Embed Size (px)
Citation preview

Fouille de données massives - Big Data Mining
Julien JACQUES
Université Lumière Lyon 2
1 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R2 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R3 / 77

La fouille de données : qu’est-ce que c’est ?
Fouille de données / data miningEnsemble d’approches statistiques permettant d’extraire de l’informationde grands jeux de données dans une perspectives d’aide à la décision 1.
1P. Besse et al., Data Mining et Statistique, Journal de la Société Française deStatistique, 142[1], 2001.
4 / 77

La fouille de données : quelques références
avec ex. en disponible en ligne
5 / 77

La fouille de données : quelques références
� http://eric.univ-lyon2.fr/~ricco/data-mining/
� http://wikistat.fr
� http://data.mining.free.fr
6 / 77

La fouille de données : à quoi cela sert ?
� publicité ciblée sur internet� identification des prospects les plus susceptibles de devenir clients� reconnaissance faciale dans une image� calcul de la rentabilité des clients� évaluer le risque d’un client (credit scoring)� détection de fraudes bancaires� analyse automatique de contenus textuels (text mining)� reconnaissance de la parole� prévision de consommation d’électricité� prévision de traffic routier� tester l’efficacité d’un traitement médical� ...
7 / 77

La fouille de données : les étapes à suivre
Les étapes du data mining
1. Nettoyage des données (erreurs, données manquantes, outliers)
2. Transformation éventuelle des données (normalisation, linéarisation...)
3. Explicitation de l’objectif de l’analyse en terme statistique (régression,classification, clustering...)
4. Choix de la méthode à utiliser5. Mise en oeuvre informatique ( ...)
6. Test (validation de la qualité des résultats)
7. Exploitation
8 / 77
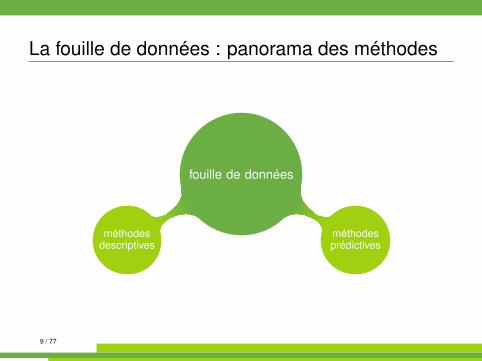
La fouille de données : panorama des méthodes
fouille de données
méthodesprédictives
méthodesdescriptives
9 / 77
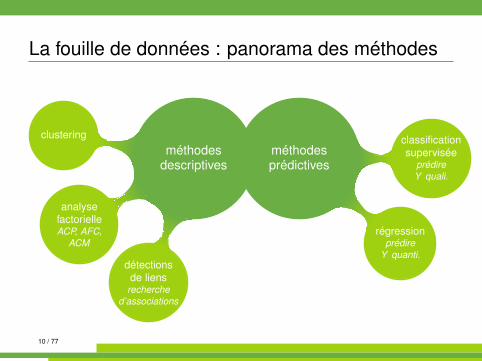
La fouille de données : panorama des méthodes
méthodesprédictives
classificationsupervisée
prédireY quali.
régressionprédire
Y quanti.
méthodesdescriptives
détectionsde liens
recherched’associations
analysefactorielleACP, AFC,
ACM
clustering
10 / 77

La fouille de données : panorama des méthodes
Ce qui est abordé dans ce cours :� clustering (classification automatique, classification non supervisée,
segmentation, typologie...) :regrouper des individus qui se ressemblent en classesreprésentatives
� classification supervisée (discrimination, analyse discriminante,scoring) :classer des individus dans des classes définies a priori
Notations :� les individus (observations) sont décrits par un ensemble de p
variables aléatoires explicatives X = (X1, . . . ,Xp) ∈ E (E = Rp, ...)� Xi = (Xi1, . . . ,Xip) sont les variables explicatives pour l’individu i
(1 ≤ i ≤ n)� Zi ∈ {1, . . . ,K} est le numéro de la classe de l’individu i
11 / 77

La fouille de données : panorama des méthodes
Ce qui est abordé dans ce cours :� clustering (classification automatique, classification non supervisée,
segmentation, typologie...) :regrouper des individus qui se ressemblent en classesreprésentatives
� classification supervisée (discrimination, analyse discriminante,scoring) :classer des individus dans des classes définies a priori
Notations :� les individus (observations) sont décrits par un ensemble de p
variables aléatoires explicatives X = (X1, . . . ,Xp) ∈ E (E = Rp, ...)� Xi = (Xi1, . . . ,Xip) sont les variables explicatives pour l’individu i
(1 ≤ i ≤ n)� Zi ∈ {1, . . . ,K} est le numéro de la classe de l’individu i
11 / 77

Classification non supervisée vs supervisée
Classification non supervisée� Zi inconnue (aucune signification a priori)� objectif : à partir de l’observation de X1, . . . ,Xn, prédire Z1, . . . ,Zn
� les classes sont ensuite interprétées dans le but de leur donner unesignification concrète
Classification supervisée� Zi connue (signification connue a priori)� objectif : à partir de l’observation de (X1,Z1), . . . , (Xn,Zn) construire
une règle de classement r :
r : X −→ r(X ) = Z
� utiliser cette règle de classement pour classer de nouveaux individusde classes inconnues
12 / 77

