Embed Size (px)
Citation preview

PRISE EN COMPTE
DES DONNEES MANQUANTES DANS
L'ANALYSE D'UNE ETUDE DE
COHORTE :
CAS DU PROJET DARVIRPar :
KOUAMO Olaf
Maitre és-Sciences Mathématiques
Sous la direction de
Henri Gwet
Professeur
de
Jean-Christophe THALABARD
Professeur
et de
Christian Laurent
HDR

Dédicaces
A mes Parents,
Mme KOUAMO née NCHAPMOU MEPPA Rosalie et Mr KOUAMO PierreMaman, PapaVous m'avez appris le sens de la famille et des amis.Vous m'avez appris le sens du travail et de la persévérance.Vous m'avez appris que la vie n'appartient qu'à ceux qui se battent.Vous m'avez toujours donné les conditions d'études dans la limite de vos moyens et uncadre familiale favorable.Merci maman, merci papa pour tout, voyez en ce mémoire un des fruits de tous leseorts et sacrices que vous ne cessez de faire pour nous.
A ma soeur et son époux,
Mme DJANANG née KOUAMO Germaine et Mr DJANANG Jules
A tous mes petits frères,
Mr KOUAMONGONGANG Stéphane, Mr KOUAMONCHAPMOUCédric, Mr KOUAMOHermann, Mr KOUAMO Ebénezer Owens et Mr KOUAMO KAMENI Hervé
A mes 2 neveux,
DJANANG Francesca et DJANANG NathanCe travail est aussi le fruit de vos eorts consentis. Par dessus tout, nous devons
toujours rester unis comme nous le sommes aujourd'hui.
A ma petite amie,
Mlle TCHOUANGUEM Fany EstherPour ton soutien et ta compréhension.
Sans oublier mes grand-mères sans lesquelles je ne suis rien.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Remerciements
Au Professeur Henri Gwet
Pour avoir su raermir ma passion pour la recherche en Statistique, pour l'intérêt qu'ilporte à mes travaux, pour avoir toujours été disponible, d'oreille attentive et de conseilspointus pendant tout mon travail.
Au Docteur Christian Laurent
Pour son sérieux et sa disponibilité dans le travail.
Au Professeur J.C THALABARD
Pour son aide précieuse dans ces travaux et ses enseignements sans lesquels ces travauxn'auraient pas pu être réalisés.
A tous le personnel du site ANRS de yaoundé.
Pour l'acceuil chaleureux qu'ils m'ont reservé pendant mon court séjour dans leur site.Je pense principalement au Professeur Shiro KOULLA qui m'a attribué une autorisationde travailler chez eux.
A tous le corps enseignant du Master.
Pour tous les enseignements reçus Je pense principalement au Docteur Eugène PatriceNDONG NGUEMA pour tous ses enseignements et ses précieux conseils pendant mestravaux.
A tous mes camarades du Master.
Avec qui tout au long de l'année on a eu à travailler dur pour arriver à nos ns
A mes parents
Pour le soutien sans faille et la patience qu'ils ont su me montrer.
A tous les responsables du projet DARVIR qui ont accepté que nous
utilisions les données de leur étude pour réaliser ce travail.
Je remercie toutes les personnes dont j'aurai oublié le nom et qui auraient
contribué d'une manière ou d'une autre à la réalisation de ce travail.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Resumé
L'imputation des données manquantes est généralement utilisée pour la correctionde la non réponse partielle apparaissant dans une enquête ou une étude. La techniquede l'imputation multiple proposée par Rubin (1987), plutôt qu'une imputation simple, aété utilisée an de mettre en exergue toute la variabilité due aux données manquantes.Nous présentons d'abord quelques aspects théoriques du problème de l'imputation et dela méthode de l'imputation multiple. Ensuite nous illustrons cette dernière sur plusieursexemples tirés du projet étudié et, pour terminer, nous faisons une brève étude de survieen vue de déceler les covariables qui inuent sur la probabilité de continuer le traitement.
Mots clés
Non-réponse partielle, imputation, imputation multiple, estimation par maximum devraisemblance, courbe de Kaplan-Meier, test du log-rank.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Abstract
Multiple imputation provides a useful strategy for dealing with data sets with missingvalues. Instead of lling in a single value for each missing value, Rubin's (1987) multipleimputation procedure replaces each missing value with a set of plausible values thatrepresent the uncertainty about the right value to impute. At rst, we present sometheorical aspects of multiple imputation ; after, we illustrate thse aspecsts on severalexamples taken out from the project studied. To end, we realise a survival analysisto reveal the covariables which have an inuence on the probability of continuing theanti-retroviral treatment.
Keys words
partial non-response, imputation, multiple imputation, maximum likehood estimation.estimator, Kaplan-Meier curve, log-rank test.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Résumé exécutif
0.1 Problème
Face à l'expansion de l'infection par le VIH et grâce aux recommandations de l'OMSà travers l'initiative 3 en 5 (3 millions de personne vivant avec le virus du sida d'ici2005), le personnel de santé de la ville de Douala à mis sur pied un projet en vuede juger de l'ecacité du traitement antirétroviral dans cette ville. Au bout de 3 ans,des analyses ont été réalisées et des résultats publiés. Cependant, compte tenu du coûtélevé des médicaments antirétroviraux, du coût des tests pré thérapeutiques, du coût desexamens biologiques, du manque de médecins et même de la distance qui sépare le lieu derésidence de certains patients du centre de santé, l'on a enregistré beaucoup de donnéesmanquantes. Le problème qui se pose ici est celui de savoir si les données réellementobservées sont représentatives du tableau de données initial. En d'autres termes, est-ceque les résultats obtenus sur les patients pour lesquels on a des valeurs peuvent êtreextrapolés à l'ensemble de tous les patients ? Pour ce faire, nous avons utilisé quelquestechniques d'imputations multiples en vue de remplacer les valeurs manquantes pardes valeurs prédites ou simulées, réaliser les inférences et dire si les valeurs obtenuesaprès imputation sont signicativement diérentes de celles observées sur les donnéesbrutes. Pour terminer, il a été question pour nous de comparer nos diérentes techniquesd'imputations en vue de déceler celle qui est la plus appropriée aux jeux de données issusdu projet "DARVIR".
0.2 Méthodologie
Pour réaliser le travail ci-dessus présenté, nous avons utilisé 5 méthodes d'imputa-tions.
La méthode de régression multiple : elle consiste à remplacer chaque valeur man-quante par plusieurs valeurs prédites plus un résidu aléatoire.
La méthode de propensity score : elle est adaptée tant pour les variables quanti-tatives que pour les variables qualitatives.
La méthode k-nn : elle consiste à remplacer chaque valeur manquante par lamoyenne des valeurs observées chez ses k plus proches voisins.
La méthode de transformation : elle approche le mieux des variables continuesvers une loi gaussienne. Elle consiste simplement à simuler un échantillon de taille
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

6
celle des données manquantes suivant la loi normale de moyenne celle des valeursréellement observées et de variance celle des valeurs réellement observées.
La méthode MCMC : est une procédure itérative de tirages pseudo aléatoires. Le remplacement de chaque valeur manquante par la moyenne des valeurs réelle-ment observées.
0.3 Résultats
1. Cas des variables qualitatives.Dans le cas des variables qualitatives, une seule des méthodes d'imputations dé-crites précédemment est appropriée. Pour les variables abandon et deces, on obtientdes valeurs signicativement diérentes de celles obtenues sur les données brutes.Ainsi pour les proportions des patients décédés et ayant abandonnés l'étude, onobtient les résultats suivants : Par contre pour la variable stadeCDC, on obtient
données brutes données imputéesabandon 3% 6%décès 6.6% 12%
ICabandon [2.1 ; 4] [4.3 ; 7.65]ICdeces [5.1 ; 8] [9.7 ; 14.1]
des valeurs qui ne sont pas signicativement diérentes de celles obtenues sur lesdonnées brutes.
2. Cas des variables quantitatives.Pour les variables comme le poids et l′age, il n'existe aucune diérence signicativeentre les résultats obtenus par l'une ou l'autre des techniques d'imputation. Demême il n'existe pas de diérence signicative entre ces résultats et ceux obtenussur les données brutes. Par contre, pour les variables cd4 et cv, il existe une dié-rence. Cependant, le fort taux de données manquantes principalement dans ces 2variables ne nous permet pas de nous prononcer sur l'ecacité de nos techniquesd'imputation.
A près comparaison des diérentes méthodes d'imputation, on constate que surnos données, l'imputation par la moyenne se distingue des autres par la qualité desimputations ; cependant, cette ecacité devient mitigée lorsque le taux de donnéesmanquantes s'élève. Aucune autre technique ne se distingue signicativement desautres par la qualité des imputations.
0.4 Conclusions et Recommandations
Le but de notre analyse était d'utiliser quelques techniques d'imputation an degérer la non réponse partielle apparaissant dans le cadre du projet DARVIR. Pour cefaire, nous avons utilisé 4 méthodes d'imputations multiples. Ces méthodes présentent
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

1
les avantages d'être adaptées aux cas de données manquantes de type MAR (missing atrandom)
(à l'exception du remplacement par la moyenne qui lui est plus ecace lorsque
les données manquantes sont NMAR(non missing at random)). Toutes ces méthodes ont
été comparées sur notre jeu de données mais aucune ne se distingue signicativement desautres par la qualité des résultats. L'un des avantages de la procédure MI ANALYSE deSAS est qu'elle est rapide, simple d'utilisation et qu'elle ne diminue pas articiellementla variance. On peut cependant lui reprocher d'agir comme une "boite noire" à partirdes modèles probabilistes basés sur les méthodes de MONTE CARLO et les chaînesde markov. La méthode de propensity score elle est adaptée tant pour les variablesquantitatives que pour les variables qualitatives et à pour avantage de préserver lesaspects importants des distributions ; cependant une imputation par cette méthode peutfausser les corrélations avec d'autres variables ; en outre, la structure monotone qui soutend les conditions d'application de cette méthode n'est pas vériée. Un des très grandproblème de notre tableau de données est le fait que les données manquantes représententla plupart du temps plus de 50% des données. Sur cette base, il est très dicile de trouverdes méthodes d'imputation ecaces. Alors les autorités de santé locales dans le cadre dela lutte contre le sida devraient mettre tout en oeuvre pour éviter à l'avenir d'avoir dansdes suivis médicaux quotidiens tant de données manquantes. Ceci passe, par exemple,par :
La réduction du coût des examens biologiques, du coût des tests pré thérapeutiqueset même du coût des médicaments antirétroviraux.
