Embed Size (px)
Citation preview

© Masson, Paris, 2004. Rev Epidemiol Sante Publique, 2004, 52 : 139-149
L’analyse de cluster en épidémiologie géographique : utilisation de plusieurs méthodes statistiques et comparaison de leurs résultatsCluster analysis in geographical epidemiology: the use of several statistical methods and comparisonof their results
E. CHIRPAZ(1), M. COLONNA(1), J.-F. VIEL(2)
(1) Registre des Cancers de l’Isère, 21, chemin des Sources, 38240 Meylan. Email : [email protected] (Tirés à part : E. Chirpaz,Centre Hospitalier Félix Guyon, Bellepierre, 97405 Saint Denis Cedex)(2) Département de Santé Publique, Unité de Biostatistiques et d’Épidémiologie, Faculté de Médecine, 2, place Saint-Jacques,25030 Besançon.
Background: The increasing interest in environmental epidemiology has been followed by the deve-lopment of many statistical tests for detecting disease clustering near a point source. The objectivesof this study were to compare several tests to detect disease clustering, among which modelisationusing Markov Chain Monte Carlo methods.
Methods: We compared six statistical methods for detecting disease clustering of bladder canceraround an industrial centre of Isère (France) for the period 1983-1997: Stone’s test, score test, andtwo log-linear modelisations (with and without corrections for extra-Poisson variations) using twoways of parameters estimation (maximum likelihood and Markov Chain Monte Carlo methods).
Results: The results of the Stone test and the score test are not in favour of a higher risk of bladdercancer around the considered point source. The conclusions brought by the log linear modelisationsare the same, but the results obtained using the Markov Chain Monte Carlo Method are very depen-dant of prior distributions determined for the different parameters.
Conclusion: Markov Chain Monte Carlo methods, which allow taking into account complex geogra-phical effects, seem well adapted to cluster analysis in geographical epidemiology. However, theyremain difficult to implement.
Geographical epidemiology. Cluster analysis. Markov Chain Monte Carlo methods.
Position du problème : L’engouement pour l’épidémiologie environnementale de ces dernièresannées a naturellement été accompagné par un développement des méthodologies statistiques qui luisont applicables. C’est le cas pour l’analyse de cluster géographique, domaine comportant de nom-breuses contraintes plus ou moins spécifiques. Cette étude compare plusieurs tests d’analyse de clus-ter, dont des modélisations utilisant les méthodes de Monte Carlo par chaîne de Markov.
Méthodes : Nous avons appliqué 6 méthodes d’analyse de cluster sur les données agrégées parcommune d’incidence du cancer de la vessie (période 1983-1997) autour d’un pôle industriel del’Isère ; les 72 communes situées dans un rayon de 18 km autour du point source considéré ont étéretenues pour l’étude. Les 6 méthodes comparées sont le test de Stone, le test du score et deux modé-lisations log-linéaires (l’une intégrant un paramètre de correction des variations extra-poissoniennes,l’autre non), dont les paramètres ont été estimés par deux techniques, maximisation de la vraisem-blance et méthodes de Monte Carlo par chaîne de Markov (échantillonneur de Gibbs).
Texte reçu le 6 février 2003. Acceptation définitive le 25 novembre 2003.

140 E. CHIRPAZ ET COLLABORATEURS
Résultats : Les différents tests utilisés ne permettent pas de rejeter l’hypothèse nulle d’absence desur-incidence de cancer de la vessie autour du pôle industriel considéré. Cependant, les estimationsbayésiennes obtenues pour ces mêmes modèles grâce aux estimations par les méthodes de Monte Carlosont très dépendantes du choix des lois a priori des paramètres des modèles.
Conclusions : Les caractéristiques techniques des méthodes MCMC et la possibilité de prise encompte de phénomènes géographiques complexes en font un outil statistique qui parait bien adapté àl’analyse de cluster en géographie ; il reste que ce sont des méthodes délicates à mettre en œuvre.Épidémiologie géographique. Analyse de cluster. Méthodes de Monte Carlo par chaîne de Markov.
INTRODUCTION
L’épidémiologie environnementale a connu unfort engouement ces dernières décennies. La prisede conscience de plus en plus importante des ris-ques sanitaires environnementaux a mené beau-coup de professionnels de la santé à travailler surles problématiques de l’impact sur la santé despollutions atmosphérique ou de l’eau, des conta-minations par la radioactivité ou encore deschamps électromagnétiques. Le développementde la recherche dans ces domaines a naturelle-ment été suivi de celui des méthodes épidémiolo-giques et notamment des méthodes d’analysegéographique.
Parmi ces méthodes d’analyse géographique, ily a des méthodes descriptives (telles les métho-des de représentation cartographique, de lissage,d’évaluation de l’auto-corrélation spatiale ou del’hétérogénéité géographique) et des méthodesdites « d’analyse de clusters » [1]. L’objet de cesdernières est la mise en évidence d’agrégats(clusters) d’un événement étudié dans une zonegéographique déterminée. Elles comprennent les« tests généraux » (« general tests »), pour les-quels il n’y a aucune hypothèse a priori quant àla distribution du phénomène mesuré (ils tententde localiser d’éventuels foyers dans toute larégion considérée) et les « tests focalisés »(« focused tests ») dont l’objet est d’étudier lelien entre un point source pré-déterminé supposépouvoir être à l’origine d’un problème sanitaire etcet événement sanitaire, qui sera alors concentréautour de ce point source sous la forme d’unfoyer de cas [1-4].
C’est à cette dernière classe de tests que nousnous sommes intéressés. Ces tests focalisésd’analyse de cluster (TFAC) posent plusieursproblèmes méthodologiques qui leurs sont plusou moins spécifiques ; ils doivent en effet inté-
grer la dimension géographique, ce qui nécessitenotamment une mesure du facteur de risque étu-dié dans l’espace. Cette information étant souventindisponible, c’est classiquement la distance aupoint source qui tient lieu d’indicateur d’exposi-tion. Ceci pose des problèmes quant à l’interpré-tation du lien entre le point source et l’éventuellesur-représentation de l’événement étudié à saproximité, et impose d’avoir formulé à l’avance(avant toute observation) l’hypothèse de relationcausale entre l’exposition et le phénomène consi-déré. Cette intégration de la dimension spatialerepose souvent sur une segmentation de la régionétudiée en sous-unités, dans lesquelles on varecenser l’événement étudié. Ces sous-unités sontalors considérées comme les unités statistiques :on parle d’analyse sur données agrégées. La seg-mentation retenue est en général administrative(communes, cantons,…) afin de disposer dedénominateurs pour les taux que l’on veut étu-dier. Ceci induit souvent une importante hétéro-généité de taille entre les populations, et donc uneforte variabilité dans la précision des estimateursconsidérés, qui sont souvent le Ratio Standardiséd’Incidence (SIR : Sandardized Incidence Ratio)ou le Ratio Standardisé de Mortalité (SMR :Standardized Mortality Ratio) [1]. Par ailleurs,lorsque les valeurs centrales des estimateurs pre-nant en compte l’exposition sont elles aussi hété-rogènes, par exemple en raison de l’effet devariables non mesurées, cette seconde source devariabilité entraîne des variations des estimateursen excès par rapport à celles attendues sous unmodèle de Poisson [5, 6]. Ces variations peuventavoir une influence sur les résultats des testsd’association [7]. Plusieurs méthodes permettentde modéliser l’excès de variation de l’estimateurétudié. Parmi celles-ci, les méthodes bayésiennes[1, 7-9] ont beaucoup été utilisées depuis le débutdes années 1990, grâce au développement destechniques statistiques complexes utilisant les

MÉTHODES D’ANALYSE DES CLUSTERS EN ÉPIDÉMIOLOGIE GÉOGRAPHIQUE 141
méthodes de Monte Carlo par chaîne de Markov(méthodes MCMC).