Applications
Classification non supervisée� analyse exploratoire : donner une représentation simplifiée des
données pour mieux les comprendre� exemple : typologie clients en marketing (Gestion de la relation
clients / CRM - Customer Relationship Management)
Classification supervisée� analyse prédictive : prédire une variable (Z ) qualitative à partir de
variables explicatives (X)� exemples : prédire si un prospect va acheter le produit qu’on lui
propose, prédire la probabilité qu’un patient soit atteint d’une certainemaladie...
13 / 77

Les différentes méthodes abordées dans ce cours
Classification non supervisée� méthodes géométriques
� centres mobiles (kmeans),� méthode probabiliste
� modèles de mélanges
Classification supervisée� méthodes prédictives : on estime la loi de (Z |X)
� k plus proche voisins (k-NN)� méthode générative : on estime la loi de (X,Z )
� modèles de mélanges (dont analyse discriminante)
14 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R15 / 77

Les Big Data
Les 3 V� Volume des données
� le nombre d’observations n est grand� le nombre de variables p est grand (devant n : n << p ; ex: génomique...)
� Variété des données� données quantitatives, qualitatives, textuelles, images, fonctionnelles, ...
� Vélocité de l’acquisition� acquisition des données en (quasi) continu
Un article intéressant (à lire) : Apprentissage sur Données Massives;trois cas d’usage avec R, Python et Spark, Besse et al. 2017.
16 / 77

Les Big Data
Les 3 V� Volume des données
� le nombre d’observations n est grand� le nombre de variables p est grand (devant n : n << p ; ex: génomique...)
� Variété des données� données quantitatives, qualitatives, textuelles, images, fonctionnelles, ...
� Vélocité de l’acquisition� acquisition des données en (quasi) continu
Un article intéressant (à lire) : Apprentissage sur Données Massives;trois cas d’usage avec R, Python et Spark, Besse et al. 2017.
16 / 77

Comment appréhender les Big Data
� parcimonie dans l’utilisation de la mémoire (n grand)� apprentissage on-line (velocité)� calcul parallèle (volume)� échantillonnage (n grand)� parcimonie dans la paramétrisation des modèles (n«p)� modèles d’apprentissage spécifiques (variété)
17 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R18 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R19 / 77

Notions de distances et dissimilarités
Soient Xi et Xj deux observations de E .
On appelle distance toute fonction d : E × E → R+ telle que1. d(Xi ,Xj ) ≥ 02. d(Xi ,Xj ) = d(Xj ,Xi )
3. d(Xi ,Xj ) = 0⇔ Xj = Xi
4. d(Xi ,Xj ) ≤ d(Xi ,Xk ) + d(Xk ,Xj ) pour tout Xk ∈ ELorsque seulement 1. à 3. sont vérifiées, on parle de dissimilarité.
20 / 77

Distances et dissimilarités usuelles
Distances pour données quantitatives E = Rp
d2(Xi ,Xj ) = (Xi − Xj )tM(Xi − Xj )
� distance euclidienne (M = I) : d(Xi ,Xj ) =(∑p
`=1(Xi` − Xj`)2)1/2
� distance de Mahalanobis (M = V−1 avec V la matrice de covariance)� ...
21 / 77

Comparaison de partitions
On utilise souvent l’indice de Rand pour comparer deux partitionsZ1 = (Z11, . . . ,Z1n) et Z2 = (Z21, . . . ,Z2n) :
R =a + d
a + b + c + d=
a + d(2n
) ∈ [0,1]
où, parmi les(2
n
)paires d’individus possibles :
� a : nombre de paires dans une même classe dans Z1 et dans Z2
� b : nombre de paires dans une même classe dans Z1 mais séparéesdans Z2
� c : nombre de paires séparées dans Z1 mais dans une même classedans Z2
� d : nombre de paires séparées dans Z1 et dans Z2
22 / 77

Exercice
Deux méthodes de clustering ont conduit aux 2 partitions suivantes :� Z1 = {1,1,2,2,2}� Z2 = {1,2,2,1,2}Calculer l’indice de Rand de ces deux partitions.
Correction : a = 1, d = 3,(2
5
)= 10 et R = 0.4
23 / 77

Exercice
Deux méthodes de clustering ont conduit aux 2 partitions suivantes :� Z1 = {1,1,2,2,2}� Z2 = {1,2,2,1,2}Calculer l’indice de Rand de ces deux partitions.
Correction : a = 1, d = 3,(2
5
)= 10 et R = 0.4
23 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R24 / 77