Une plus grande implication de tout le personnel de santé (les médecins n'étantpas toujours disponibles, les inrmiers (es) peuvent prendre la relève lorsque cesderniers sont absents).
Enn, la diversication des pôles d'acquisition des ARV et également des centresde santés.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Introduction
Contexte
Face à l'expansion de l'infection par le V.I.H (Virus immuno décitaire humain),les autorités de santé camerounaises, avec l'appui technique et nancier des partenairesinternationaux (OMS : Organisation Mondiale de la Santé, ANRS : Agence Nationale deRecherche sur le sida, ONU-SIDA : Organisation des Nations Unies pour la lutte contrele sida), ont mis sur pied des techniques pour réduire l'expansion du V.I.H. Il existedeux types de VIH : le VIH1 et le VIH2. Le VIH-1 et le VIH-2 sont 2 VIH distincts(génétiquement diérents) qui produisent globalement les mêmes eets. Il y a toutefoisquelques implications diérentes :
a- La transmission du VIH-2 est plus faible que celle du VIH-1.b- La progression clinique des infections par le VIH-2 est plus lente que celle desinfections par le VIH-1.
c- Les souches de VIH-2 sont fréquemment naturellement résistantes à certains ARV1
(inhibiteurs non nucléosidiques de la reverse transcriptase). Ceux-ci sont doncinecaces et ne doivent donc pas être employés.
Parfois, des patients sont infectés par les 2 virus (VIH-1 -2). Cependant, le plus répanduau Cameroun est le VIH1. Depuis l'apparition de cette maladie en 1982, plusieurs actionsont été menées pour lutter contre le virus du sida ; ce n'est qu'en 1987 qu'a été découvertle 1er traitement anti-rétroviral nommé AZT (retrovir, zidovudine) qui s'est avéré trèsecace dans le regain des cd4 et la chute de la charge virale. Néanmoins, il présentaitquelques limites ; car le patient devait avoir 6 prises de comprimés par jour, ce quientraîne parfois l'oubli. Ce traitement a été amélioré et a conduit aux trithérapies en1996 ; plus ecaces, mais malheureusement trop coûteuses pour les patients les plusdéfavorisés, particulièrement en Afrique.
Problématique
La charge virale plasmatique et le taux de lymphocytes Tcd4 constituent les deuxprincipaux critères de l'évaluation de l'ecacité d'un traitement anti-rétroviral. La pro-portion des patients ayant une charge virale inférieure à un seuil est notamment classi-quement comparée dans un essai thérapeutique randomisé selon une analyse en intentionde traiter. Dans ce type d'analyse, tous les patients sont pris en compte, même s'ils ont
1désigne antirétro-viraux
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

3
arrêté ou changé de traitement. En outre, il est souvent recommandé de considérer lesdonnées manquantes comme des échecs. Cette attitude très conservatrice ne pose pas deproblèmes majeurs dans les essais cliniques où les données manquantes sont rares à lafaveur d'un suivi intensif des patients et d'une prise en charge nancière de ces derniers.En revanche, les données manquantes sont beaucoup plus fréquentes dans la pratiquemédicale quotidienne, en particulier lorsque les examens médicaux sont aux frais des pa-tients, comme c'est le cas le plus souvent en Afrique. Considérer les données manquantescomme des échecs devient alors très problématique. A l'inverse, la prise en compte dansl'analyse uniquement des valeurs observées expose à d'autres risques de biais ; en eetles patients qui réalisent les examens biologiques ne sont pas représentatifs de l'ensembledes patients. L'objet de la présente recherche est la correction de la non réponse partielleapparaissant dans le cadre du projet "DARVIR : Douala anti-rétroviral". On parle denon réponse partielle lorsque l'enquêté n'a pas répondu à l'une où l'autre question del'enquête et, dans le cadre de notre étude, lorsqu'il n'a pas honoré de sa présence unevisite médicale ou un examen biologique.
La présence de données manquantes est un problème important qu'il faut gérer avecprécaution an d'éviter de détériorer les performances des procédures de DATA MI-NING. Il existe trois principales stratégies de gestion de données manquantes :
La 1ere consiste à éliminer les observations incomplètes. Elle présente deux li-mites importantes. Tout d'abord, la perte d'information ainsi obtenue peut êtreconsidérable si de nombreuses variables ont des valeurs manquantes sur diérentsindividus. Ensuite, cette méthode risque d'introduire un biais si le processus n'estpas complètement aléatoire, c'est-à-dire si le sous-échantillon analysé n'est pasreprésentatif de l'échantillon global
La 2eme consiste à utiliser les techniques de "repondération". Cette méthode consistesimplement à augmenter le poids d'échantillonnage des répondants pour tenircompte des non-répondants. Cette technique est principalement utilisée pour com-penser la non réponse totale.
La troisième stratégie est l'imputation. Cette dernière technique nous permet d'ob-tenir des séries de données complètes en imputant des valeurs aux données man-quantes ; ce qui est protable à plus d'un titre dans de nombreuses analyses. Ce-pendant, il existe un prix à payer : les techniques d'estimation et d'analyse doiventêtre appropriées pour exploiter les nouvelles données.
Enjeu
Une telle étude est importante en ce sens qu'elle permet de prendre en comptedans l'analyse les valeurs non observées et d'éviter ainsi le risque d'introduire un biaissystématique dans cette analyse. En eet, pour les mesures de charge virale par exemple,considérer les données manquantes comme des échecs revient à dire que tous les patientsqui n'ont pas de mesures de charges virales sont en échec thérapeutique, c'est-à-dire ontune charge virale supérieure au seuil déni. Ce type d'analyse a tendance à sous-estimerl'ecacité du traitement car, par exemple, supposons qu'on mène une étude sur 200patients parmi lesquels 70 ont des charges virales < au seuil déni, 30 ont des chargesvirales > au seuil déni, et on a 100 données manquantes. Si on ne prend en compte
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

4
dans l'analyse que les données totalement observées on dira que 70% des patients sonten réussite thérapeutique ; par contre, si on considère les données manquantes commedes échecs, alors rien que 35% des patients sont en réussite thérapeutique et on pourraitêtre tenté d'abandonner le traitement, sous prétexte qu'il n'est pas ecace alors que cen'est pas forcément le cas. D'un autre coté, dire que le traitement est ecace à 70%expose également à d'autres risques de biais. D'où l'importance de créer des méthodesappropriées pour gérer cette non réponse.
Statistique et Informatique
La science a tellement évolué qu'il est impossible de nos jours de parler de statis-tique sans parler d'informatique. En eet l'ordinateur est devenu l'outil privilégié dustatisticien en ce sens que nis les longs calculs numériques à la main, nie l'utilisa-tion rudimentaire des tables d'abaques pour la génération des nombres aléatoires. Denos jours, grâce à l'évolution de l'informatique, tous ces calculs sont devenus simples.C'est la raison pour laquelle pour nos analyses statistiques, nous utiliserons le logicielR qui est gratuit et téléchargeable sur le site http ://lib.stat.cmu.edu/R/CRAN/ aussibien pour faire des simulations (bootstrap, reéchantillonnage) que pour faire des cal-culs numériques et les graphiques. En plus de R, nous utiliserons le logiciel SAS version8.1 uniquement pour appliquer la méthode MCMC pour imputation multiple qui y estimplémentée.
Plan du travail
Les principaux objectifs et les méthodes pour les atteindre étant dénis, nous divisonsnotre travail en deux parties.
La première partie est principalement faite de rappels statistiques que nous jugeonsindispensables pour la réalisation des objectifs xés. Ainsi, au chapitre 1, nous parlons defaçon sommaire des tests statistiques nécessaires pour réaliser l'étude et nous consacronsla seconde section au bootstrap. Au chapitre 2, nous présentons quelques méthodesstatistiques de gestion de données manquantes
La seconde partie est consacrée aux applications de ces diérentes méthodes sur le jeude données du projet "DARVIR". Au chapitre 3, nous faisons une étude descriptive desdonnées réellement observées. Au chapitre 4, nous appliquons les diérentes techniquesd'imputation décrites plus haut et comparons les résultats issus de ces méthodes an dedéceler celle qui est la plus appropriée à nos données. Pour terminer, nous faisons uneétude de survie sur les données réellement observées.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Chapitre Premier
Fondements statistiques pour la
gestion des données manquantes
1.1 Exemples de tests statistiques
Dans cete section, nous dénissons les tests statistiques qui seront utilisés dans lasuite. C'est ainsi que nous présentons la théorie du test de Wald et du rapport de vrai-semblance qui seront utilisés pour rejeter ou non l'hypothèse de nullité des coecientset d'égalité des fonctions de risque instantané dans le cadre de l'analyse de survie etcelle du test de Shapiro-Wilk qui lui sera nécessaire pour tester la normalité de chaquevariable quantitative de nos diérents échantillons.
1.1.1 Test de Wald et du rapport de vraisemblance
1. Test de Wald [1]On considère le test :
Test :
H0 : βj = αH1 : βj 6= α,
(1.1)
où βj désigne la jieme composante du vecteur de paramètres β = (β1, . . . , βk)T ∈ Rk
d'un modèle dichotomique. L'idée du test de Wald est d'accepter l'hypothèse nullesi l'estimateur βj de βj est proche de α. La statistique de test est une mesure bienchoisie de la proximité de βj−α à 0 (on peut dénir une statistique de test pour unparamètre θ comme une fonction Π des observations (x1, . . . , xn) et du paramètreθ dont la loi L ne dépend pas du paramètre).On sait que dans la formulation générale d'un test de type H0 : g(β) = r, où r estun vecteur de dimension (c, 1), on a le résultat suivant.[
g(β)− r]T [
GV (β)GT][
g(β)− r] L→
n→+∞χ2(c),
où β désigne l'estimateur du maximum de vraisemblance de β, G = ∂g(.)/∂βT , etV (β) l'estimateur de la matrice de variances covariances des coecients. Dans lecas qui nous intéresse, on a g(β) = βj et r = α. Le vecteur G, de dimension (k, 1),comporte (k − 1) zéros et 1 à la jieme position. On obtient le résultat suivant.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Fondements statistiques pour la gestion des données manquantes 6
Dénition 1.1.1. La statistique du test de Wald associée au test unidirectionnel
Test :
H0 : βj = αH1 : βj 6= α,
(1.2)
suit la loi suivante sous H0 :
[βj − α
]T(vjj)
−1[βj − α
]=
(βj − α
)2vjj
L→n→+∞
χ2(1),
où vjj désigne l'estimateur de la variance de l'estimateur du jieme coecient βj.Ainsi, si l'on note χ2
95%(1) le quantile à 95% de la loi du χ2(1), le test de Wald
au seuil de 5% de l'hypothèse H0 consiste à accepter H0 si
(βj−α
)2
vjj< χ2
95%(1) et à
refuser cette hypothèse si cette quantité est supérieure à χ295%(1).