Il existe ainsi de nombreux TFAC, reposant surdes hypothèses et des méthodes statistiques variées.Cet article présente une comparaison de plusieursde ces tests pour données agrégées. Deux de cestests sont parmi les tests les plus fréquemment citésdans ce domaine : ce sont le test de Stone [10] et letest du score [11, 12]. Nous les avons comparésaux résultats que donnent plusieurs modèles log-linéaires dont l’estimation des paramètres utilisedifférentes approches statistiques : l’approche dite« fréquentiste » (estimation des paramètres parmaximisation de la vraisemblance, méthode MV)et l’approche dite « bayésienne » (avec estimationdes paramètres en utilisant les méthodes MCMC).Ces tests ont été appliqués sur les données d’inci-dence du cancer de la vessie autour d’un pôleindustriel du département de l’Isère.
POPULATIONS ET MÉTHODES
POPULATIONS
Le point source que nous avons pris en compte pour cetteétude est une concentration géographique d’industries tra-vaillant principalement dans la pétrochimie et dans la métal-lurgie, industries qui utilisent des carcinogènes connus ducancer de la vessie. Ce cancer des pays industrialisés [13] estle sixième cancer en France en termes d’incidence, les deuxsexes confondus, avec 10 105 cas estimés en 1995 [14]. Il estattribué dans plus de 40 % des cas au tabac et dans plus de25 % des cas aux expositions professionnelles à des toxiques[15-18]. Dans la mesure où il n’existe pas de données assezfines de la pollution atmosphérique, c’est la distance au pointsource (point central du pôle industriel) qui tient lieu d’indiced’exposition. Nous avons limité l’étude à une région circu-laire centrée par le point source et d’un rayon de 18 km, dis-tance paraissant suffisante pour la mesure de l’éventuelimpact de la pollution atmosphérique générée par ce pôleindustriel [19, 20].
Le choix de la taille de l’unité statistique (unité géographi-que divisant la zone d’étude) est un compromis entre les aspectsstatistiques (leur trop grande taille dilue les effets observés, leurtrop petite taille induit trop de variabilité dans les estimations)et les aspects géographiques [21] ; la proximité de la ville deGrenoble du point source et la présence des montagnes quiinduisent de trop grandes variations dans la taille des cantonsnous ont fait choisir la commune comme unité d’agrégation(figure 1). Ainsi, 72 communes ordonnées par la distance deleur centroïde au point source ont été retenues.
Les données d’incidence proviennent du Registre des Can-cers de l’Isère ; tous les cancers de la vessie (code topographi-que 188 de la Classification internationale des maladies-oncologie (ICD-O première édition)) pour la période 1983-
1997 des sujets résidant dans les 72 communes sélectionnéesont été considérés. Le nombre de cas attendus pour chacunedes 72 communes a été calculé en se référant aux taux d’inci-dence moyens pour ces 72 communes (taux de référenceinternes), par sexe et par classe d’âge de 5 ans (0-4, 5-9, …,90-94, 95 ans et plus), taux paraissant plus adéquats que lestaux départementaux dans la mesure où la zone d’étudeconcerne en grande partie des communes urbaines ou périur-baines, très industrialisées, donc non représentatives del’ensemble du département. Le nombre de personnes x annéesexposées par commune, par sexe et par année d’âge a été cal-culé à partir des données des trois recensements de 1982,1990 et 1999 (données de l’INSEE). Nous avons utilisé laméthode diagonale simple [22] pour estimer les populationsinter-censitaires, excepté pour les classes d’âge des sujetsâgés moins de 10 ans (0-4 ans, 5-9 ans) et des sujets âgés deplus de 84 ans (85-89 ans, 90-94 ans, 95 ans et plus) pour les-quelles l’absence respective de classes d’âge inférieures etsupérieures nous a imposé la méthode horizontale. Au total,l’étude porte sur 1 543 cas de cancer de la vessie enregistréspar le Registre des Cancers de l’Isère dans les 72 communesde l’étude. Les populations dans ces 72 communes sont trèshétérogènes, avec un peu plus de 130 habitants recensés en1990 dans la commune la moins peuplée et plus de 150 000pour la ville de Grenoble.
MÉTHODES
Soit une région divisée en N unités géographiques(i = 1,…,N) dans chacune desquelles sont observés yi cas d’unphénomène pour ni personnes-années. Dans chacune des uni-tés i, si les yi événements observés sont rares par rapport auxni personnes années, yi suit une loi de Poisson.
FIG. 1. — Carte de la zone étudiée : SIR observés parcommune.
SIR : 0.00 - 0.63
SIR : 0.63 - 1.07
Point Source
SIR : 1.25 - 2.30
SIR : 1.07 - 1.25

142 E. CHIRPAZ ET COLLABORATEURS
Sous l’hypothèse nulle H0 d’absence d’agrégat et d’indé-pendance des événements (on est donc hors du cadre desmaladies infectieuses), le nombre de cas attendus pour l’unitégéographique i est égal à :
E(yi) = Ei (équation (1))
où est le taux de réalisation de l’événement considéré ; Ei
est l’effectif attendu (population exposée) pour la zone géo-graphique i, après ajustement sur les facteurs de confusionsconnus.