Algorithme des kmeans kmeans{stats}
On se place dans E = Rp muni de la distance euclidienne.
Algorithm 1 kmeans1: init. : tirages au hasard de K centres µk parmi les n observations2: while partition non stable do3: affecter chaque observation à la classe dont le centre est le plus
proche4: recalculer les centres (moyennes) des classes5: end while
25 / 77
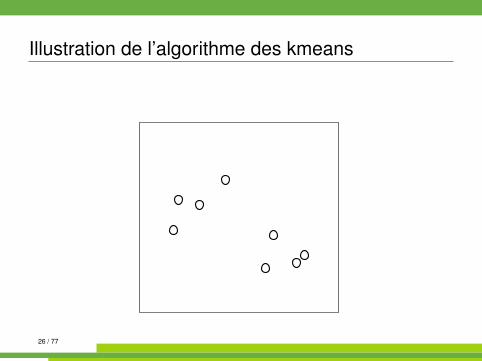
Illustration de l’algorithme des kmeans
26 / 77
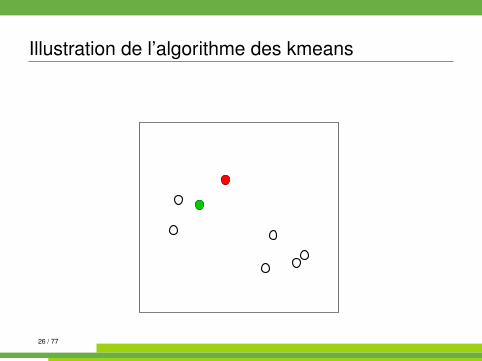
Illustration de l’algorithme des kmeans
26 / 77
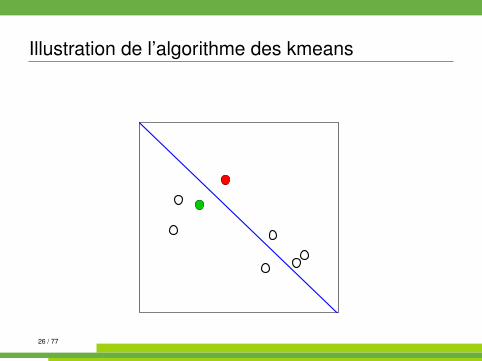
Illustration de l’algorithme des kmeans
26 / 77
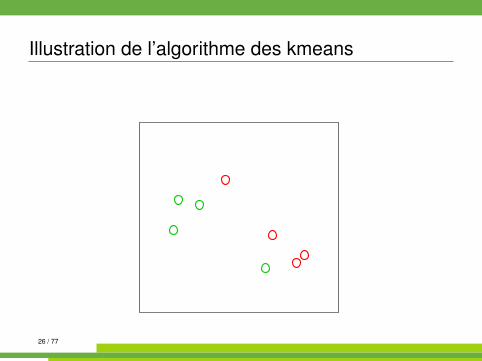
Illustration de l’algorithme des kmeans
26 / 77
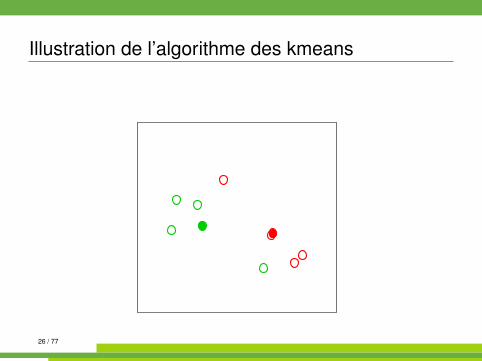
Illustration de l’algorithme des kmeans
26 / 77
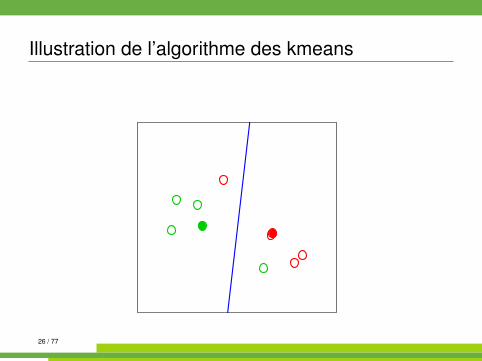
Illustration de l’algorithme des kmeans
26 / 77
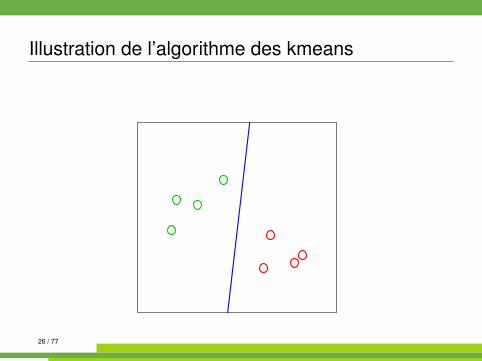
Illustration de l’algorithme des kmeans
26 / 77
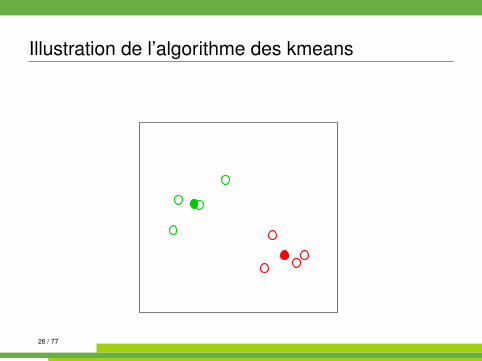
Illustration de l’algorithme des kmeans
26 / 77
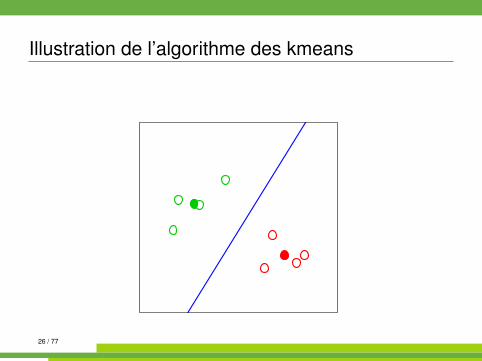
Illustration de l’algorithme des kmeans
26 / 77
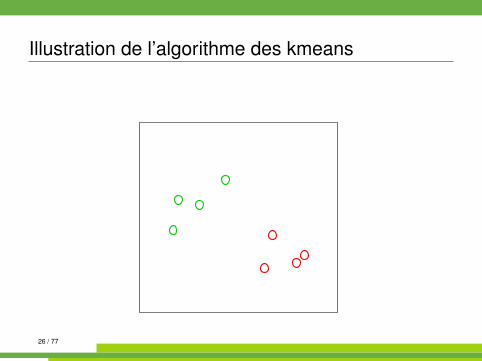
Illustration de l’algorithme des kmeans
26 / 77