Le logiciel R ne propose pas cette statistique de Wald mais une statistique Zj déniecomme la racine carrée de la précédente. Compte tenu du lien entre la loi normalecentrée et la loi du χ2(1), on a immédiatement sous H0 :
Zj =βj − α√
vjj
L→n→+∞
N(0; 1),
et en particulier pour un test de nullité H0 : βj = 0, on retrouve
Zj =βj√vjj
L→n→+∞
N(0; 1).
2. Test du rapport de vraisemblance [1] :Dans ce cas, on compare les vraisemblances Ln(θn) et Ln(θ0
n) où θ0n est l'EMV de
θn. Sous H0, Posons : Λn =
Ln(θ0n)
Ln(θn)etξRn = −2logΛn.
(1.3)
Par un developpement limité à l'ordre 2, sous H0, il vient que
ξRn = n
(θn − θ0
n
)t(I1(θ)
0)(
θn − θ0n
)+ op(1) ;
il vient que :
ξRn →
n→+∞χ2(q)
d'où la région critique :
W =
ξRn > χ2
1−α(q)
.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Fondements statistiques pour la gestion des données manquantes 7
1.1.2 Test de Shapiro-Wilk
Soit (x1, . . . , xn) un échantillon iid 1, qu'on ordonne de façon croissante :
(x(1) ≤ x(2) ≤ . . . ≤ x(n)).
Si X suit une loi normale N(m, σ2), on en déduit un échantillon (y1, . . . , yn) ordonné
extrait de N(0, 1), avec yi =xi −m
σ.
Dénition 1.1.2. On appelle scores normaux les quantités an(i) = E(X(i)), où X(i) estla iieme observation ordonnée d'un échatillon de taille n extrait de N(0, 1) :
X(1) ≤ . . . ≤ X(i−1) ≤ X(i) ≤ X(i+1) ≤ . . . ≤ X(n).
Les an(i) sont données dans la table des scores voir ([2], page 320).
L'idée du test de Shapiro-Wilk consiste à comparer deux statistiques T1 et T2 qui,sous l'hypothèse de normalité N(m; σ) estiment toutes deux σ2, et sous l'alternative,estiment des quantités diérentes.Shapiro et Wilk considèrent les statistiques de tests [2]
T1 = (n− 1)S2
T2 =( n/2∑
i=1
an(i)(x(n−i+1) − x(i)))2
,(1.4)
où les an(i) sont les scores normaux, les x(i) les observations ordonnées de façon croissante
et S2 =1
n− 1
n∑i=1
(xi − x)2 est la variance empirique de l'échantillon. La statistique de
test est :
SW =T2
T1
.
Des simulations ont montré que E(SW ) était plus petit dans le cas non normal que lecas normal et V (SW ) plus grand en non normal qu'en normal La région critique est :
W = SW < a telle que PH0(W ) = α.
Le seuil a est lu dans la table de la loi normale donnée par [2], a est fonction de n et deα.
1.2 Le bootstrap
L'objectif de cette méthode introduite par Efron [3] est d'approcher par simulation(Monte Carlo) la distribution d'un estimateur lorsqu'on ne connaît pas la loi de l'échan-tillon.
Les hypothèses probabilistes pas toujours vériées ou invériables sont remplacéespar des simulations et donc beaucoup de calculs, mais en utilisant la puissance de l'or-dinateur.
1indépendant et identiquement distribué
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Fondements statistiques pour la gestion des données manquantes 8
1.2.1 Le principe
Soit x = x1, . . . , xn, un échantillon de taille n ∈ N issu d'une loi inconnue F sur(Ω, C).
On appelle loi empirique F de l'échantillon la loi discrète qui aecte le poids1
nà
chacune de ses n observations xi :
F =1
n
n∑i=1
δxi.
Si A ∈ C, PF (A) est alors estimée par :
PF (A) =1
ncardxi, xi ∈ A.
Dénition 1.2.1. On appelle estimateur empirique d'un paramètre θ de F , l'estimateurobtenu en remplaçant la loi F par la loi empirique :
θ = t(F )
Dans le cas de la moyenne,
µ = E(F )
=1
n
n∑i=1
xi.
représente l'estimateur empirique.
1.2.2 Estimation de la variance de la moyenne empirique
Soit X une variable aléatoire réelle de loi F .On pose :
µF = EF (X).
et
σ2F = varF (X)
= EF (X − µF )2.
Soit (X1, . . . , Xn), n variables aléatoires réelles iid suivant la loi de F .On pose :
X =1
n
n∑i=1
Xi,
cette variable aléatoire a pour espérance mathématique µF et pour variance1
nσ2
F . L'es-
timateur empirique σ2F est dénie par :
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Fondements statistiques pour la gestion des données manquantes 9
σF =1
n
∑ni=1(Xi − X)2,
ce qui donne la variance empirique classique de l'échantillon. On en déduit l'estimateurempirique de la variance de la moyenne empirique :
1
n2
∑ni=1(Xi − X)2.
Remarque
1. Le principe fondamental de cette méthode est basé sur la loi des grands nombres.
2. Nous avons juste présenté les aspects de la méthode que nous utilisons dans cemémoire.Le lecteur intéressé pourra consulter les ouvrages [3] et [4] pour plus de détails,notament la construction des intervalles de conance, etc.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Chapitre Deux
Méthodes statistiques pour la gestion
des données manquantes
2.1 Quelques notions théoriques
Les principales notions présentées ci-dessous ont été developpées par Rubin et ouLittle [6]
2.1.1 Types de données manquantes
Soit Y = (Yij), la matrice n × p de données complètes, où n représente le nombred'individus et p le nombre de variables. Soit Yobs, la partie de Y ne contenant aucunevaleur manquante et Ymis celle qui en contient. Souvent, la structure des données man-quantes dépend des variables considérées. On dira que les données manquantes sont(MAR) "missing at random" si et seulement si la probabilité pour qu'une observationsoit manquante peut dépendre de Yobs, mais pas de Ymis [7]
Considérons, par exemple, un ensemble de 3 variables Y1 et Y2 totalement observéeset Y3 contenant des données manquantes. MAR assume que la probabilité pour que Y3
soit manquante pour un individu peut être en relation avec les valeurs des variables Y1
et Y2 de cet individu, mais pas avec sa valeur en Y3.On dira que les données sont MCAR "missing completely at random" lorsque la pro-
babilité qu'une valeur soit manquante sur une variable particulière Yj est indépendantede la valeur de Yj elle même ou de la valeur de n'importe quelle autre variable dans lamatrice de données. Formellement, soit M = mij, une matrice indicatrice des donnéesmanquantes d'éléments mij tel que mij = 1 si Yij est manquante et 0 sinon. Les donnéesmanquantes sont MCAR si P (M/Y, φ) = P (M/φ), ∀Y . La caractéristique MCAR estimportante car elle conduit à des estimateurs aux propriétés statistiques intéressantes,par exemple convergentes.
On dira que les données manquantes sont NMAR "non missing at random" lorsquela probabilité d'observer une valeur manquante sur la variable Yj est dépendante de lavariable Yj elle même. Les données NMAR constitue la situation où les biais sont lesplus importants.
Il est impossible d'être en mesure d'identier le véritable mécanisme qui sous-tend laprésence de valeurs manquantes (Schafer, 1998 ; Little, et Rubin, 2002). En conséquence,
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Méthodes statistiques pour la gestion des données manquantes 11
les trois mécanismes sont considérés comme étant des postulats. Il est cependant reconnuque les données manquantes seraient rarement MCAR (Little, et Rubin, 2002).
2.1.2 Types de modèles
Une technique répandue pour gérer la non-réponse partielle est d'imputer une valeurà chaque donnée manquante. Quelques principes doivent cependant être respectés (cf.Little et Schenker (1995) par exemple) [6]. Premièrement, les imputations devraient êtrebasées sur la distribution prédictive des valeurs manquantes étant données les valeursobservées. Un deuxième principe important de l'imputation est d'utiliser des tiragesaléatoires an de préserver la distribution des variables dans la base complétée des don-nées. Les procédures d'imputation peuvent être basées sur des modèles qui peuvent être"explicites", "implicites", ou une combinaison des deux. Les modèles explicites sont is-sus en général de la théorie statistique : régression linéaire, modèle linéaire généralisé,etc. Par exemple, une imputation stochastique par régression utilise un modèle expli-cite. Les modèles implicites sont ceux qu'on retrouve dans les procédures permettant derégler pratiquement des problèmes de structure de données. Ils sont souvent de type nonparamétrique. A titre d'exemple, on peut citer les procédures "hot-deck" qui reposentsur une modélisation implicite.
Une distinction supplémentaire est également utile : les modèles sur lesquels reposentles méthodes d'imputation, qu'ils soient implicites ou explicites, peuvent en outre êtreclassés en modèles "informatifs" ou "non informatifs" ("non-ignorable / ignorable mo-del"). On dira qu'un modèle est non informatif ("ignorable model") si une valeur Xr
d'un non-répondant est seulement stochastiquement diérente de celle d'un répondantqui a les mêmes valeurs X1, . . . , Xr−1. Un modèle est dit par contre informatif ("no-nignorable model") si on admet que même si un répondant et un non-répondant sontidentiques par rapport à X1, . . . , Xr−1, leurs valeurs Xr dièrent systématiquement [7].Autant les modèles informatifs que non informatifs peuvent être utilisés comme based'une procédure d'imputation.
2.1.3 Les techniques d'imputation
La correction de la non-réponse partielle par une imputation unique, à savoir pourchaque valeur manquante imputer une seule valeur, présente un défaut majeur. Eneet, du fait qu'une unique valeur imputée ne peut pas représenter toute l'incertitudeà propos de la valeur à imputer, les analyses qui considèrent les valeurs imputées demanière équivalente aux valeurs observées en général sous-estiment l'incertitude, mêmesi la non-réponse est correctement modélisée et des imputations aléatoires sont générées.Cet handicap, s'il n'est pas correctement appréhendé, peut conduire entre autres à desvariances nettement sous-estimées.