Lors de la présence d’un agrégat, plusieurs hypothèsesalternatives H1 sont envisageables en fonction des hypothèsesfaites sur la « forme » de l’agrégat [11] : l’hypothèse d’unedifférence de risque qui est constante pour une même diffé-rence d’exposition, quel que soit le niveau moyen de l’expo-sition, définit un modèle additif ; par contre, un modèlemultiplicatif signifie un rapport de risques constant pour unemême différence d’exposition, donc une différence de risquequi dépend du niveau moyen d’exposition. D’autres hypothè-ses sont envisageables, comme la décroissance monotone durisque sans hypothèse sur la forme de cette décroissance,décrite par Stone [10]. Les 3 types de modèles vont être étu-diés successivement dans cet article.
Pour les modèles multiplicatifs, l’hypothèse alternative est :
E(yi) = Ei exp(gi ) (modèle (2))
Les paramètres de ce modèle log-linéaire, communémentappelé « régression de Poisson » [23], sont estimables par laméthode MV.
RRi = exp(gi ) est le risque relatif mesurant l’excès de ris-que de l’événement considéré dans l’unité géographique i parrapport au taux de référence ; exprime l’évolution du risquepar unité d’exposition, et gi l’exposition pour l’unité géogra-phique i. Comme explicité dans l’introduction, lorsque lamesure du niveau d’exposition est indisponible, c’est la dis-tance au point source qui tient souvent lieu d’indicateurd’exposition. Alors, en général, gi est de la forme 1/di (di =distance du centroïde de l’unité géographique considérée parrapport au point source), de façon à ce que RRi tende vers 1quand di tend vers l’infini ; a contrario, cela implique que lerisque tend vers l’infini quand la distance tend vers 0, ce quiempêche d’envisager des observations au point source ou pro-ches de ce point source.
La régression binomiale négative est un modèle linéairemixte qui permet de tenir compte des variations extra-poisso-niennes en ajoutant dans le modèle (2) un paramètre ui de sur-dispersion. On obtient alors le modèle suivant :
E(yi) = Ei exp(gi + ui) (modèle (3))
avec exp(ui) ~ Gamma(1/ , 1/ )
exp(ui) suit une loi Gamma de moyenne 1 et de variance :plus est grand, plus la sur-dispersion est importante. Sousl’hypothèse = 0, ce modèle est équivalent au modèle (2) derégression de Poisson. Le rejet de cette hypothèse, par exem-ple à l’aide du rapport de vraisemblance, permet de conclureà l’existence d’une sur-dispersion.
Les estimations des paramètres des modèles (2) et (3) parla méthode MV ont été effectuées par le logiciel STATA 7.0[24].
Dans l’approche fréquentiste, les paramètres sont considé-rés comme des quantités inconnues et fixes. Seul leur estima-teur est aléatoire, l’intervalle de confiance à 95 %représentant l’étendue des valeurs dans laquelle se trouve-raient 19 estimations pour 20 échantillons. En inférencebayésienne, les paramètres (b) sont supposés suivre une loide probabilité dite a priori, de paramètre , notée P(b| ), quitient compte des connaissances que l’on a avant observation(notion de probabilité subjective [25]). La distribution desobservations est modélisée conditionnellement à la distribu-tion a priori par P(y|b, ); le théorème de Bayes permet alorsl’estimation des distributions a posteriori P(b|y, ) des para-mètres du modèle. L’inférence dite « purement bayésienne »(par opposition au « bayésien empirique ») implique l’inté-gration de la variabilité du paramètre (P(b|y) = P(b, |y)d ), en utilisant éventuellement les méthodes d’échantillon-nage MCMC. Les méthodes bayésiennes exigent de définir apriori le modèle et les lois de probabilité de ses paramètres.Les méthodes MCMC impliquent un grand nombre de simu-lations itératives qui utilisent les propriétés des chaînes deMarkov (la probabilité d’un événement est conditionnelle àson état antérieur) ; elles permettent l’estimation d’une distri-bution a posteriori de chacun de ces paramètres au moyend’une intégration par la méthode de Monte-Carlo. La loi aposteriori ainsi obtenue permet de calculer l’intervalle decrédibilité à 95 %, qui représente l’intervalle dans lequel il ya 95 % de chance que se trouve la « vraie » valeur du para-mètre estimé, interprétation souvent donnée de manière erro-née à l’intervalle de confiance que donnent les statistiquesfréquentistes.
L’un des aspects fondamentaux des méthodes bayésiennesest donc le choix des distributions a priori de chacun des para-mètres du modèle (l’absence d’hypothèses a priori amenant àutiliser des distributions dites « non informatives », par exem-ple uniformes sur l’étendue des valeurs possibles). Pour leparamètre , nous avons employé une loi Uniforme de mini-mum 0 et de maximum 3, faisant l’hypothèse que le risque nedoit pas diminuer quand on se rapproche du point source (ilpeut tout au plus rester stable si = 0), et que le RR maximumenvisageable pour la commune la plus proche du point sourcedont le centroïde est à 1,3 km est de 10 (= exp(3/1.3)). Pour leparamètre de sur-dispersion ui, nous avons utilisé commecommunément suggéré une loi normale de moyenne 0 dontl’inverse de la variance ( ) suit une loi gamma (conjuguée dela loi de Poisson) de moyenne 1 et de variance 103 [26].
Afin de tester la sensibilité des résultats des modélisationsaux choix des distributions a priori des paramètres dumodèle, nous avons ensuite réitéré des estimations en faisantvarier les paramètres de ces lois a priori. Pour le paramètre
, le minimum a été rabaissé à – 1 (hypothèse de décrois-sance possible du risque à l’approche du point source avecun RR minimum à 0,5 pour la commune la plus proche dupoint source), le maximum relevé à 3,9 (RR maximum pourla commune la plus proche du point source à 20) ; nous avonsenfin utilisé une loi a priori qui peut être considérée commenon informative avec un minimum à – 6 (RR minimum à0,01 pour la commune la plus proche du point source) et unmaximum à 5 (RR maximum pour la commune la plus pro-che du point source à 50). En ce qui concerne le paramètrede sur-dispersion ui, nous avons fait varier la variance ( ) dela loi gamma à 102 et 104.

MÉTHODES D’ANALYSE DES CLUSTERS EN ÉPIDÉMIOLOGIE GÉOGRAPHIQUE 143
Les estimations portent sur 30 000 itérations, par algo-rithme de l’échantillonneur de Gibbs (Gibbs Sampling) sur lelogiciel Winbugs 1.2 [27] ; le contrôle de convergence del’algorithme a été fait de manière graphique [28] ; pour lesdifférentes simulations effectuées, la convergence a été obte-nue au terme de 7 000 à 10 000 itérations. Le paramètre devaleur centrale de la loi a posteriori retenu est la médiane, lesintervalles de crédibilité à 95 % étant définis par les percenti-les d’ordre 2,5 % et 97,5 %.