Algorithme des kmeans kmeans{stats}
Propriétés� l’algorithme des kmeans minimise l’inertie intra-classe W (Z) :
T = B(Z) + W (Z)
� T =n∑
i=1
d2(Xi , µ) : inertie totale du nuage de point (µ est le centre global)
� B(Z) =K∑
k=1
nk d2(µk , µ) : inertie inter-classe (nk nb. obs. dans classe k )
� W (Z) =K∑
k=1
∑i=1,n:Zi=k
d2(Xi , µk ) : inertie intra-classe
� l’algorithme des kmeans est convergeant� la solution peut dépendre de l’initialisation (⇒ en pratique on réalise
plusieurs init. et on conserve celle minimisant W (Z))27 / 77
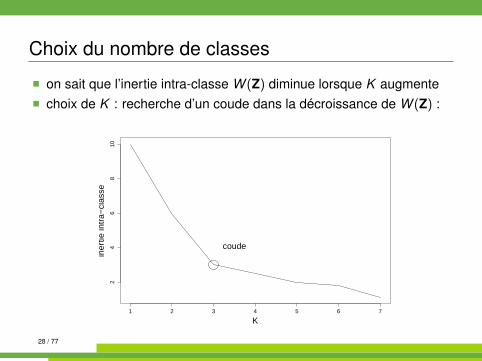
Choix du nombre de classes
� on sait que l’inertie intra-classe W (Z) diminue lorsque K augmente� choix de K : recherche d’un coude dans la décroissance de W (Z) :
1 2 3 4 5 6 7
24
68
10
K
iner
tie in
tra−
clas
se
coude
28 / 77

Exercice
Réaliser une classification automatique en 2 classes à l’aide del’algorithme de kmeans sur les données suivantes :� X1 = 0� X2 = 2� X3 = 6� X4 = 11Avez-vous tous obtenus les mêmes partitions ?
Correction sous : kmeans(c(0,2,6,11),centers=c(2,6))
29 / 77

Exercice
Réaliser une classification automatique en 2 classes à l’aide del’algorithme de kmeans sur les données suivantes :� X1 = 0� X2 = 2� X3 = 6� X4 = 11Avez-vous tous obtenus les mêmes partitions ?
Correction sous : kmeans(c(0,2,6,11),centers=c(2,6))
29 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R30 / 77

Clustering par modèles de mélanges (MM)� Idée : chaque classe est caractérisée par sa propre loi de probabilité
X|Z = k ∼ f (x, θk ) = fk (x)
� variables quantitatives : f (·, θk ) densité gaussienne, θk = (µk ,Σk )� variables qualitatives : f (·, θk ) proba. multinomiale, θk = (αkjh)1≤j≤p,1≤h≤mj
� loi marginale de X (densité mélange)
X ∼K∑
k=1
pk fk (x) = fX(x).
où pk est la proportion de la classe k� probabilité conditionnelle que x provienne de la classe k (via Bayes) :
tk (x) = P(Z = k |X = x) =pk fk (x)
fX(x).
31 / 77

MM : estimation
Idée fondamentale� maximum de vraisemblance pour θ = (θk )1≤k≤K
� déduire Z grâce aux tk (xi ) par maximum a posteriori (MAP) :
Zi = k si tk (xi ) > tl (xi ) ∀l 6= k
Log-vraisemblance
l(θ,x1, . . . ,xn) =n∑
i=1
log fX(xi ) =n∑
i=1
logK∑
k=1
pk fk (xi )
On cherche alors θ = argmaxθ l(θ,x1, . . . ,xn)
32 / 77

