
on dynamic independent component analysis. Chemical engineering science, 59(14),
2995-3006.
Lee, J. M., Yoo, C., Choi, S. W., Vanrolleghem, P. A., and Lee, I. B. (2004). Nonlinear
process monitoring using kernel principal component analysis. Chemical Engineering
Science, 59(1), 223-234.
151

BIBLIOGRAPHIE
Li, W., and Qin, S. J. (2001). Consistent dynamic PCA based on errors-in-variables sub-
space identification. Journal of Process Control, 11(6), 661-678.
Li, W., Yue, H. H., Valle-Cervantes, S., and Qin, S. J. (2000). Recursive PCA for adaptive
process monitoring. Journal of process control, 10(5), 471-486.
Liu, X., Kruger, U., Littler, T., Xie, L., and Wang, S. (2009). Moving window kernel PCA for
adaptive monitoring of nonlinear processes. Chemometrics and Intelligent Laboratory
Systems, 96(2), 132-143.
Liu, X., Kruger, U., Littler, T., Xie, L., and Wang, S. (2009). Moving window kernel PCA for
adaptive monitoring of nonlinear processes. Chemometrics and Intelligent Laboratory
Systems, 96(2), 132-143.
M. Nassim Laouti (2012). Diagnostic de défauts par les Machines à Vecteurs Supports :
application à différents systèmes multi-variables non linéaires. Thèse de doctorat de
l’université de Claude Bernard Lyon 1.
MacGregor, J.F. and T. Kourti (1995). Statistical process control of multivariate processes.
Control Engineering Practice, 3(3), 403-414.
Malinowski, E.R. (1991). Factor Analysis in Chemistry. (2nd edn.) John Wiley and Sons,
Inc, New York.
McAuley K.B., MacGregor J.F. (1991). On-line inference of polymer properties in an indus-
trial polyethylene reactor. AIChE Journal, 37, 825-835.
Michel Batteux (2011). Diagnosticabilité et diagnostic de systèmes technologiques pilotés.
Thèse de doctorat de l’école doctorale informatique Paris-Sud, laboratoire de recherche
en informatique.
Mika, S., Rätsch, G., Weston, J., Schölkopf, B., Smola, A. J., and Müller, K. R. (1999,
November). Invariant Feature Extraction and Classification in Kernel Spaces. In NIPS
(pp. 526-532).
Miller, W. H., Levine, K., DeBlasio, A., Frankel, S. R., Dmitrovsky, E., and Warrell, R. P.
(1993). Detection of Minimal Residual Disease in Acute Promyelocytic Leukemia by
a Reverse Transcription Polymerase Chain Reaction Assay for the PML/RAR- Fusion
mRNA. BLOOD-NEW YORK-, 82, 1689-1689. Neural Computation, 10(5) :1299-1319.
Nomikos, P., and MacGregor, J. F. (1995). Multivariate SPC charts for monitoring batch
processes. Technometrics, 37(1), 41-59.
Oja E. (1982) A simplified neuron model as a principal component analyzer, Journal of
Mathematics and Biology 15, p. 267-273.
152

BIBLIOGRAPHIE
Oja, E., and Karhunen, J. (1985). On stochastic approximation of the eigenvectors and
eigenvalues of the expectation of a random matrix. Journal of mathematical analysis
and applications, 106(1), 69-84.
Park, C. H., and Park, H. (2005). Nonlinear discriminant analysis using Kernel functions
and the generalized singular value decomposition. Journal of Matrix analysis and appli-
cations, 27, 87-102.
Patton, R. J. (1999). Preface to the Papers from the 3rd IFAC Symposium SAFEPRO-
CESS’97. Control Engineering Practice 7(1), 201-202.
Patton, R. J. and J. Chen (1994a). A review of parity space approaches to fault diagnosis
for aerospace systems. AIAA J. of Guidance, Contr. and Dynamics 17(2), 278-285.
Polanyi, M. (1958). Personal knowledge : Towards a post-critical philosophy. Chicago :
University of Chicago Press. ISBN 0-226-67288-3.
Qin, S. J. (2012). Survey on data-driven industrial process monitoring and diagnosis. An-
nual Reviews in Control, 36, 220-234.
Qin, S. J., and Dunia, R. (2000). Determining the number of principal components for best
reconstruction. Journal of Process Control, 10(2), 245-250.
Rabah Fellouah (2007). Contribution au Diagnostic de Pannes pour les Systèmes différen-
tiellement Plats. Thèse de doctorat de l’université de Toulouse, l’INSA .
Rosario Toscano (2004). Commande et diagnostic des systèmes dynamique. Ellipses édi-
tion 2004.
Russell, E. L., Chiang, L. H., and Braatz, R. D. (2000a). Data-driven techniques for fault
detection and diagnosis in chemical processes. London/New York : Springer.
Salowa Methnani (2012). Diagnostic, reconstruction et identification des défauts capteurs
et actionneurs : application aux station d’épurations des eaux usées. Thèse de doctorat
de l’université de Toulon et du Var ; Ecole nationale d’ingénieurs de Sfax.
Sanger, T. D. (1989). Optimal unsupervised learning in a single-layer linear feedforward
neural network. Neural networks, 2(6), 459-473.
Schökopf, B., Smola, A., and Muller, K. (1998). Nonlinear component analysis as a kernel
eigenvalue problem.
Schraudolph, N. N., Yu, J., and Günter, S. (2007). A stochastic quasi-Newton method for
online convex optimization. In International Conference on Artificial Intelligence and
Statistics (pp. 436-443).
Seber, G. A., and Lee, A. J. (2003). Linear regression analysis. Hoboken.
153