Il existe des tests propres à l’analyse de cluster [5, 21] quisortent du cadre des modèles linéaires généralisés. Le test duscore, décrit par Lawson et Waller [11, 12] est un test de ten-dance pour variable aléatoire de Poisson. Il reprend l’hypo-thèse nulle H0 décrite par l’équation (1), et a une hypothèsealternative basée sur le modèle additif :
E(yi) = Ei(1+ gi ) (modèle (4))
Il est défini par la statistique U :
qui a sous H0 une distribution asymptotiquement normaled’espérance nulle et de variance (si utilisation de taux de réfé-rence interne) :
À noter que les modèles multiplicatif (modèle (2)) et addi-tif (modèle (4)) sont équivalents en cas de faible effet del’exposition [5], situation qui est peu adaptée aux études épi-démiologiques [29].
L’hypothèse alternative du test de Stone [10, 30] est plusgénérale que celles des modèles log-linéaires (basés sur uneaugmentation multiplicative du risque) ou du test du score(augmentation additive) : cette hypothèse alternative est ladécroissance monotone du risque avec l’augmentation de ladistance par rapport au point source (H1 : RR1 RR2 …
RRN, les N unités géographiques (i = 1 à N) étant ordonnéesen fonction de leur distance croissante par rapport au pointsource, sans hypothèse sur la forme de cette décroissance. Cetest qui est ainsi parfois qualifié de non paramétrique, est basésur une régression isotonique de Poisson qui s’appuie sur letest de l’hypothèse nulle d’égalité des RRi, les yi suivant uneloi de Poisson. Il consiste à déterminer le SIR (ou SMR)maximum cumulé autour du point source (T ), en construisantde manière successive des régions emboîtées de tailles crois-santes autour de ce point source :
E(yi) = ( Ei, nombre de cas attendus pour l’unité géogra-phique i sous H0.
La distribution de T est estimée par un algorithme récursifqui permet de calculer le niveau de signification du test pourla zone géographique sélectionnée comme ayant l’estimateur(SIR ou SMR) le plus élevé.
RÉSULTATS
L’évolution des SIR en fonction de la distanceau point source est décrite par la figure 2.L’impression graphique de leur décroissanceavec l’augmentation de la distance par rapport aupoint source est confirmée par la régression dePoisson (modèle (2)) avec estimation des para-mètres par la méthode MV (gi égal à 1/di) : leparamètre est estimé à 0,55, mais n’est pas signi-ficativement différent de 0 (intervalle deconfiance à 95 % (ICo 95 %) = – 0,14 ; 1,24).L’estimation du RR pour la commune la plus pro-che du point source (à 1,3 km) est de 1,43 (ICo95 % = 0,84 ; 2,43). L’adéquation du modèle auxdonnées est bonne puisque le 2 d’adéquation està 74,8 pour 70 degrés de liberté (p = 0,3), ce quiest en faveur d’une absence de variation extra-poissonienne. La régression binomiale négative(modèle (3), toujours avec gi égal à 1/di) le con-firme, puisque l’estimation du paramètre estalors assez proche de celle obtenue par le modèle(2), de 0,63 (ICo 95 % = – 0,3 ; 1,38) et lavariance de l’estimateur du paramètre de sur-dispersion est minime, estimée à 0,002 (non dif-férente de 0 ; p = 0,3).
Les estimations ponctuelles du paramètre enutilisant les méthodes MCMC, avec pour loi apriori sur ce paramètre la loi Uniforme de mini-mum 0 et de maximum 3, sont assez proches decelles obtenues par la méthode MV (tableau I,figure 3). Les intervalles de crédibilité à 95 %(ICr95 %) sont, par contre, plus étroits que lesintervalles de confiance obtenus par la méthodeMV, respectivement de (0,06 ; 1,22) et (0,08 ;1,45) pour le modèle (2) et le modèle (3). Les RRpour la commune la plus proche du point sourcesont de 1,44 pour le modèle (2) (ICr95 % = 1,04 ;2,19]) et de 1,52 pour le modèle (3) (ICr95 %= 1,01 ; 1,56) (tableau II). Cependant, ces résul-tats sont peu robustes par rapport aux choix desparamètres des lois a priori : l’augmentation del’étendue des valeurs de la loi Uniforme définie apriori pour le paramètre a une influence surl’estimation ponctuelle de ce paramètre, et sur-tout les bornes de l’intervalle de crédibilité de ce
U gi yi Ei–
i 1=
N
= (équation (5))
Variance (U) gi2
Ei
i 1=
N
yEi gi
E+------------
i 1=
N 2
+–= (équation (6))
T max1 n N
yi
i 1=
n
E yi
i 1=
n----------------------= (équation (7))
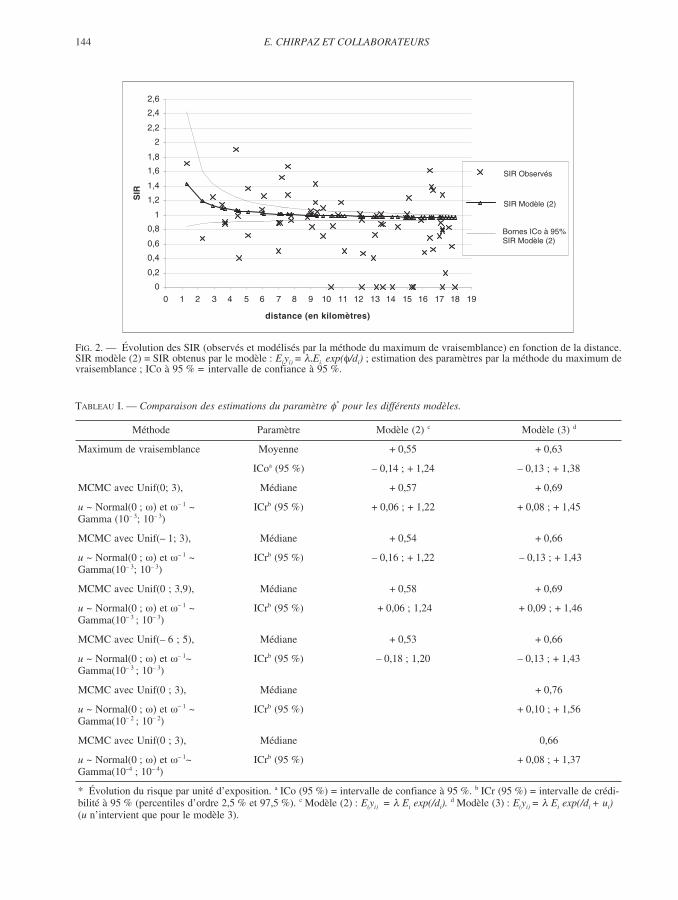
144 E. CHIRPAZ ET COLLABORATEURS
FIG. 2. — Évolution des SIR (observés et modélisés par la méthode du maximum de vraisemblance) en fonction de la distance.SIR modèle (2) = SIR obtenus par le modèle : E(yi) = Ei. exp( /di) ; estimation des paramètres par la méthode du maximum devraisemblance ; ICo à 95 % = intervalle de confiance à 95 %.