MM : estimation
Algorithm 2 Algorithme EM
1: init. : choix aléatoire de θ(0)
2: while |l(θ(m),x1, . . . ,xn)− l(θ(m+1),x1, . . . ,xn)| < ε do3: étape E (estimation) : calculer
Q(θ, θ(m)) = Eθ(m) [l(θ,X1, . . . ,Xn,Z1, . . . ,Zn)|X1 = x1, . . . ,Xn = xn]
⇒ revient à calculer tk (xi ) = pk fk (xi )∑K`=1 p`fk (xi )
4: étape M (maximisation) : calculer
θ(m+1) = argmaxθQ(θ, θ(m))
5: end while
Rq : EM converge vers un maxi. local de l → plusieurs init.33 / 77
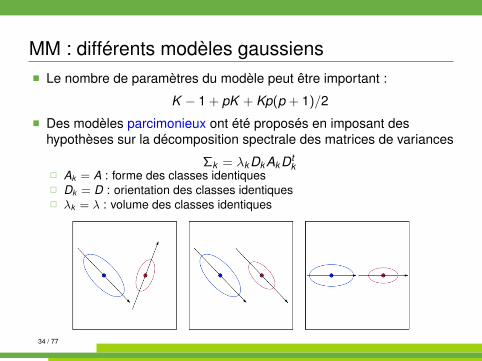
MM : différents modèles gaussiens� Le nombre de paramètres du modèle peut être important :
K − 1 + pK + Kp(p + 1)/2
� Des modèles parcimonieux ont été proposés en imposant deshypothèses sur la décomposition spectrale des matrices de variances
Σk = λk Dk Ak Dtk
� Ak = A : forme des classes identiques� Dk = D : orientation des classes identiques� λk = λ : volume des classes identiques
34 / 77

MM : choix de modèle
Des critères de vraisemblance pénalisée peuvent être utilisés pour� choisir le modèle le plus adapté,� choisir le nombre de clusters K
Critère BIC (à maximiser) :
BIC = 2l(θ,x1, . . . ,xn)− (d + 1) ln(n),
où d est le nombre de paramètres du modèles(d = K − 1 + pK + pK (K − 1)/2 pour le modèle gaussien complet)
35 / 77

MM : liens avec l’algorithme des kmeans
L’algorithme de centres mobiles (kmeans) est équivalent à un modèlegaussien très particulier :� les classes sont supposées sphériques et de même taille
Σk = λId
et les paramètres sont estimés avec une variante de l’algorithme EM :� algorithme CEM : les tk (xi ) calculés à l’étape E sont arrondis à 1
(pour la classe k maximisant tk (xi )) et à 0 pour les autres
36 / 77

MM : logiciels
Packages� Mclust{mclust}
� hddc{HDclassif} pour des modèles encore plus parcimonieuxpour les données en grande dimension
37 / 77
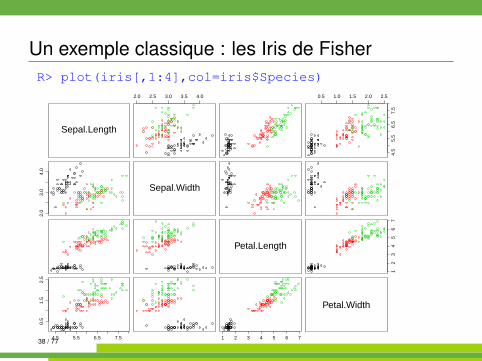
Un exemple classique : les Iris de FisherR> plot(iris[,1:4],col=iris$Species)
Sepal.Length
2.0 2.5 3.0 3.5 4.0 0.5 1.0 1.5 2.0 2.5
4.5
5.5
6.5
7.5
2.0
3.0
4.0
Sepal.Width
Petal.Length
12
34
56
7
4.5 5.5 6.5 7.5
0.5
1.5
2.5
1 2 3 4 5 6 7
Petal.Width
38 / 77

Un exemple classique : les Iris de Fisher
R> model=Mclust(iris[,1:4],G=1:5)R> summary(model)-----------------------------------Gaussian finite mixture model fitted by EM algorithm-----------------------------------Mclust VEV (ellipsoidal, equal shape) model with 2components:log.likelihood n df BIC ICL-215.726 150 26 -561.7285 -561.7289Clustering table:1 250 100
R> table(model$classification,iris$Species)setosa versicolor virginica
1 50 0 0
2 0 50 50
39 / 77

Un exemple classique : les Iris de Fisher
R> model=Mclust(iris[,1:4],G=1:5)R> summary(model)-----------------------------------Gaussian finite mixture model fitted by EM algorithm-----------------------------------Mclust VEV (ellipsoidal, equal shape) model with 2components:log.likelihood n df BIC ICL-215.726 150 26 -561.7285 -561.7289Clustering table:1 250 100
R> table(model$classification,iris$Species)setosa versicolor virginica
1 50 0 0
2 0 50 50
39 / 77

Un exemple classique : les Iris de Fisher
R> model=Mclust(iris[,1:4],G=3)R> summary(model)-----------------------------------Gaussian finite mixture model fitted by EM algorithm-----------------------------------Mclust VEV (ellipsoidal, equal shape) model with 3components:log.likelihood n df BIC ICL-186.0736 150 38 -562.5514 -566.4577Clustering table:1 2 350 45 55
R> table(model$classification,iris$Species)setosa versicolor virginica
1 50 0 02 0 45 0
3 0 5 5040 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R41 / 77

K-means for big data
Quels problèmes peut-on rencontrer ?� volume important de données : comment réduire le temps de calcul ?� variété des données : comment réaliser un clustering lorsque les
données ne sont pas toutes de même nature (quantitative etcatégorielle par exemple) ?
� vélocité : que faire si la base de données grandit continuellement ?
Quelles solutions ?� volume important de données : introduire du calcul parallèle /
distribué.� variété des données : définir de nouveaux algorithmes (package
Rmixmod sous R), plonger les données dans un même espace (viades analyse factorielle par exemple...)
� vélocité : définir des algorithmes online (sequential k-means)42 / 77