La technique de l'imputation multiple, développée principalement par Rubin [7],peut remédier à ces inconvénients. Elle remplace chaque donnée manquante par deuxvaleurs ou plus tirées d'une distribution appropriée pour les valeurs manquantes sous leshypothèses postulées à propos de la non-réponse. Le résultat est deux bases de donnéesou plus. Chacune est analysée en utilisant une même méthode standard. Les analyses
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Méthodes statistiques pour la gestion des données manquantes 12
sont ensuite combinées de telle manière à reéter la variabilité supplémentaire due auxdonnées manquantes. Un autre avantage de l'imputation multiple est qu'elle permet detrouver des estimateurs ponctuels plus ecaces. Enn, d'un point de vue théorique,on peut motiver la méthode d'imputation multiple par une approche bayésienne. Plusle nombre K d'imputations est grand, plus les estimateurs seront précis. Cependant,en pratique, on constate qu'on a de bons résultats déjà à partir d'un petit nombred'imputations (par exemple K = 5).
2.1.4 Procédure d'imputation multiple "valide"
On dit d'une procédure d'imputation multiple, basée ou non sur des modèles im-plicites ou explicites, ou sur des modèles informatifs ou non informatifs, qu'elle est"appropriée" si elle incorpore la variabilité adéquate parmi les K ensembles d'imputa-tions dans le cadre d'un modèle (cf. dénition exacte in Rubin (1987), chap4)[7]. Uneprocédure d'imputation "appropriée" garantit des inférences qui soient valables. Toutesles procédures ne sont pas "appropriées". La procédure d'imputation ABB ("Approxi-mate Bayesian Bootstrap") l'est. C'est une procédure de type "hot-deck" qui incorporeles idées des méthodes bootstrap.
2.1.5 La procédure d'imputation ABB "approximate bayesian
bootstrap".
On peut décrire la procédure d'imputation ABB de la manière suivante. Soit unecollection de n unités de mêmes valeurs X1, . . . , XV−1, où l'on trouve pour la variableXV , nR répondants et nNR = n − nR non répondants. Pour chacun des K ensemblesd'imputations, on tire aléatoirement avec remise dans l'ensemble des répondants d'abordn valeurs possibles de XV . Ensuite, on impute les nNR valeurs manquantes de XV entirant aléatoirement avec remise de l'ensemble des n valeurs précédemment tirées.
Notons que le tirage de nNR valeurs manquantes d'un échantillon possible de nvaleurs plutôt que de l'échantillon observé de nR valeurs génère la variabilité appropriéeentre les imputations, du moins en supposant de grands échantillons aléatoires simples.Ensuite, supposer une collection de n unités de mêmes valeurs de X1, . . . , XV−1 , permetde classer les répondants et les non répondants dans un même ensemble homogène.L'homogénéité ici dépendant de la méthode utilisée.
2.1.6 Revue des inférences en présence d'imputation multiple.
Dans cette sous-section, nous allons présenter le calcul d'un estimateur et l'estimationde sa variance dans le cadre d'un système d'imputation multiple. Avant tout, nousprésentons le calcul d'un estimateur général d'un paramètre θ issu d'une populationdonnée.
Soit Ω une population nie ou innie. On s'intèresse à un paramètre θ dont on neconnait pas la vraie valeur ; on peut alrs l'estimer par θ à base d'un échantillon extraitde la population. Considérons M échantillons de taille n extraits au hasard de cette
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Méthodes statistiques pour la gestion des données manquantes 13
population. Chaque échantillon constitue une distribution statistique pour laquelle onpeut estimer un paramètre θ de la distribution de la population (médiane, moyenne,écart type etc. . .). Ainsi, pour la totalité des échantillons prélevés dans la population,on va obtenir M estimateurs θm, m = 1, . . . ,M du paramètre étudié θ. L'estimateurnal de θ noté θ sera alors la moyenne des M estimateurs θm soit :
θ =1
M
M∑m=1
θm.
L'estimateur de la variance de θ notée U sera la moyenne des estimations des variancesdes M estimateurs θm.
Tous les résultats présentés ci-dessous se trouvent dans [8].
1. Cas scalaireSoient θm et Um, m = 1, . . . ,M , les M estimateurs respectivement du paramètreθ et ceux de la variance des estimateurs de θ notée U calculés à partir de chacundes M ensembles de données complétées par imputation. L'estimateur nal de θest :
θ =1
M
M∑m=1
θm, (2.1)
soit la moyemme des M estimateurs obtenus à partir des données completées.Soit également U , la moyenne des m variances et B la variance estimée de l'échan-tillon des estimateurs calculés de θ alors
U =1
M
M∑m=1
Um et B =1
M − 1
M∑m=1
(θm − θ)2 ; (2.2)
U est appelée variance intra-imputation etB est appelée variance inter-imputation.La variance d'imputation totale notée VT est donnée par la formule
VT = U +(1 +
1
M
)B, (2.3)
somme des deux composantes intra et inter-imputation avec un terme de correctionadditionnel qui tient compte de l'erreur de la simulation. Intervalle de conance des estimateurs.L'intervalle de conance du paramètre estimé est
ICθ =[
θ − Z1−α
√VT ; θ + Z1−α
√VT
].
où Z1−α est le quantile d'ordre 1−α de la distribution de Student dont le nombrede degrés de liberté (ddl) est donné par
ddl = (M − 1)(1 +
MU
(M + 1)B
)2
.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Méthodes statistiques pour la gestion des données manquantes 14
Estimation du taux d'information manquante (Rubin) [8].Le taux d'information manquante noté γ est donnée par la formule
γ =r + 2/(ddl + 3)
r + 1, (2.4)
où
r =1 + M−1U
B,
=VT − U
U.
représente l'accroissement relatif de la variance due aux données manquantesestimées.
EcacitéL'ecacité d'une estimation basée sur M imputations est(
1 +γ
M
)−1
(2.5)
où γ est le taux d'information manquante.
2. Cas vectorielLe paramètre estimé θm est un vecteur et Um est sa matrice de variance covarianceestimée. Les expressions developpées ci-dessous pour θ, U et VT sont identiques aucas scalaire, tandis que B s'écrit comme :
B =1
M − 1
M∑m=1
(θm − θ)(θm − θ)T , (2.6)
où (θm − θ)T désigne la transposée de θm − θ.On peut calculer une statistique D de type Wald comme suit :
D =θT U−1θ
k(1 + r), (2.7)
où r = (1 + M−1)tr(BU−1)/k,tr désigne la trace de la matrice (BU−1), k est la dimension du vecteur θ, r est leratio moyen estimé inverse de la fraction de l'information manquante. La statis-tique D permet de tester l'hypothèse nulle globale θ = 0 et suit approximativementune loi de Fischer Fkw avec w choisi comme
4 + (ν − 4)
1 + (1− 1
2νr−1
2
si ν = k(M − 1) > 4,
1
2ν(1 + k−1)(1 + r−1)2 sinon.
En pratique, toutes les variances intra-imputations du paramètre estimé seront estiméespar bootstrap dont le code R se trouve à l'annexe.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Méthodes statistiques pour la gestion des données manquantes 15
2.2 Description de quelques méthodes
Il existe plusieurs techniques d'imputation multiple. Dans cette section, nous allonsdécrire la méthode de régression, la méthode de propensity score et la méthode MCMC.Cependant pour les analyses seront également utilisées laméthode k-nn, la méthode dela moyenne et la méthode de transformation vers une loi normale (ces méthodes serontdécrites dans la partie "Application").
2.2.1 Méthode de régression multiple
Dans la méthode de régression, un modèle de régression linéaire est ajusté pourchaque variable avec données manquantes, avec comme covariables les valeurs totale-ment observées. Basé sur ces résultats, un nouveau modèle est alors ajusté pour imputerles valeurs manquantes dans chaque variable qui en contient. Le processus est répétéséquentiellement pour chaque variable avec données manquantes [9].
Considérons donc un ensemble de données avec les variables Y1, . . . , Yj, . . . , Yp, oùles colonnes Y1, . . . , Yj−1 sont totalement observées et Yj, . . . , Yp ayant des données man-quantes. Pour la variable Yj avec données manquantes, on régresse le modèle Yj =
β0 + β1Y1 + . . . + βj−1Yj−1. Ce modèle ajusté a alors les paramètres estimés β0, . . . , βj−1
et la matrice de variance-covariance associée est σ2j Vj, où Vj = XT X et σ2
j est la variance
des résidus. On remplace ainsi chaque valeur manquante de Yj par β0 + β1Y1 + . . . +
βj−1Yj−1 +Zjσj, où Y1, . . . , Yj−1 sont les variables totalement observées et Zj est une va-riable aléatoire ∼ N(0, 1). On procède ainsi de suite pour toutes les variables contenantles données manquantes. On obtient ainsi une base de données complète. On refait lemême processus m fois (5 fois susent) et on obtient m bases de données complètes ; onréalise une analyse statistique identique sur chacun des m tableaux de données obtenuset on combine les résultats pour avoir la véritable estimation du paramètre.
2.2.2 Méthode de propensity score
Le propensity score est la probabilité conditionnelle d'assignation d'une valeur man-quante étant donné un vecteur de covariables observées [9] .
Dans la méthode de propensity score (ps), un ps est généré pour chaque variableavec données manquantes pour indiquer la probabilité que chaque observation soit man-quante. Les observations sont alors groupées sur la base de ce ps et un ABB est alorsappliqué à chaque groupe [9] . Les étapes suivantes sont utilisées pour imputer chaquevariable avec valeurs manquantes
1. On crée une variable indicatrice Rj qui prend la valeur 1 si la donnée est manqantepour Yj et 0 sinon.
2. On ajuste un modèle de régression logistique logit(pj) = β0 +β1Y1 + . . .+βj−1Yj−1
où pj = Pr(Rj = 1/Y1, . . . , Yj−1) et logit(pj) = log(pj/(1− pj)).
3. On crée un propensity score pour indiquer la probabilité que chaque valeur soitmanquante
4. On divise les observations en k groupes homogènes suivant le propensity score.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Méthodes statistiques pour la gestion des données manquantes 16
5. On applique un ABB à chaque groupe
Considérons le groupe k et notons Yobs les n1 observations sans données manquanteset Ymanq les n0 observations avec données manquantes dans la variable Yj. On tirealéatoirement et avec remise n observations de l'ensemble des n1 valeurs observées dans legroupe k. Ensuite, on impute les valeurs ainsi obtenues au valeurs manquantes du groupek ; on le fait ainsi de suite pour chaque groupe et on obtient la colonne Yj complète.On refait le même processus pour les autres variables avec données manquantes et onobtient une base de données complète. Le processus précèdent est répété m fois and'obtenir m bases de données complètes.