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1,6
1,8
2
2,2
2,4
2,6
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
distance (en kilomètres)
SIR
SIR Observés
SIR Modèle (2)
Bornes ICo à 95% SIR Modèle (2)
TABLEAU I. — Comparaison des estimations du paramètre * pour les différents modèles.
Méthode Paramètre Modèle (2) c Modèle (3) d
Maximum de vraisemblance Moyenne + 0,55 + 0,63
ICoa (95 %) – 0,14 ; + 1,24 – 0,13 ; + 1,38
MCMC avec Unif(0; 3), Médiane + 0,57 + 0,69
u ~ Normal(0 ; et – 1 ~Gamma (10– 3; 10– 3)
ICrb (95 %) + 0,06 ; + 1,22 + 0,08 ; + 1,45
MCMC avec Unif(– 1; 3), Médiane + 0,54 + 0,66
u ~ Normal(0 ; et – 1 ~Gamma(10– 3; 10– 3)
ICrb (95 %) – 0,16 ; + 1,22 – 0,13 ; + 1,43
MCMC avec Unif(0 ; 3,9), Médiane + 0,58 + 0,69
u ~ Normal(0 ; et – 1 ~Gamma(10– 3 ; 10– 3)
ICrb (95 %) + 0,06 ; 1,24 + 0,09 ; + 1,46
MCMC avec Unif(– 6 ; 5), Médiane + 0,53 + 0,66
u ~ Normal(0 ; et – 1~Gamma(10– 3 ; 10– 3)
ICrb (95 %) – 0,18 ; 1,20 – 0,13 ; + 1,43
MCMC avec Unif(0 ; 3), Médiane + 0,76
u ~ Normal(0 ; et – 1 ~Gamma(10– 2 ; 10– 2)
ICrb (95 %) + 0,10 ; + 1,56
MCMC avec Unif(0 ; 3), Médiane 0,66
u ~ Normal(0 ; et – 1~Gamma(10–4 ; 10– 4)
ICrb (95 %) + 0,08 ; + 1,37
* Évolution du risque par unité d’exposition. a ICo (95 %) = intervalle de confiance à 95 %. b ICr (95 %) = intervalle de crédi-bilité à 95 % (percentiles d’ordre 2,5 % et 97,5 %). c Modèle (2) : E(yi) = Ei exp(/di).
d Modèle (3) : E(yi) = Ei exp(/di + ui)(u n’intervient que pour le modèle 3).
MÉTHODES D’ANALYSE DES CLUSTERS EN ÉPIDÉMIOLOGIE GÉOGRAPHIQUE 145
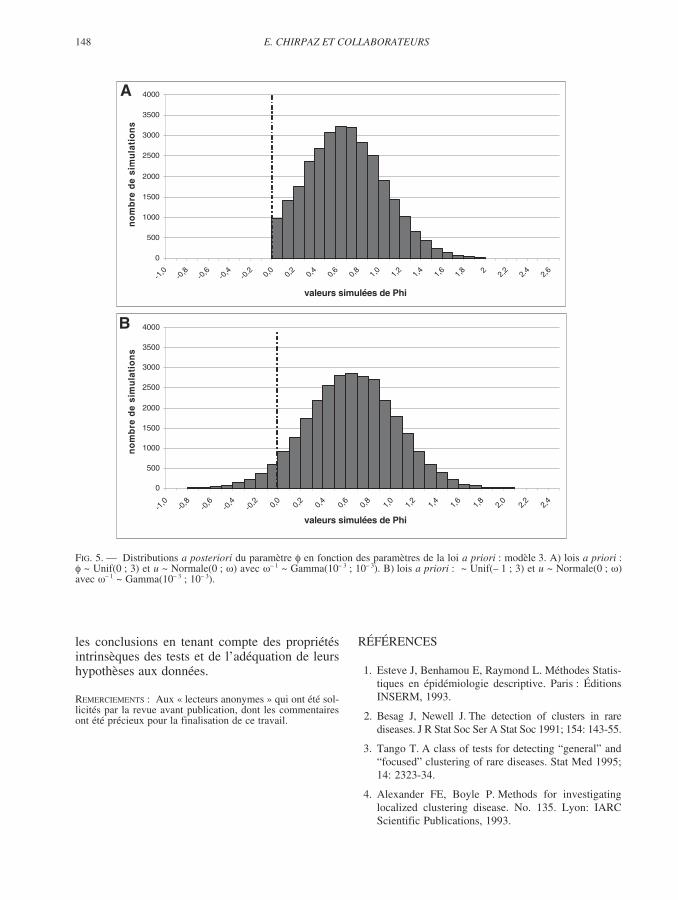
dernier (tableau I). Ainsi, avec pour loi a priorila loi Uniforme de minimum – 1 et de maximum3, les estimations du paramètre ne sont plussignificativement différentes de 0, puisque de0,54 (ICr95 % = –0,16 ; 1,22) pour le modèle (2)et de 0,66 (ICr95 % = – 0,13 ; 1,43) pour lemodèle (3). L’élargissement de l’étendue de la loia priori du paramètre s’accompagne d’un élar-gissement de l’intervalle de crédibilité de l’esti-mation de ce paramètre, qui va dans le mêmesens : ces variations sont maximales lorsque l’onfait varier la borne inférieure de la loi a priori duparamètre . Les résultats obtenus en utilisantpour la loi a priori du paramètre la loi Uniformela plus large (minimum – 6, maximum 5) sontproches de ceux obtenus avec la loi Uniformede minimum –1 et de maximum 3. Les modi-fications de la loi a priori du paramètre de sur-dispersion (modèle (3)) ont aussi un impact sen-sible, notamment sur l’estimation du paramètre (tableau I : plus la variance de la loi a priorigamma du paramètre – 1 est grande (102, 103 et104), plus l’estimation du paramètre se rappro-che de 0 : 0,76 (0,10 ; 1,56), 0,69 (0,08 ; 1,45) et0,66 (0,08 ; 1,37).
L’étude des distributions a posteriori du para-mètre montre nettement que le choix d’une loi
a priori n’autorisant pas de valeurs négativespour ce paramètre conduit à écarter des valeursde pourtant compatibles avec les observations,ces distributions a posteriori pour les modèles (2)comme (3) étant tronquées « à gauche ».