K-means pour grands volumes de données
� il est possible d’améliorer l’algorithme des K-means d’un point de vuetemps de calcul� en parallélisant le calcul pour différentes valeurs de K� en parallélisant les calculs à l’intérieur de l’algorithme
� mais attention à la gestion de la mémoire :� le temps de duplication des données et de récupération des résultats peut
parfois l’emporter sur le gain obtenu en parallélisant.� plusieurs travaux proposent une implémentation Map Reduce de
l’algorithme des K-means.� Zhao et al. 2009� Anchalia et al. 2013
43 / 77

Calcul parallèle sous R
Plusieurs packages sont disponibles pour faire du calcul parallèle.
Exemple de calcul parallèle sous Rlibrary(foreach)library(parallel)library(doParallel)cl <- makeCluster(3)registerDoParallel(cl)result = foreach(K = classes,.combine=’c’) %dopar%code à exécuter en parallèlestopCluster(cl)
44 / 77

Calcul parallèle sous R
Exemple de k-means en parralèle sous� data MNIST : http://yann.lecun.com/exdb/mnist/
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
7
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
6
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
7
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
8
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
3
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
3
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
9
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
1
� parallélisation sur le nombre de clusters :source(parallel-computing.R)
45 / 77

Map Reduce sous R
Les calculs parallèles précédents nécessitent de passer en mémoire àchaque processeur l’ensemble des données.� le transfert des données et la récupération des résultats peut réduire
l’intérêt du calcul parallèle, surtout si� les données sont volumineuse� les calculs à réaliser sont rapides
� une alternative consiste à distribuer les calculs et les données : MapReduce
tutoriel par RevolutionAnalytics
une introduction à l’aide de RHadoop sera présentée et expérimentéeen TD.
46 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R47 / 77

Mise en application
L’objectif de ce premier TP est d’apprendre à réaliser sous R un calculen parallèle.Pour cela :� simuler une grosse matrice de taille n × p,� calculer séquentiellement la moyenne de chaque colonne puis en
parallèle,� évaluer le gain (la perte ?) de temps en fonction des valeurs de n et
p,� comparer à l’utilisation de la fonction colMeans ou apply.Mettez cela en pratique pour réaliser un clustering des données MNISTpour différents nombre de clusters.
48 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R49 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R50 / 77

Comparaison de méthodes (1/2)
Comment comparer différentes méthodes de classification supervisée ?
Les pièges à éviter� erreur apparente : comparer des méthodes en terme de taux de bon
classement sur l’échantillon d’apprentissage ayant servi à estimer lesparamètres favorisera toujours les méthodes les plus complexes
51 / 77

Comparaison de méthodes (1/2)
Comment comparer différentes méthodes de classification supervisée ?
On utilisera� un échantillon test : le taux de bon classement sera évalué sur un
échantillon test n’ayant pas servi à estimer les règles de classement(découpage éch. existant en 2/3 apprentissage 1/3 test)
� la validation croisée (cross validation - CV) Leave One Out
CV =1n
n∑i=1
1Iz(i)=zi
où z(i) est la prédiction de la classe du ième individu obtenu sansutiliser cet individu pour estimer les paramètres du modèle
� la validation croisée K-fold où l’échantillon d’apprentissage estdécoupé en K partie, chaque partie servant tour à tour d’échantillontest (leave one out = n-fold)
� un critère de choix de modèles (BIC) pour les méthodes probabilistes52 / 77
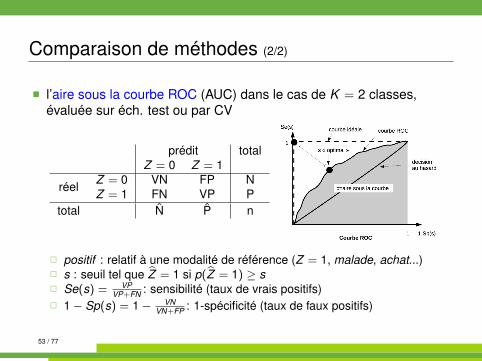
Comparaison de méthodes (2/2)
� l’aire sous la courbe ROC (AUC) dans le cas de K = 2 classes,évaluée sur éch. test ou par CV
prédit totalZ = 0 Z = 1
réel Z = 0 VN FP NZ = 1 FN VP P
total N P n
� positif : relatif à une modalité de référence (Z = 1, malade, achat...)� s : seuil tel que Z = 1 si p(Z = 1) ≥ s� Se(s) = VP
VP+FN : sensibilité (taux de vrais positifs)� 1− Sp(s) = 1− VN
VN+FP : 1-spécificité (taux de faux positifs)
53 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R54 / 77

K plus proches voisins (K NN)Idées :� On compte parmi les K plus proches voisins d’un points x à classer le
nombre de points nk de chaque classe (1 ≤ k ≤ K ).� On estime alors la probabilité que x appartienne à la classe k par :
tk (x) =nk
K
55 / 77

K plus proches voisins (K NN)
Remarques� choix de K crucial : CV, AUC, éch. test...� plus n est grand, plus on peut se permettre de prend un K grand
Packages� k-NN{class}
56 / 77