2.2.3 Méthode MCMC
MCMC a été créée en physique comme un instrument pour explorer l'équilibre dela distribution des interactions entre les molécules. En statistique appliquée, il est uti-lisé pour générer les tirages aléatoires multidimensionnels et également pour calculerles probabilités via les chaînes de Markov. Une chaîne de Markov est une séquence devariables aléatoires dans laquelle la distribution de chaque élément dépend de la précé-dente. Dans les modèles MCMC, on construit la chaîne assez longue pour la distributiondes éléments an de stabiliser cette dernière vers une distribution d'intérêt appelée dis-tribution stationnaire. Il existe diérents types de méthodes de création des chaînes[9] :
Gibbs sampling, l'algorithme de Métropolis-Hastings, la Data Augmentation
Cette dernière méthode est celle qui est appropriée pour gérer les problèmes de donnéesmanquantes.
Considérons maintenant le modèle statistique (Pθ, θ ∈ Rd) dominé par la mesureλ. On suppose que les paramètres suivent une loi de probabilité Π(θ) (dans cette sous-section, le paramètre θ devient une variable aléatoire). La distribution à postériori duparamètre conditionnellement aux observations est :
Π(θ/x) =f(x/θ)Π(θ)∫f(x/θ)Π(θ)dθ
,
où le numérateur représente la loi jointe du couple (x, θ) et le dénominateur la loimarginale de X.
Data Augmentation
C'est une classe d'algorithme MCMC spécialement utile dans la résolution des pro-blèmes de données manquantes. Elle se déroule en 2 étapes qui se répètent plusieurs foisjusqu'à l'obtention de la stationnarité.
Etape I : tirage au hasard de Y(t+1)mis ∼ P(Ymis/Yobs, θ
(t))
Etape P : tirage au hasard de θ(t+1) ∼ P(θ/Yobs, Y(t+1)mis ),
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Méthodes statistiques pour la gestion des données manquantes 17
ce qui crée pour chaque individu une chaîne de Markov
(Y(1)mis, θ
(1)); (Y(2)mis, θ
(2)); . . . ;
qui converge en probabilité vers
P(Ymis, θ/Yobs
)distribution prédictive à posteriori des données utilisées pour les imputations.
Convergence : La chaîne est dite convergente ou atteint la stationnarité après titérations si
θ(t) est indépendant de θ(0)
θ(2t) est indépendant de θ(t) etc...c'est à dire si la chaîne a assez tourné pour oublier le paramètre initial supposé connu.La data augmentation simule alternativement données manquantes et paramètres, créeun chaîne de Markov qui converge vers la distribution prédictive correcte.Utilisation de la data augmentation
Sélectionner des valeurs de départ pour les paramètres. Faire tourner la procédure pendant k cycles en choisissant k assez grand pourassurer l'indépendance statistique des imputations successives.
Générer une imputation simple et répéter la procédure m fois.Utilisation de la data augmentation pour créer des imputations multiples.
Obtenir itérativement des Ymis en faisant tourner la procédure data augmentationrequiert des valeurs de départ pour les paramètres (le bon choix du paramètre est donnépar l'algorithme EM1).
L'algorithme EM
L'algorithme EM est une technique d'estimation par le maximum de vraisemblancedans des modèles paramétriques de données incomplètes. Les livres de Little et Rubin(1987), Schafer (1997) fournissent une description plus détaillée et des applications decet algorithme.
La méthode du maximum de vraisemblance .
La méthode du maximum de vraisemblance est l'une des techniques les plus po-pulaires pour estimer des paramètres, puisqu'en général, elle donne des estimateursconvergents et de faible variance. C'est la méthode utilisée dans l'application de l'algo-rithme EM. Un rappel de la méthode du maximum de vraisemblance pour des donnéescomplètement observables est le sujet abordé dans ce paragraphe.
Soit X1, . . . , Xn, un échantillon aléatoire et iid d'une population ayant comme fonc-tion de masse de probabilité ou de densité f(x/θ), où θ = (θ1, . . . , θd)
T . En pratique, ons'intéresse souvent aux modèles reguliers 2.
1signie en anglais expectation-maximization2On suppose que la densité vérie certaines propriétés et sous ces conditions on connaît certaines
propiétés de l'estimateur du pamètre, cf annexe
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Méthodes statistiques pour la gestion des données manquantes 18
Sous ces conditions, l'estimateur du maximum de vraisemblance satisfait les théo-rèmes 2.2.1 et 2.2.2 donnés à la n de la sous-section. Aussi, la fonction de vraisemblancepour un échantillon est donnée par :
L(θ/x) =n∏
i=1
f(xi/θ) = f(x, θ), (2.8)
où x = (x1, . . . , xn)T .Le logarithme naturel de (2.8) est la fonction de log-vraisemblance, dénotée
l(θ/x) = ln(L(θ/x)
). (2.9)
La dérivée de la fonction (2.9) est la fonction de score
S(θ/x) =∂l(θ/x)
∂θ, (2.10)
où S(θ/x) =(S1(θ/x), . . . , Sd(θ/x)
)T
avec Si(θ/x) =∂l(θ/x)
∂θi
, i = 1 . . . d.
L'estimateur du maximum de vraisemblance (EMV) θ de θ est une valeur qui maximisela fonction de vraisemblance ou, de façon équivalente, la fonction de log-vraisemblance.Sous les conditions de regularités précédentes sur f(x/θ), l'EMV peut être obtenu ensolutionnant les équations de scores suivantes :
∂L(θ/x)
∂θ= 0, (2.11)
ouS(θ/x) = 0. (2.12)
De plus, la matrice de l'information observée est dénotée par
I(θ/x) = −∂S(θ/x)
∂θT
= −∂2l(θ/x)
∂θ∂θT,
où θT = (θ1, . . . , θd) est la transposée de θ ; la matrice d'information de Fisher est notéepar :
I(θ) = −Eθ
[I(θ/X)
].
De plus, les estimateurs du maximum de vraisemblance ont les propriétés suivantes :
Théorème 2.2.1. (Propriété d'invariance des EMV)Si θ est l'EMV de θ, alors pour toute fonction τ(θ), l'EMV de τ(θ) est τ(θ)
Théorème 2.2.2. (Convergence des EMV)Soit θ, l'EMV de θ. Sous les conditions de regularité sur f(x, θ), ∀ ε > 0 et ∀ θ ∈ Θ,
limn→+∞
Pθ
(|θ − θ| ≥ ε
)= 0,
c'est-à-dire que θ est un estimateur convergent de θ.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Méthodes statistiques pour la gestion des données manquantes 19
Théorème 2.2.3. (Normalité asymptotique des EMV )Soit θ, l'EMV de θ. Sous les conditions de regularité sur f(x, θ),
√n[θ − θ
] L→n→+∞
N(0, I−1(θ)
),
c'est-à-dire que θ est un estimateur asymptotiquement normal de θ.
La méthode du maximum de vraisemblance indispensable pour résoudre le problèmeposé par l'algorithme EM étant ainsi présentée, nous passons à la description de ce der-nier.
L'algorithme EM est une procédure itérative qui trouve une estimation du maxi-mum de vraisemblance du vecteur de paramètre par répétition de ces étapes.
1. "L'étape d'espérance" (étape-E).Etant donné un ensemble de paramètres estimés tel que le vecteur moyenne et lamatrice de variance-covariance d'une distribution multi normale, l'étape-E calculel'espérance conditionnelle de la log-vraisemblance du tableau de données connais-sant les valeurs observées et le paramètre estimé.
2. "L'étape de maximisation" (étape-M).L'étape-M est l'étape de maximisation de la log-vraisemblance obtenue à l'étapeprécédente ; on trouve alors l'estimateur qui maximise l'équation trouvée à l'étape-E
Ces deux étapes sont répétées itérativement jusqu'à la convergence et, on l'espère, l'ob-tention de l'estimateur du maximum de vraisemblance. Moins il ya de données man-quantes, plus l'estimateur sera simple à calculer.
Concrètement, soit X = (Ymis; Yobs) le vecteur de toutes les observations, où Yobs estla partie observée et Ymis la partie manquante. Soit θ(0) une valeur initiale de θ choi-sie arbitrairement à laquelle l'algorithme débute. Alors à la 1ere itération, l'étape-E secalcule comme suit :
Q(θ/θ(0)) = E(0)θ
[lc(θ/θ
(0))/Yobs
];
ensuite l'étape-M maximise l'équation ci-dessus par rapport à θ ∈ Θ. En fait, θ(1) estchoisi selon l'inéquation
Q(θ(1)/θ(0)
)≥ Q
(θ/θ(0)
), ∀θ ∈ Θ.
A la 2e itération, les étapes E et M sont refaites, mais cette fois avec θ(1) au lieu de θ(0).Voici donc les étapes E et M pour l'itération b + 1 :
Etape-E : calculer Q(θ/θ(b)) = E(b)θ
[lc(θ/θ
(b))/Yobs
] Choisir θ(b+1) qui est une valeur de θ ∈ Θ qui maximise l'équation ci-dessus, c'est-à-dire telle que
Q(θ(b+1)/θ(b)
)≥ Q
(θ/θ(b)
), ∀θ ∈ Θ.
Ces deux étapes sont répétées jusqu'à ce que la diérence entre la fonction devraisemblance de l'itération b+1 et celle de l'itération b dièrent peu. C'est-à-direlorsque
l(θ(b+1)/Yobs)− l(θ(b)/Yobs) ≤ ε
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Méthodes statistiques pour la gestion des données manquantes 20
où ε est une valeur positive très proche de 0. Il est prouvé que l'algorithme EMdécroît après une itération.
L'algorithme EM pour les familles exponentielles .
Si la distribution des données complètes est un membre de la famille exponentielle,alors l'algorithme est plus simple à mettre en ÷uvre.
On dénit la famille exponentielle comme la famille des distribution dont la den-sité est donnée par
fc(x, θ) = b(x)expcT (θ)t(x)/a(θ),
où t(x) est une statistique exhaustive de dim k × 1, où k > d si θ = (θ1, . . . , θd) ; c(θ)est un vecteur de dim k× 1 qui est une fonction du vecteur de paramètre θ de dim d× 1et a(θ) et b(x) sont des fonctions scalaires.
Si k = d et que le jacobien de c(θ) est de rang complet alors fc(x, θ) ∈ à la fa-mille exponentielle regulière. Et dans ce cas, c(θ) = θ et la densité devient :
fc(x, θ) = b(x)expθT t(x)/a(θ). (2.13)
Dans ce cas, la fonction de log-vraisemblance a la forme suivante :
lc(θ/x) = ln(b(x)
)− ln
(a(θ)
)+ θT t(x). (2.14)
Maximiser (2.14) par rapport à θ revient à maximiser
lc(θ/t(x)
)= −ln
(a(θ)
)+ θT t(x),
qui ne dépend de x que par t(x). Alors
Eθ
[lc(θ/x)
]= Eθ
[lc(θ/t(x)
)]= −ln
(a(θ)
)+ θT Eθ
(t(x)
)=
lc
(θ/Eθ
(t(x)
)). (2.15)
De plus, si on intègre par rapport à x des 2 cotés de l'equation (2.13), on a :
1 =
∫ +∞
−∞fc(x/θ)dx =
∫ +∞
−∞
[b(x)expθT t(x)/a(θ)
]dx,
d'où
a(θ) =
∫ +∞
−∞b(x)expθT t(x)dx.