BIBLIOGRAPHIE
Shao, J. D., Rong, G., and Lee, J. M. (2009). Learning a data-dependent kernel function for
KPCA-based nonlinear process monitoring. Chemical Engineering Research and Design,
87(11), 1471-1480.
Tamura, M., and Tsujita, S. (2007). A study on the number of principal components and
sensitivity of fault detection using PCA. Computers and Chemical Engineering, 31(9),
1035-1046.
Tan, S., and Mayrovouniotis, M. L. (1995). Reducing data dimensionality through optimi-
zing neural network inputs. AIChE Journal, 41(6), 1471-1480.
Tatiana Kempawsky (2004). Surveillance de procédé à base de méthode de classifications :
conception d’un outil d’aide pour la détection et le diagnostic des défaillances. Thèse de
doctorat de l’institut national des sciences appliquées de Toulouse.
Thissen, U., Melssen, W. J., and Buydens, L. M. (2001). Nonlinear process monitoring
using bottle-neck neural networks. Analytica Chimica Acta, 446(1), 369-381.
Tien Doan Xuan (2005). Moving PCA For Process fault detection- A performance and sen-
sitivity study. Thesis of National university Singapore.
Valle, S., Li, W., and Qin, S. J. (1999). Selection of the number of principal components :
the variance of the reconstruction error criterion with a comparison to other methods.
Industrial and Engineering Chemistry Research, 38(11), 4389-4401.
Valle, S., Li, W., Qin, S. J. (1999). Selection of the number of principal components :
the variance of the reconstruction error criterion with a comparison to other methods.
Industrial and Engineering Chemistry Research, 38(11), 4389-4401.
Varanon Uraikul, Christine W. Chan, Paitoon Tontiwachwuthikul (2007). Arti ?cial intelli-
gence for monitoring and supervisory control of process systems. Engineering Applica-
tions of Arti ?cial Intelligence 20 (2007) 115-131.
Venkat Venkatasubramanian, Raghunathan Rengaswamy, Surya N. Kavuri, Kewen Yin
(2003). A review of process fault detection and diagnosis Part (1, 2,3). Computers and
Chemical Engineering 27 (2003).
Wang, X., Kruger, U., and Irwin, G. W. (2005). Process monitoring approach using fast
moving window PCA. Industrial and Engineering Chemistry Research, 44(15), 5691-
5702.
Weinberger, K. Q., Sha, F., and Saul, L. K. (2004, July). Learning a kernel matrix for non-
linear dimensionality reduction. In Proceedings of the twenty-first international confe-
rence on Machine learning (p. 106).
Wise B.M., Gallagher N.B. (1996). The process chemometrics approach to process monito-
ring and fault detection. Journal or Process Control, 6 (6), 329-348.
154

BIBLIOGRAPHIE
Wise, B. M., and Ricker, N. L. (1991, October). Recent advances in multivariate statistical
process control : improving robustness and sensitivity. In IFAC Symposium on Advanced
Control of Chemical Processes. Toulouse, France (pp. 125-130).
Wold (1980), ’Model construction and evaluation when theoretical knowledge is scarce’,
In : Kmenta, J., Ramsey, J.B (Eds), ’Evaluation of econometric models’, Academic Press,
New York, pp.383-407 .
Wold (1982). Soft modeling : the basic design and some extentions, In : Jöreskog, K.G. and
Wold H. (Eds), ’Systems underIndirect Observation. Vol2. North-Holland, Amsterdam,
pp.1-54. 14, 20, 25, 26, 27, 99.
Wold Svante (1994). Exponentially weighted moving principal components analysis and
projections to latent structures. Chemometrics and Intelligent Laboratory Systems, 23,
149-161.
Wold, S. (1978). Cross-validatory estimation of the number of components in factor and
principal components models. Technometrics, 20(4), 397-405.
Xiao Bin He and Yu Pu Yang (2008). Variable MWPCA for Adaptive Process Monitoring.
Industrial Engineering Chemical Research, 47, 419 - 427.
Yue, H. H., and Qin, S. J. (2001). Reconstruction-based fault identification using a combi-
ned index. Industrial and engineering chemistry research, 40(20), 4403-4414.
Zadeh, L. A. (1965). Fuzzy sets. Information and Control, volume 8, pp. 338-353.
Žvokelj, M., Zupan, S., and Prebil, I. (2011). Non-linear multivariate and multiscale mo-
nitoring and signal denoising strategy using kernel principal component analysis com-
bined with ensemble empirical mode decomposition method. Mechanical Systems and
Signal Processing, 25(7), 2631-2653.
155





