Exercice
� Prédire l’appartenance du point X5 = 4 à l’une des deux classessuivantes, par la méthode K NN avec différentes valeurs de K :� classe 1 : X1 = 0, X2 = 2� classe 2 : X3 = 6, X4 = 11
57 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R58 / 77

Analyse discriminante probabiliste (DA)
Idées :� Les modèles de mélanges peuvent également être utilisés en
classification supervisée.� L’estimation par maximum de vraisemblance immédiate (EM inutile)
Variables quantitatives : modèles gaussiens� Linear Discriminant Analysis (LDA) : X|Z = k ∼ N (µk ,Σ)
� Quadratic Discriminant Analysis (QDA) : X|Z = k ∼ N (µk ,Σk )
59 / 77

DA : estimation et choix de modèle
Estimation� pk = nk
n où nk est le nombre d’observations de la classe k (Gk )
� µk = 1nk
∑xi∈Gk
xi
� Σ = 1n
∑Kk=1
∑xi∈Gk
(xi − µk )t (xi − µk ) pour LDA
� Σk = 1nk
∑xi∈Gk
(xi − µk )t (xi − µk ) pour QDA
Choix de modèle� critère probabiliste (BIC) ou CV, AUC, ...
60 / 77

DA : règle de classement optimale
� coût de mal classer un individu de Gl (classe l) dans Gk (classe k ) :
C : (k , l) ∈ {1, . . . ,K} × {1, . . . ,K} → C(k , l) ∈ R+,
� règle optimale de Bayes : on classe X = x dans Gk si :
K∑l 6=k
C(k , l)tl (x) <K∑
l 6=k ′
C(k ′, l)tl (x) ∀k ′ 6= k
� cas d’égalité des coÃzts (MAP):� on classe X = x dans Gk si tk (x) > tl (x) ∀l 6= k
� cas de deux classes :� on classe X = x dans G1 si g(x) = C(2,1)t1(x)
C(1,2)t2(x)> 1.
� g(x) = 1 définit la surface discriminante
61 / 77
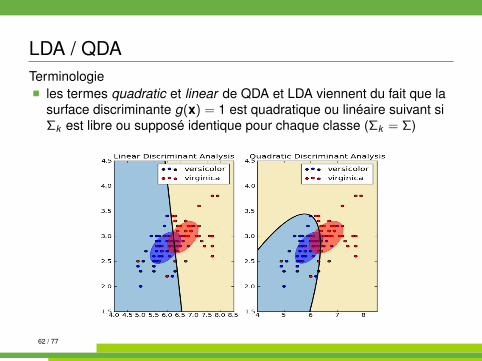
LDA / QDATerminologie� les termes quadratic et linear de QDA et LDA viennent du fait que la
surface discriminante g(x) = 1 est quadratique ou linéaire suivant siΣk est libre ou supposé identique pour chaque classe (Σk = Σ)
62 / 77

DA : logiciels
Packages� lda{MASS}
� qda{MASS}
� MclustDA{mclust} pour plus de modèles pour donnéesquantitatives
� hdda{HDclassif} pour des modèles encore plus parcimonieuxpour les données en grande dimension
63 / 77

Exercice� Prédire l’appartenance du point X5 = 4 à l’une des deux classes
suivantes, à l’aide des modèles LDA et QDA :� classe 1 : X1 = 0, X2 = 2� classe 2 : X3 = 6, X4 = 11
Corrections :QDA� p1 = p2 = 0.5� classe 1 : µ1 = 1, σ2
1 = 2� classe 2 : µ2 = 8.5, σ2
2 = 12.5� t1(4) = 0.5fN (4,1,2)
0.5fN (4,1,2)+0.5fN (4,8.5,12.5) = 0.37
LDA� σ2 = 7.25� t1(4) = 0.5fN (4,1,7.25)
0.5fN (4,1,7.25)+0.5fN (4,8.5,7.25) = 0.68
64 / 77

Exercice� Prédire l’appartenance du point X5 = 4 à l’une des deux classes
suivantes, à l’aide des modèles LDA et QDA :� classe 1 : X1 = 0, X2 = 2� classe 2 : X3 = 6, X4 = 11
Corrections :QDA� p1 = p2 = 0.5� classe 1 : µ1 = 1, σ2
1 = 2� classe 2 : µ2 = 8.5, σ2
2 = 12.5� t1(4) = 0.5fN (4,1,2)
0.5fN (4,1,2)+0.5fN (4,8.5,12.5) = 0.37
LDA� σ2 = 7.25� t1(4) = 0.5fN (4,1,7.25)
0.5fN (4,1,7.25)+0.5fN (4,8.5,7.25) = 0.6864 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R65 / 77

k-NN for big data
Quels problèmes peut-on rencontrer ?� volume important de données : comment réduire le temps de calcul ?� variété des données : comment réaliser une classification lorsque les
données ne sont pas toutes de même nature (quantitative etcatégorielle par exemple) ?
� vélocité : que faire si de nouvelles données arrivent continuellement ?
Quelles solutions ?� volume important de données : introduire du calcul parallèle /
distribué.� variété des données : définir de nouveaux algorithmes (package
Rmixmod sous R), plonger les données dans un même espace (viades analyse factorielle par exemple...)
� vélocité : définir des algorithmes online (online SVM...)66 / 77

k-NN pour grands volumes de données
� il est possible d’améliorer l’algorithme des k-NN d’un point de vuetemps de calcul� en parallélisant le calcul pour différentes valeurs de k� en parallélisant les calculs à l’intérieur de l’algorithme
� mais attention à la gestion de la mémoire :� le temps de duplication des données et de récupération des résultats peut
parfois l’emporter sur le gain obtenu en parallélisant.� plusieurs travaux proposent une implémentation Map Reduce de
l’algorithme des k-NN.� Anchalia et al. 2014
67 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R68 / 77