Enfin, les résultats du test du score et le test deStone ne nous permettent pas de rejeter l’hypo-thèse nulle d’absence d’agrégat de cancer de lavessie autour du point source étudié. Pour le testdu score, la statistique U (équation (5)) est égaleà 4,18 avec une variance à 7,05, soit un rapport Usur écart-type de U à 1,57, donc non significatif(p = 0,15). La zone de risque maximum détermi-née par le test de Stone est limitée à la communela plus proche du point source (centroïde à1,3 km). Cette commune a un SIR à 1,71(ICo95 % : 0,66 ; 4,00), et le niveau de significa-tion du test est de 0,09.
DISCUSSION
Au total, nous avons testé de plusieurs maniè-res l’hypothèse de l’existence d’un sur-risque decancer de la vessie autour de ce pôle industriel del’Isère : test de Stone, test du score et modélisa-tions log-linéaires (deux modélisations avec esti-mation fréquentiste des paramètres par la
TABLEAU II. — Comparaison des estimations du risque relatif (RR) de cancer de la vessie dans la commune la plus proche du point source pour les différents modèles.
Modèle Méthode d’estimation RR ICoa ou ICrb à 95 %
SIR: standardized incidence ratio 1,71 0,66 ; 4,00
Test de Stone Régression isotonique 1,71 0,66 ; 4,00
Modèle (2) c Maximum de vraisemblance 1,43 0,84 ; 2,43
Modèle (2) c MCMC avec ~ Unif(0 ; 3) 1,44 1,04 ; 2,19
Modèle (3) dMCMC avec ~ Unif(0 ; 3),
1,52 1,01 ; 2,46u ~ Normal(0 ; et 1 ~ Gamma(10–3 ; 10–3)
Modèle (2) c MCMC avec ~ Unif(– 1 ; 3) 1,42 0,89 ; 2,19
Modèle (3) dMCMC avec ~ Unif(– 1 ; 3),
1,48 0,88 ; 2,43u ~ Normal(0 ; et 1 ~ Gamma(10–3 ; 10–3)
Modèle (2) c MCMC avec ~ Unif(– 6 ; 5) 1,41 0,89 ; 2,17
Modèle (3) dMCMC avec ~ Unif(– 6 ; 5),
1,49 0,88 ; 2,44u ~ Normal(0 ; et 1 ~ Gamma(10–3 ; 10–3)
a ICo (95 %) = intervalle de confiance à 95 %. b ICr (95 %) = intervalle de crédibilité à 95 % (percentiles d’ordre 2,5 % et 97,5 %). c Modèle (2) : E(yi) = .Ei. exp( /di).
d Modèle (3) : E(yi) = .Ei. exp( /di + ui).
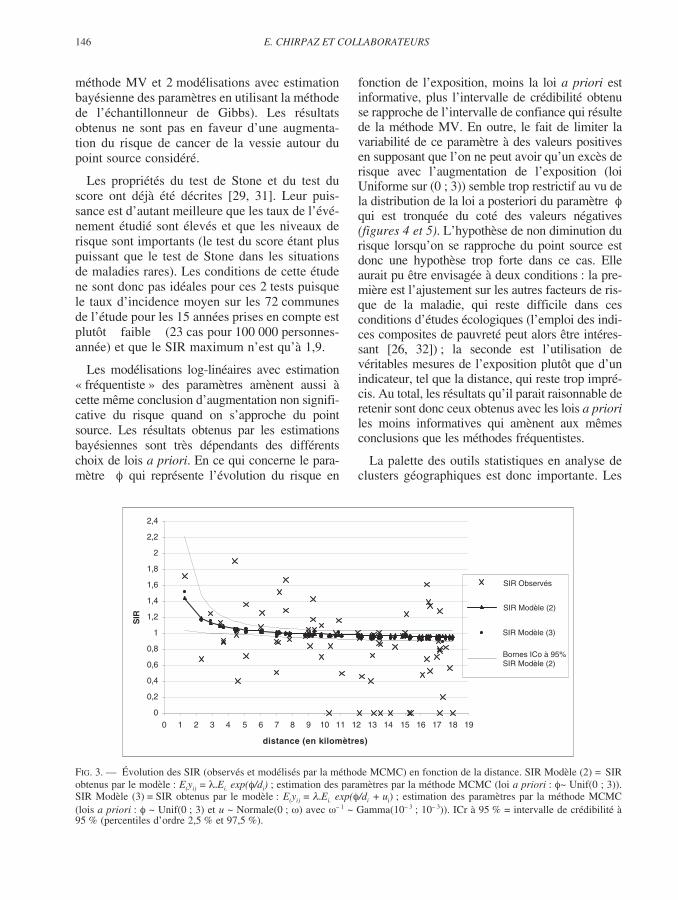
146 E. CHIRPAZ ET COLLABORATEURS
méthode MV et 2 modélisations avec estimationbayésienne des paramètres en utilisant la méthodede l’échantillonneur de Gibbs). Les résultatsobtenus ne sont pas en faveur d’une augmenta-tion du risque de cancer de la vessie autour dupoint source considéré.
Les propriétés du test de Stone et du test duscore ont déjà été décrites [29, 31]. Leur puis-sance est d’autant meilleure que les taux de l’évé-nement étudié sont élevés et que les niveaux derisque sont importants (le test du score étant pluspuissant que le test de Stone dans les situationsde maladies rares). Les conditions de cette étudene sont donc pas idéales pour ces 2 tests puisquele taux d’incidence moyen sur les 72 communesde l’étude pour les 15 années prises en compte estplutôt faible (23 cas pour 100 000 personnes-année) et que le SIR maximum n’est qu’à 1,9.
Les modélisations log-linéaires avec estimation« fréquentiste » des paramètres amènent aussi àcette même conclusion d’augmentation non signifi-cative du risque quand on s’approche du pointsource. Les résultats obtenus par les estimationsbayésiennes sont très dépendants des différentschoix de lois a priori. En ce qui concerne le para-mètre qui représente l’évolution du risque en
fonction de l’exposition, moins la loi a priori estinformative, plus l’intervalle de crédibilité obtenuse rapproche de l’intervalle de confiance qui résultede la méthode MV. En outre, le fait de limiter lavariabilité de ce paramètre à des valeurs positivesen supposant que l’on ne peut avoir qu’un excès derisque avec l’augmentation de l’exposition (loiUniforme sur (0 ; 3)) semble trop restrictif au vu dela distribution de la loi a posteriori du paramètrequi est tronquée du coté des valeurs négatives(figures 4 et 5). L’hypothèse de non diminution durisque lorsqu’on se rapproche du point source estdonc une hypothèse trop forte dans ce cas. Elleaurait pu être envisagée à deux conditions : la pre-mière est l’ajustement sur les autres facteurs de ris-que de la maladie, qui reste difficile dans cesconditions d’études écologiques (l’emploi des indi-ces composites de pauvreté peut alors être intéres-sant [26, 32]) ; la seconde est l’utilisation devéritables mesures de l’exposition plutôt que d’unindicateur, tel que la distance, qui reste trop impré-cis. Au total, les résultats qu’il parait raisonnable deretenir sont donc ceux obtenus avec les lois a prioriles moins informatives qui amènent aux mêmesconclusions que les méthodes fréquentistes.