En dérivant la relation ci-dessus par rapport à θ, on a :
da(θ)
dθ=
∫ +∞
−∞
d
dθb(x)expθT t(x)dx ;
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Méthodes statistiques pour la gestion des données manquantes 21
il vient :
a(θ)dlna(θ)
dθ=
∫ +∞
−∞b(x)t(x)expθT t(x)dx ;
d'où
a(θ)dlna(θ)
dθ=
∫ +∞
−∞t(x)fc(x/θ)a(θ)dx d'après 2.13,
c'est-à-dire que :dlna(θ)
dθ=
∫ +∞
−∞t(x)fc(x/θ)dx ;
par conséquent,
dlna(θ)
dθ= Eθ
(t(x)
); (2.16)
qui est l'espérance de la statistique t(X). les équations (2.15) et (2.16) sont utilisées dansles étapes E et M de l'algorithme EM pour les familles exponentielles régulières. Uneautre propriété intéressante concernant les familles exponentielles régulières canoniquesest que la matrice d'information espérée de θ est égal à la matrice de variance covariancede t(X).
Ic(θ) = covθ
[t(X)
].
Remarque
Il est important de souligner que, que ce soit la méthode de régression ou la méthodede propensity, les données manquantes doivent avoir une structure monotone c'est-à-dire que si une variable Yj est manquante pour un individu i alors toutes les variablessubséquentes Yk, k > j sont aussi toutes manquantes pour l'individu i. La méthodeMCMC n'impose pas cette condition. Cependant il existe une procédure implémentéedans le logiciel SAS version 8.1 "impute monotone" qui permet d'obtenir la structuremonotone et de pouvoir par la suite appliquer les méthodes précédentes.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Chapitre Trois
Etude descriptive du projet DARVIR
Tab. 3.1 Données d'inclusionNOM VARIABLE CODAGE
IDENT Identicateur du patientCENTRE centre de suivi 1=centre1 ; 2=centre2 ; etc...
SEXE sexe dudu patient 1=homme
2=femmeAGE âge à
l'inclusion> 16ans en annéesSTATMAT statut matrimonial 1=célibataire ; 2=veuf
3=divorcé ; 4=marié polygame5=concubinage
PROF profession du patient Codage des professions del'enquête IFAN-ORSTROM
0=armée,police,.. ; 1=cadre supérieur libéral2=technicien supérieur
3=technicien adjoint peu qualié4=personnel de maitrise
5=gros commerçant ; 6=gestionnaire7=petit personnel de service8=ouvrier de l'industrie
9=religieux ou tradipraticien10=artisan ; 11=petit commerçant
12=agriculteur ; 13=activité sans qualication14=sans profession
15=commerçant sans précision16=étudiant ; 17=retraité
POIDSINC poids à l'inclusion en kgV IH type de vih 1=vih1 ; 2=vih2 ; 3=vih1-2
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Etude descriptive du projet DARVIR 23
Tab. 3.2 Données d'inclusion suiteNOM VARIABLE CODAGE
CV INC charge virale à l'inclusion En copies/ml ; pourles valeurs < au seuil du test, noter
la valeur des seuils(ex : pour cv<50c/ml, noter "50")
CD4INC taux de lymphocytes Tcd4 àl'inclusion par mm3
V HC sérologie hépatite C 0=négative ; 1=positive ; 2=indéterminéeSTADECDC stade cdc à l'inclusion 1=A ; 2=B ; 3=CATCDARV traitement ARV antérieur
à l'intérieur dans DARVIR 0=aucun ; A=AZT ; B=3TC ; C=DT4D=DDI ; E=DDC ; F=Névirapine
G=NelnavirH=Efavirenz ; I=Indinavir ; J=HydréaM= Triomune ; N=Duovir ; O=LamivirP=Combivir Q=Viracept ; R=TRIZIVIRS=ZIDOVIR ; T=HIVID ; U= NORVIRV=STAVIRAC ; 1=oui, mais inconnu
ARV INC traitement ARV prescrità l'inclusion dans DARVIR Idem à la variable
cidessusTRAITINC Autres traitements importants
associés aux ARV 0=aucun ; 1=Bactrim ;2= traitement antituberculeux ; 4=autre
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
Etude descriptive du projet DARVIR 24
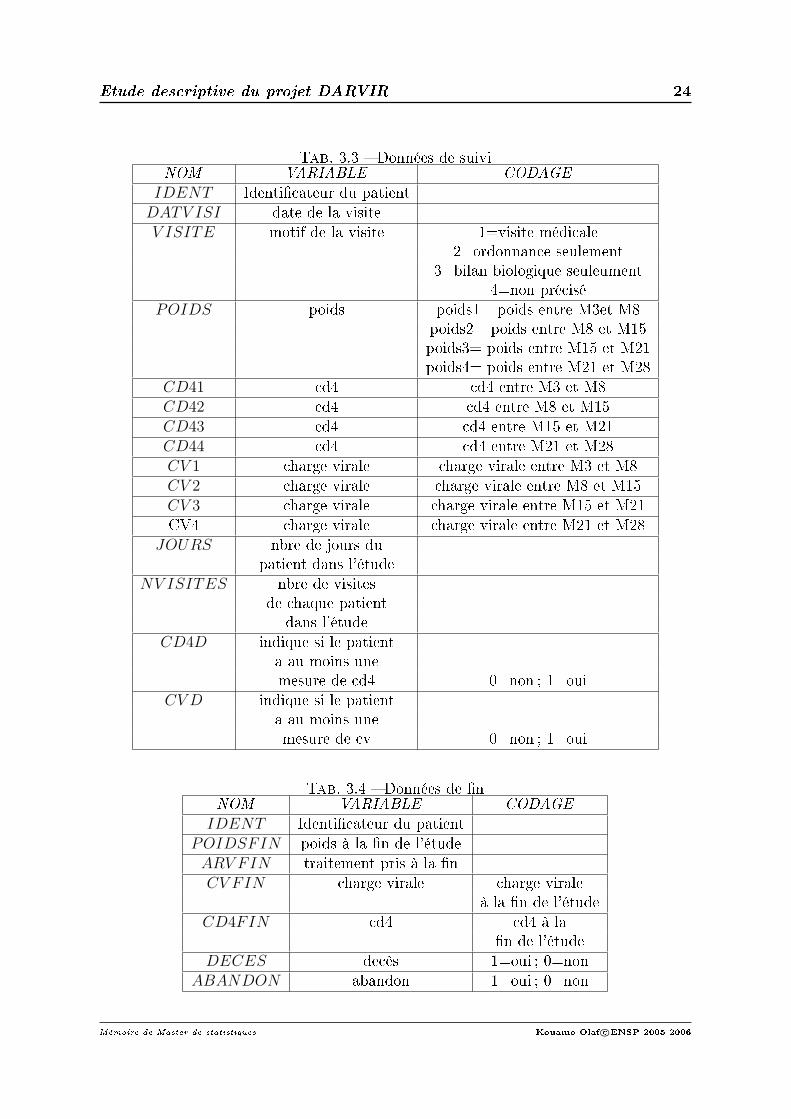
Tab. 3.3 Données de suiviNOM VARIABLE CODAGE
IDENT Identicateur du patientDATV ISI date de la visiteV ISITE motif de la visite 1=visite médicale
2=ordonnance seulement3=bilan biologique seuleument
4=non préciséPOIDS poids poids1= poids entre M3et M8
poids2= poids entre M8 et M15poids3= poids entre M15 et M21poids4= poids entre M21 et M28
CD41 cd4 cd4 entre M3 et M8CD42 cd4 cd4 entre M8 et M15CD43 cd4 cd4 entre M15 et M21CD44 cd4 cd4 entre M21 et M28CV 1 charge virale charge virale entre M3 et M8CV 2 charge virale charge virale entre M8 et M15CV 3 charge virale charge virale entre M15 et M21CV4 charge virale charge virale entre M21 et M28
JOURS nbre de jours dupatient dans l'étude
NV ISITES nbre de visitesde chaque patient
dans l'étudeCD4D indique si le patient
a au moins unemesure de cd4 0=non ; 1=oui
CV D indique si le patienta au moins unemesure de cv 0=non ; 1=oui
Tab. 3.4 Données de nNOM VARIABLE CODAGE
IDENT Identicateur du patientPOIDSFIN poids à la n de l'étudeARV FIN traitement pris à la nCV FIN charge virale charge virale
à la n de l'étudeCD4FIN cd4 cd4 à la
n de l'étudeDECES decès 1=oui ; 0=non
ABANDON abandon 1=oui ; 0=non
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Etude descriptive du projet DARVIR 25
3.1 Statistique descriptive
Sept cent quatre vingt huit patients (788) ont été enrôlés dans l'étude d'octobre2000 à octobre 2003. Quatre cent neuf patients sont des femmes soit (51.9%) de la po-pulation étudiée. La médiane d'âge des patients est de 39 ans, l'intervalle interquartile1
RIQ = [32; 46] ans ; ainsi 25% des patients ont moins de 32 ans et 25% ont plus de 46 ans.La médiane à j0
2de la charge virale (cv) est de 94265 copies/ml,RIQ = [20225; 215435](données valables uniquement sur 131 patients) et celle de la numération des cd4 est de123 cellules/mm3, RIQ = [52; 202] (données valables sur 746 patients).
La plupart des patients sont symptomatiques, 57% des patients sont au stade B et32.6% au stade C 3(données valables sur 774 patients).
La médiane du nombre de visites pour les visites cliniques, les examens de labora-toire ou la prescription des ARV 4 est 9, RIQ = [4; 15] visites mais le nombre médiande visites médicales est 2, RIQ = [1; 4].
416 mesures de cv ont été réalisées pendant le suivi (22% des valeurs espérées sur270 patients). La médiane du nombre de mesures chez ces patients est de 1, RIQ = [1; 2]mesures. Or en principe, la cv est évaluée chez chaque patient tous les 6 mois.