Mise en application
L’objectif de ce TP est d’apprendre à utiliser l’algorithme des k-NN et decalibrer son hyper-paramètre.Pour cela :� extraire de la base de données MNIST un échantillon test,� utiliser cet échantillon pour calibrer la valeur de k de l’algorithme des
k-NN. Cette calibration se fera séquentiellement et en parallèle.� évaluer le gain (la perte ?) de temps de calcul due à l’utilisation du
calcul parallèle.
69 / 77

PlanIntroduction au Data MiningLes Big DataClassification non supervisée
GénéralitésMéthode des centres mobiles (kmeans)Modèles de mélangesK-means for big dataMise en application
Classification superviséeGénéralitésMéthode des K plus proches voisinsModèles de mélanges et analyse discriminantek-NN for big dataMise en application
Map Reduce sous R70 / 77

Map Reduce sous R
Références� Wikistat de Ph. Besse (dont est inspiré cette partie du cours)
https://www.math.univ-toulouse.fr/∼besse/Wikistat/pdf/st-tutor5-R-mapreduce.pdf
� tutoriel par RevolutionAnalyticshttps://github.com/RevolutionAnalytics/rmr2/
blob/master/docs/tutorial.md
71 / 77

Map Reduce sous R
Objectif du cours� utiliser le package rmr2 pour simuler des gestions de fichiers HDFS
sans Hadoop� écrire des fonctions Map et Reduce dans R
Installation� rmr2 non disponible sur le CRAN, à télécharger sous GitHub.� l’installation peut dépendre d’autres packages qu’il faut également
installer.
Chargement� > library(rmr2)
� pour utiliser RHadoop sans Hadoop :> rmr.options(backend = "local")
72 / 77

Map Reduce sous R
Fonctions de rmr2� keyval, values, key crée des paires (clef,valeur) ou extrait les
valeurs (resp. clefs) de ces paires,� to.dfs(kv,output) où kv est une liste de (clef,valeur) ou un objet
R; output est un fichier big data.� from.dfs(input) transforme l’objet big data en entreée en un
objet R : liste de (clef,valeur) en mémoire.� mapreduce aplique à l’input les fonctions map, reduce etcombine écrite en R, pour produire en output un objet big data.
Les objets manipulés par les fonction to.dfs et from.dfs transitentpas la mémoire et ne peuvent donc pas être très volumineux. Elles sontsurtout utilisés pour les tests.
73 / 77

Map Reduce sous R
Exemple d’échantillonnage binomial� on génère un échantillon de 50 valeurs de loi B(32,0.4) :> groups = rbinom(32, n = 50, prob = 0.4)
� on souhaite énumérer les valeurs obtenues et compter leur nombred’occurence, ce qui peut être fait par :> tapply(groups, groups, length)
� mais ici l’objectif est d’illustrer l’utilisation des couples (clef,valeur) deMap Reduce
74 / 77

Map Reduce sous R
� transformer l’objet R en un objet big data :> groupe = to.dfs(groups)
� la fonction map associe une paire (entier, 1) à chaque valeur ouentier présent dans ’groupe’ :> mymap = function(., v) keyval(v, 1)par défaut , les clefs de même ’valeur’ sont associées dans une listeou un vecteur.
� pour une valeur de clef donnée, la fonction reduce compte le nombrede 1 :> myreduce = function(k, vv) keyval(k, length(vv))
� on peut ensuite appeler la fonction mapreduce :> result = mapreduce(input = groupe, map=mymap,reduce=myreduce)
75 / 77

Map Reduce sous R
� on peut transfromer l’objet big data (clef,valeur) obtenu en un objet R :> from.dfs(result)$key10 13 16 6 21 12 11 14 15 9 7 8 17$val4 12 5 1 1 6 3 8 5 2 1 1 1
76 / 77

Mise en application
En vous inspirant du tutoriel Wikistat, programmer l’algorithme dek-means, avec :� une étape Map qui distribue les données au cluster dont le centre est
le plus proche� une étape Reduce qui calcule le barycentre des points associés à
une même classe
77 / 77








![Fouille des données - mma.perso.eisti.frmma.perso.eisti.fr/HTML-DM/Cours/Cours1/datamining.pdf · utiles et compréhensibles [Fayyad et al., 1995] Fouille des donnees – p. 2/´](https://img.pdfslide.fr/doc/110x75/5b99404f09d3f26e678b8f6b/fouille-des-donnees-mmapersoeistifrmmapersoeistifrhtml-dmcourscours1.jpg)