La palette des outils statistiques en analyse declusters géographiques est donc importante. Les
FIG. 3. — Évolution des SIR (observés et modélisés par la méthode MCMC) en fonction de la distance. SIR Modèle (2) = SIRobtenus par le modèle : E(yi) = Ei. exp( /di) ; estimation des paramètres par la méthode MCMC (loi a priori : ~ Unif(0 ; 3)).SIR Modèle (3) = SIR obtenus par le modèle : E(yi) = Ei. exp( /di + ui) ; estimation des paramètres par la méthode MCMC(lois a priori : ~ Unif(0 ; 3) et u ~ Normale(0 ; ) avec – 1 ~ Gamma(10– 3 ; 10– 3)). ICr à 95 % = intervalle de crédibilité à95 % (percentiles d’ordre 2,5 % et 97,5 %).
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1,6
1,8
2
2,2
2,4
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
SIR
distance (en kilomètres)
SIR Observés
SIR Modèle (2)
SIR Modèle (3)
Bornes ICo à 95% SIR Modèle (2)
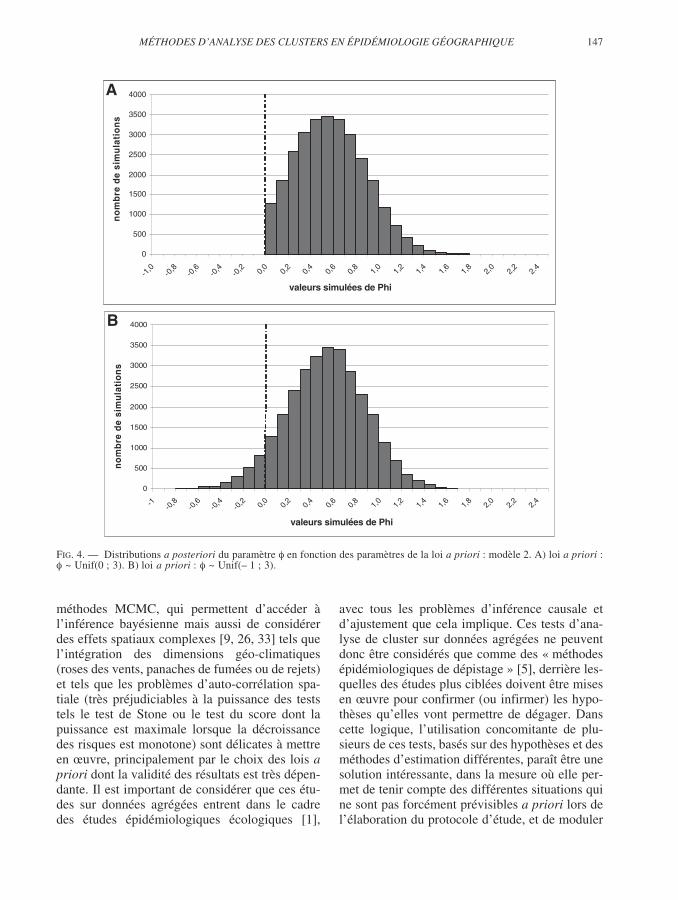
MÉTHODES D’ANALYSE DES CLUSTERS EN ÉPIDÉMIOLOGIE GÉOGRAPHIQUE 147
méthodes MCMC, qui permettent d’accéder àl’inférence bayésienne mais aussi de considérerdes effets spatiaux complexes [9, 26, 33] tels quel’intégration des dimensions géo-climatiques(roses des vents, panaches de fumées ou de rejets)et tels que les problèmes d’auto-corrélation spa-tiale (très préjudiciables à la puissance des teststels le test de Stone ou le test du score dont lapuissance est maximale lorsque la décroissancedes risques est monotone) sont délicates à mettreen œuvre, principalement par le choix des lois apriori dont la validité des résultats est très dépen-dante. Il est important de considérer que ces étu-des sur données agrégées entrent dans le cadredes études épidémiologiques écologiques [1],
avec tous les problèmes d’inférence causale etd’ajustement que cela implique. Ces tests d’ana-lyse de cluster sur données agrégées ne peuventdonc être considérés que comme des « méthodesépidémiologiques de dépistage » [5], derrière les-quelles des études plus ciblées doivent être misesen œuvre pour confirmer (ou infirmer) les hypo-thèses qu’elles vont permettre de dégager. Danscette logique, l’utilisation concomitante de plu-sieurs de ces tests, basés sur des hypothèses et desméthodes d’estimation différentes, paraît être unesolution intéressante, dans la mesure où elle per-met de tenir compte des différentes situations quine sont pas forcément prévisibles a priori lors del’élaboration du protocole d’étude, et de moduler
FIG. 4. — Distributions a posteriori du paramètre en fonction des paramètres de la loi a priori : modèle 2. A) loi a priori :~ Unif(0 ; 3). B) loi a priori : ~ Unif(– 1 ; 3).
0
500
1000
1500
2000
2500
3000
3500
4000
-1,0
-0,8
-0,6
-0,4
-0,2 0,
00,
20,
40,
60,
81,
01,
21,4
1,6
1,8
2,0
2,2
2.4
valeurs simulées de Phi
no
mb
re d
e si
mu
lati
on
s
0
500
1000
1500
2000
2500
3000
3500
4000
-1,0
-0,8
-0,6
-0,4
-0,2 0,
00,
20,
40,
60,
81,
01,
21,4
1,6
1,8
2,0
2,2
2.4
valeurs simulées de Phi
no
mb
re d
e si
mu
lati
on
s
A
0
500
1000
1500
2000
2500
3000
3500
4000
-1 -0,8
-0,6
-0,4
-0,2 0,0 0,2 0,4 0,6 0,8 1,0 1,2 1,4 1,6 1,8 2,0 2,2 2,4
no
mb
re d
e si
mu
lati
on
s
valeurs simulées de Phi
B
148 E. CHIRPAZ ET COLLABORATEURS
les conclusions en tenant compte des propriétésintrinsèques des tests et de l’adéquation de leurshypothèses aux données.
REMERCIEMENTS : Aux « lecteurs anonymes » qui ont été sol-licités par la revue avant publication, dont les commentairesont été précieux pour la finalisation de ce travail.