619 numérations des cd4 ont été réalisées 37% du nombre espéré sur 397 patients(50.4%) ;la médiane de la numération des cd4 est également de 1, RIQ = [1; 2] [12]
1. Evolution du poids.On s'interesse à l'évolution du poids en fonction du temps.On notera M3 le poidsau 3e mois M8 le poids au 8e mois ainsi de suite. On évalue le poids à l'inclusion,entre M3 et M8 ,entre M8 et M15, entre M15 et M21, entre M21 et M28 et lepoids à la n de l'étude.La médiane du poidsinc est 64 kg, RIQ = [56; 72].La médiane du poids entre M3 et M8 est de 69 kg, RIQ = [61.75; 78] ; celle dupoids entre M8 et M15 est 70 kg, RIQ = [63; 78]. Entre M15 et M21 la médiane dupoids des patients devient 71.25 kg RIQ=[63 ; 81] ; entre M21 et M28 elle descendà 71 kg, RIQ = [63; 82] et enn la médiane du poids des patients à la sortie del'étude est 70 kg, RIQ = [61; 79] (les données ont été observées sur 639 personnes).On se rend donc compte que le poids des patients a légèrement évolué après lamise sous traitement.
2. Evolution de la charge virale.La médiane de la cv à l'inclusion était de 94265 copies/ml et elle est de 50 co-pies/ml entre M3 et M8, RIQ = [50; 515]. Soit une diminution médiane de 3.3log10
copies/ml(données observées uniquement sur 127 malades). Entre M8 et M15 lamédiane de cv est de 52 copies/ml, RIQ = [50; 271]. Soit une diminution médiande 3log10copies/ml(données observées uniquement sur 121 malades). Entre M15et M21 la médiane de cv est de 53 copies/ml, RIQ = [50; 873]. Soit une diminu-tion médian de 2.9log10copies/ml(données observées uniquement sur 78 malades).
1déni le 1er quartile et le 3e quartile21er jour de mise sous traitement antirétroviral3stade classant sida4anti-rétroviraux
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Etude descriptive du projet DARVIR 26
Entre M21 et M28 la médiane de cv est de 80 copies/ml RIQ = [50; 19370]. Soitune diminution médian de 2.7log10copies/ml(données observées uniquement sur 54malades). A la n de l'étude, la médiane de la cv est de 302copies/ml, RIQ=[50 ;26970] (données observées uniquement sur 33).
3. Evolution des cd4.La médiane des cd4 à l'inclusion était de 123cellules/mm3 elle est de 238cellules/mm3
entre M3 et M8, RIQ = [147; 361]. Soit une augmentation de la médiane de115 par rapport à j0 (données observées uniquement sur 266 malades).La mé-daine des cd4 est de 277.5cellules/mm3 entre M8 et M15, RIQ = [157; 384].Soit une augmentation de la médiane de 128(données observées uniquement sur154 malades). La médiane des cd4 est de 320cellules/mm3 entre M15 et M21,RIQ = [197; 434]. Soit une augmentation de la médiane de 197(données observéesuniquement sur 89 malades).La mediane des cd4 est de 290cellules/mm3 entre M21et M28, RIQ = [205; 446]. Soit une augmentation de la médiane de 167 (donnéesobservées uniquement sur 89 malades). A la n de l'étude, la médiane des cd4 estde 223cellules/mm3, RIQ = [110; 350]. Soit une augmentation de la médiane de100cellules par rapport à l'inclusion (données observées uniquement sur 57 ma-lades).On a observé 52 decès. Soit un taux de mortalité de 6.6% et 5.5 décès pour 100 per-sonnes années(taux de décès sous-estimé car les données ont été observées unique-ment sur 639 patients). 24 personnes ont abandonné l'étude soit un taux d'abandonde 3% (données observées sur 580 patients).Le traitement le plus utilisé est la triomune (29.82% des patients l'ont utilisé àj0, 30% entre M3et M8. 25%, 37% et 15% respectivement entre M8 et M15, M15et M21 et M21 et M28. Ceci est sûrement du à son coût avantageux par rapportaux autres traitements et sa facilité dans la prise 1cp 2fois/jour. Le traitementimportant associé aux ARV à l'inclusion est le bactrim (45% des patients associele bactrim aux ARV : données observées sur 699 patients). Le type de vih le plusrépandu dans la population est le vih1 (80% des patients) suivi du vih1-2 (20%des patients) ; le vih2 n'a été observé chez aucun patient.La plupart des malades étaient sans profession (29.5% : données observées sur754 patients) et marié monogame (29.15% : données observées sur 773 patients).Notons tout de même que 34 patients étaient des religieux ou tradipraticienConclusion
Au vu de ces résultats, on peut dire que les traitements anti-rétroviraux ont uneréelle ecacité dans les 1er mois du traitement, car ils réduisent de manière consi-dérable la charge virale et les cd4 augmentent. A long terme (au bout d'un anou deux), cette ecacité devient mitigée. Ce phénomène peut s'expliquer par lefait que chez nous lorsqu'un patient commence à aller beaucoup mieux, il a ten-dance à partager son traitement avec une tierce personne et ainsi tous deux sontmal soignés. Une autre raison qui peut expliquer la diminution de l'ecacité dutraitement anti-rétroviral est qu'à long terme, les patients certes sont contents dese porter beaucoup mieux, mais les coûts élevés des médicaments et des examensbiologiques les ramènent à la réalité et ils sont obligés de se les attribuer unique-
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Etude descriptive du projet DARVIR 27
ment lorsque leurs moyens le leur permettent et non lorsque le médécin prescrit.Cependant, les tests biologiques sont réalisées sur très peu de patients. A titred'exemple, on n'a eu que 33 mesures de cv et 57 numérations de cd4 à la n del'étude. Ces patients ne sont pas représentatifs de l'ensemble des 788 patients,donc les résultats observés sur ces derniers ne devraient pas être extrapolés sur les788. D'où l'utilité de prendre en compte les données manquantes dans l'analyse enutilisant les méthodes d'imputation multiple an d'obtenir des bases de donnéescomplètes pour faciliter l'analyse.
Fig. 3.1 Proportion des patients ayant une cv< 400
Fig. 3.2 Proportion des patients ayant une cv<50
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Etude descriptive du projet DARVIR 28
Fig. 3.3 Evolution des cd4
Fig. 3.4 Evolution des poids
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Chapitre Quatre
Applications des techniques
d'imputation multiple pour gérer la
non réponse partielle
Introduction
Corriger la non réponse dans une enquête ou un essai clinique n'est jamais chosesimple et évidente. Des techniques de correction existent, en particulier la répondéra-tion et l'imputation. Cependant pour être appliquées correctement, elles nécessitent detenir compte du contexte dans lequel on se trouve. En eet, leur utilisation de façonmécanique, un peu comme des boîtes noires, permettrait eectivement de se sortir den'importe quelle situation, mais avec le risque d'introduire du biais. L'avantage de latechnique d'imputation est qu'elle permet d'obtenir des bases de données complètes,ce qui a l'avantage de préserver toute l'information sur les données et d'eectuer desanalyses en utilisant des logiciels qui nécessitent les données complètes. On distingue 2types d'imputation : l'imputation simple et l'imputation multiple.
1. Imputation simple.C'est une technique d'imputation qui permet de remplacer une valeur manquantepar une valeur plausible prédite ou simulée ; mais cette technique présente un réelinconvénient car elle ne reète pas toute l'incertitude des valeurs manquantes.
2. Imputation multiple.Création de plusieurs valeurs plausibles d'une donnée manquante. Le but n'est pasde prédire avec la plus grande précision les données manquantes, décrire les données de la meilleure façon possible,Les buts sont : décrire correctement l'incertitude due aux données manquantes, préserver les aspects importants des distributions, préserver les relations importantes entre les variables.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 30
4.1 Application de la méthode de propensity score
Les conditions qui sous-tendent la validité de la méthode n'étant pas totalementrespectées (la structure monotone n'est pas respectée), nous allons imputer les valeursmanquantes de la manière suivante. On regroupe toutes les variables ayant toutes leursobservations complètes à savoir : centre, sexe, nvisites, cd4d, cvd et jours ; on imputechaque variable avec données manquantes uniquement en fonction des données totale-ment observées qui pourraient expliquer le fait qu'une donnée soit manquante pour cettevariable.
4.1.1 Méthode de sélection du modèle optimal
Le problème est celui du choix des variables à retenir dans le modèle nal. Le critèreque nous utilisons pour choisir le modèle optimal est le critère d'information d'Akaiké(AIC). Il fournit une mesure de la quantité d'information donnée par le modèle. Il estobtenu en combinant la valeur de la log-vraisemblance, le nombre d'observations et lenombre de paramètres. Il est déni par :
−2logL
T+
2K
T
où T est le nombre d'observations, K le nombre de paramètres du modèle. On préfèrerale modèle fournissant un critère minimal.
Plusieurs méthodes existent pour retenir le meilleur modèle, c'est-à-dire celui com-posé des variables les plus correlées entre elles. On peut citer l'élimination progressive("Backward Elimination"), la sélection progressive ("Forward Regression"), la régres-sion pas à pas ("Stepwise Regression") qui est en quelque sorte une combinaison desdeux précédentes. Nous avons recours à cette dernière procédure dont les étapes sont lessuivantes :
Sélection à la 1ere étape, de la variable la plus corrélée avec la variable à expliquer. A la 2e étape, sélection de la variable la plus corrélée avec la variable à expliquerquand l'eet de la 1ere variable est éliminé. etc . . .
A chaque nouvelle introduction, la signicativité des variables explicatives préalablementsélectionnées est examinée et la procédure élimine du modèle celle(s) dont la p− value> au seuil critique. La sélection s'arrête quand l'AIC n'est plus diminué.