RÉFÉRENCES
1. Esteve J, Benhamou E, Raymond L. Méthodes Statis-tiques en épidémiologie descriptive. Paris : ÉditionsINSERM, 1993.
2. Besag J, Newell J. The detection of clusters in rarediseases. J R Stat Soc Ser A Stat Soc 1991; 154: 143-55.
3. Tango T. A class of tests for detecting “general” and“focused” clustering of rare diseases. Stat Med 1995;14: 2323-34.
4. Alexander FE, Boyle P. Methods for investigatinglocalized clustering disease. No. 135. Lyon: IARCScientific Publications, 1993.
FIG. 5. — Distributions a posteriori du paramètre en fonction des paramètres de la loi a priori : modèle 3. A) lois a priori :~ Unif(0 ; 3) et u ~ Normale(0 ; ) avec – 1 ~ Gamma(10– 3 ; 10– 3). B) lois a priori : ~ Unif(– 1 ; 3) et u ~ Normale(0 ; )
avec – 1 ~ Gamma(10– 3 ; 10– 3).
0
500
1000
1500
2000
2500
3000
3500
4000
-1,0
-0,8
-0,6
-0,4
-0.2 0,0 0,2 0,4 0,6 0,8 1,0 1,2 1,4 1,6 1,8 2 2,2 2.4 2,6
valeurs simulées de Phi
no
mb
re d
e si
mu
lati
on
s
A
0
500
1000
1500
2000
2500
3000
3500
4000
-1,0
-0,8
-0,6
-0,4
-0,2 0,0
0,2
0,4
0,6
0,8
1,0
1,2
1,4
1,6
1,8
2,0
2,2
2,4
valeurs simulées de Phi
no
mb
re d
e si
mu
lati
on
s
B

MÉTHODES D’ANALYSE DES CLUSTERS EN ÉPIDÉMIOLOGIE GÉOGRAPHIQUE 149
5. Waller LA, Jacquez GM. Disease models implicit instatistical tests of disease clustering. Epidemiology1995; 6: 584-90.
6. Breslow NE. Extra-Poisson variation in log-linearModels. Appl Stat 1984; 33: 38-44.
7. Colonna M. Estimations bayésiennes empiriquesde risques relatifs : principes et exemples d’appli-cation. Rev Epidemiol Sante Publique 1997 ; 45 :142-9.
8. Bernardinelli L, Clayton D, Montomoli C. Bayesianestimates of disease maps: how important are priors.Stat Med 1995; 14: 2411-31.
9. Lawson AB, Biggeri A, Bohning D, Lesafre E, VielJF, Bertollini R. Disease mapping and risk assessmentfor public health. Chichester (England): John Wiley &Sons, 1999.
10. Stone RA. Investigations of excess environmentalrisks around putative sources: statistical problems anda proposed test. Stat Med 1988; 7: 649-60.
11. Lawson AB. On the analysis of mortality events asso-ciated with a prespecified fixed point. J R Stat Soc SerA Stat Soc 1993; 156: 363-77.
12. Waller LA, Turnbull BW, Clark LC, Nasca P. Chro-nic disease surveillance and testing of clustering ofdisease and exposure: application to leukaemia inci-dence and TCE-contaminated dumpsites in upstateNew York. Environmetrics 1992; 3: 281-300.
13. Parkin DM, Muir CS, Whelan SL, Gao YT, Ferlay J,Powell J. Cancer incidence in five continents. VolVII. Lyon: International Agency for Research on Can-cer, 1997.
14. Menegoz F, Chérié-Challine L. Le cancer en France :incidence et mortalité. Paris : La DocumentationFrançaise, 1998.
15. Boffetta P, Jourenkova N, Gustavsson P. Cancer Riskfrom occupational and environmental exposure topolycyclic aromatic hydrocarbons. Cancer CausesControl 1997; 8: 444-72.
16. Vineis P, Pirastu R. Aromatic amines and cancer.Cancer Causes Control 1997; 8: 365-55.
17. Hill C, Doyon F, Sancho-Garnier H. Épidémiologiedes Cancers. Paris: Médecine Sciences / Flammarion,1997.
18. Lauwerys RR. Toxicologie industrielle et intoxica-tions professionnelles. 4th ed. Paris : Masson, 1999.
19. Sans S, Elliot P, Kleinschmidt I, et al. Cancer inci-dence and mortality near the Baglan Bay petrochemi-
cal works, South Wales. Occup Environ Med 1995;52: 217-24.
20. Michelozzi P, Fusco D, Forastiere F, Ancona C,Dell’Orco V, Perucci A. Small area study on morta-lity among people near living multiple sources air pol-lution. Occup Environ Med 1998; 55: 611-5.
21. Lawson AB, Waller LA. A review of point patternmethods for spatial modelling of events around sour-ces of pollution. Environmetrics 1996; 7: 471-87.
22. Benhamou E, Laplanche A. Estimation de la popula-tion à risque entre deux recensements pour le calculd’un taux d’incidence ou de mortalité par cancer :comparaison de 4 méthodes. Rev Epidemiol SantePublique 1991 ; 39 : 71-7.
23. Viel JF. La regression de Poisson en épidémiologie.Rev Epidemiol Sante Publique 1994 ; 42 : 79-87.
24. Intercooled STATA 7.0, STATA Corporation, 702University Drive East, College Station TX 77840USA.
25. Gurrin LC, Kurinczuk JJ, Burton PR. Bayesian statis-tics in medical research: an intuitive alternative toconventional data analysis. J Eval Clin Pract 2000; 6:193-204.
26. Wakefield JC, Morris SE. The Bayesian modeling ofdisease risk in relation to a point source. J Am StatAssoc 2001; 96: 77-91.
27. WINBUGS 1.2, http://www.mrc-bsu.cam.ac.uk/bugs/winbugs.
28. Droesbeke JJ, Fine J, Saporta G. Méthodes bayésien-nes en statistique. Paris : Éditions TECHNIP, 2002.
29. Bithell JF. The choice of test for detecting raiseddisease risk near a point source. Stat Med 1995; 14:2309-22.
30. Morton-Jones T, Diggle P, Elliott P. Investigation ofexcess environmental risk around putative sources:Stone’s test with covariate adjustment. Stat Med1999; 18: 189-97.
31. Waller L, Lawson AB. Power of focused tests todetect disease clustering. Stat Med 1995; 14: 2291-308.
32. Challier B, Viel JF. Pertinence et validité d’un nouvelindice composite français mesurant la pauvreté auniveau géographique. Rev Epidemiol Sante Publique2001 ; 49 : 41-50.
33. Lawson AB. MCMC methods for putative pollutionsource problems in environmental epidemiology. StatMed 1995; 14: 2473-85.





