4.1.2 Résultats obtenus après imputation
La méthode de propensity score est appropriée tant pour les variables quantitativesque pour des variables qualitatives
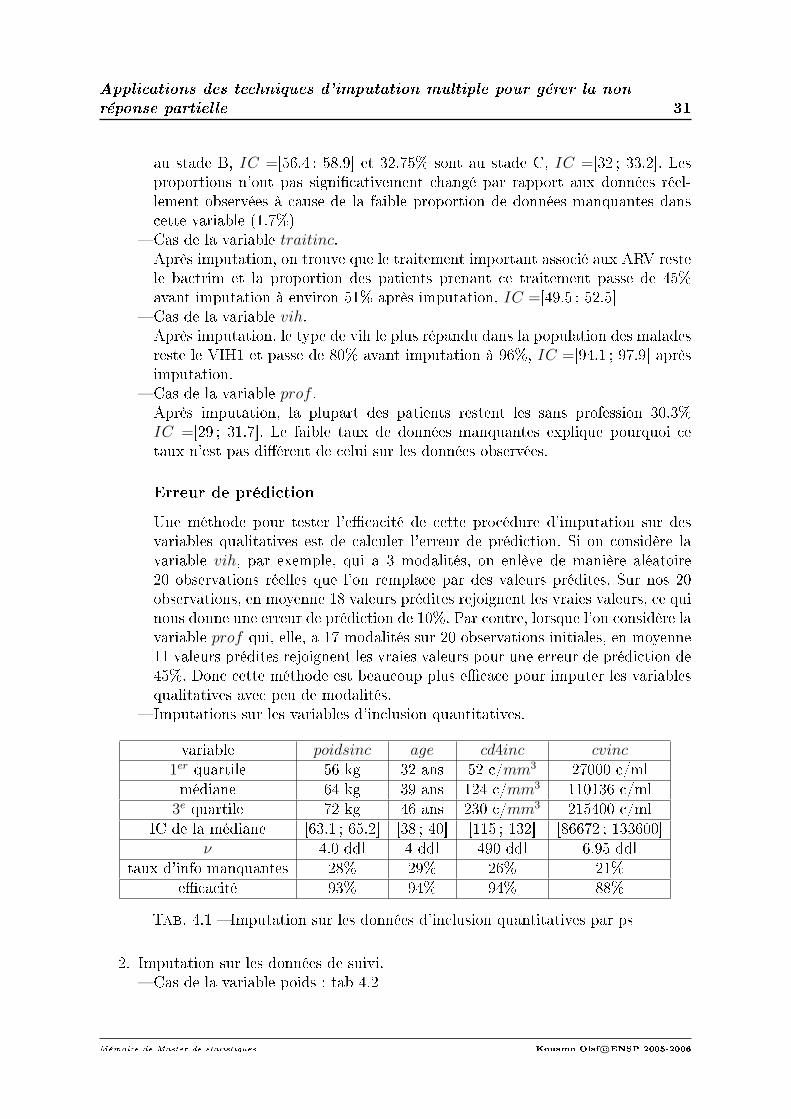
1. Imputation sur les données d'inclusion.
Cas de la variable stadeinc.Après imputation, la plupart des patients restent symptômatiques et les pro-portions des patients étant au stade B et stade C n'ont pas signicativementchangé par rapport aux données réellement observées (57.5% des patients sont
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 31
au stade B, IC =[56.4 ; 58.9] et 32.75% sont au stade C, IC =[32 ; 33.2]. Lesproportions n'ont pas signicativement changé par rapport aux données réel-lement observées à cause de la faible proportion de données manquantes danscette variable (1.7%)
Cas de la variable traitinc.Après imputation, on trouve que le traitement important associé aux ARV restele bactrim et la proportion des patients prenant ce traitement passe de 45%avant imputation à environ 51% après imputation, IC =[49.5 ; 52.5]
Cas de la variable vih.Après imputation, le type de vih le plus répandu dans la population des maladesreste le VIH1 et passe de 80% avant imputation à 96%, IC =[94.1 ; 97.9] aprèsimputation.
Cas de la variable prof .Après imputation, la plupart des patients restent les sans profession 30.3%IC =[29 ; 31.7]. Le faible taux de données manquantes explique pourquoi cetaux n'est pas diérent de celui sur les données observées.
Erreur de prédiction
Une méthode pour tester l'ecacité de cette procédure d'imputation sur desvariables qualitatives est de calculer l'erreur de prédiction. Si on considère lavariable vih, par exemple, qui a 3 modalités, on enlève de manière aléatoire20 observations réelles que l'on remplace par des valeurs prédites. Sur nos 20observations, en moyenne 18 valeurs prédites rejoignent les vraies valeurs, ce quinous donne une erreur de prédiction de 10%. Par contre, lorsque l'on considère lavariable prof qui, elle, a 17 modalités sur 20 observations initiales, en moyenne11 valeurs prédites rejoignent les vraies valeurs pour une erreur de prédiction de45%. Donc cette méthode est beaucoup plus ecace pour imputer les variablesqualitatives avec peu de modalités.
Imputations sur les variables d'inclusion quantitatives.
variable poidsinc age cd4inc cvinc1er quartile 56 kg 32 ans 52 c/mm3 27000 c/mlmédiane 64 kg 39 ans 124 c/mm3 110136 c/ml
3e quartile 72 kg 46 ans 230 c/mm3 215400 c/mlIC de la médiane [63.1 ; 65.2] [38 ; 40] [115 ; 132] [86672 ; 133600]
ν 4.0 ddl 4 ddl 490 ddl 6.95 ddltaux d'info manquantes 28% 29% 26% 21%
ecacité 93% 94% 94% 88%
Tab. 4.1 Imputation sur les données d'inclusion quantitatives par ps
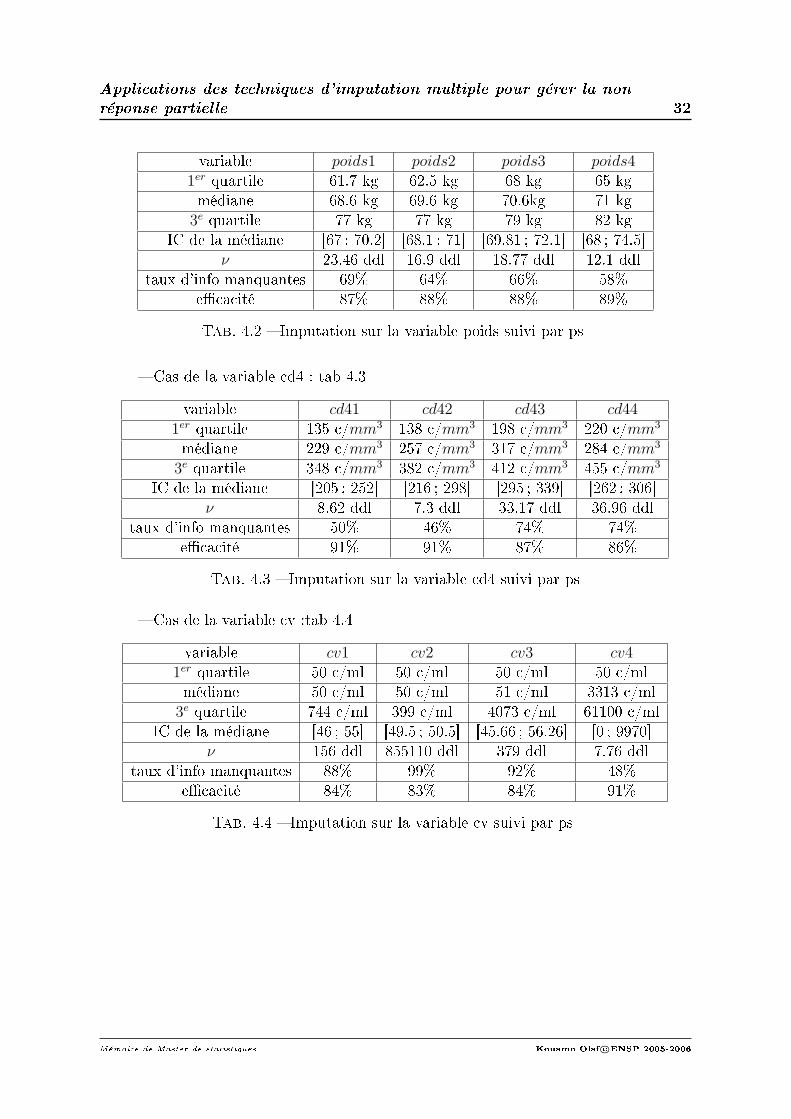
2. Imputation sur les données de suivi. Cas de la variable poids : tab 4.2
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 32
variable poids1 poids2 poids3 poids41er quartile 61.7 kg 62.5 kg 68 kg 65 kgmédiane 68.6 kg 69.6 kg 70.6kg 71 kg
3e quartile 77 kg 77 kg 79 kg 82 kgIC de la médiane [67 ; 70.2] [68.1 ; 71] [69.81 ; 72.1] [68 ; 74.5]
ν 23.46 ddl 16.9 ddl 18.77 ddl 12.1 ddltaux d'info manquantes 69% 64% 66% 58%
ecacité 87% 88% 88% 89%
Tab. 4.2 Imputation sur la variable poids suivi par ps
Cas de la variable cd4 : tab 4.3
variable cd41 cd42 cd43 cd441er quartile 135 c/mm3 138 c/mm3 198 c/mm3 220 c/mm3
médiane 229 c/mm3 257 c/mm3 317 c/mm3 284 c/mm3
3e quartile 348 c/mm3 382 c/mm3 412 c/mm3 455 c/mm3
IC de la médiane [205 ; 252] [216 ; 298] [295 ; 339] [262 ; 306]ν 8.62 ddl 7.3 ddl 33.17 ddl 36.96 ddl
taux d'info manquantes 50% 46% 74% 74%ecacité 91% 91% 87% 86%
Tab. 4.3 Imputation sur la variable cd4 suivi par ps
Cas de la variable cv :tab 4.4
variable cv1 cv2 cv3 cv41er quartile 50 c/ml 50 c/ml 50 c/ml 50 c/mlmédiane 50 c/ml 50 c/ml 51 c/ml 3313 c/ml
3e quartile 744 c/ml 399 c/ml 4073 c/ml 61100 c/mlIC de la médiane [46 ; 55] [49.5 ; 50.5] [45.66 ; 56.26] [0 ; 9970]
ν 156 ddl 855110 ddl 379 ddl 7.76 ddltaux d'info manquantes 88% 99% 92% 48%
ecacité 84% 83% 84% 91%
Tab. 4.4 Imputation sur la variable cv suivi par ps
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 33
3. Cas des données n : tab 4.5 Imputation sur les variables quantitatives.
variable poids cd4 cv1er quartile 61 kg 110 c/mm3 50 c/mlmédiane 69.5 kg 241 c/mm3 1460 c/ml
3e quartile 79 kg 392 c/mm3 33000 c/mlIC de la médiane [67.5 ; 71] [228 ; 255] [0 ; 3048]
ν 22.88 ddl 16.54 ddl 8.64 ddltaux d'info manquantes 69.5% 89% 92%
ecacité 87% 88% 92%
Tab. 4.5 Imputation sur les données n quantitatifs par ps
Cas de la variable deces.Avant imputation, le taux de décès était de 6.6% ; soit 5.5 décès pour100 per-sonnes années. Lorsque l'on impute, ce taux passe à 12% IC =[9.7 ; 14.1], soit9.64 décès pour 100 personnes années.
Cas de la variable abandon.Lorsqu'on réalise l'analyse sans prendre en compte les données manquantes ona 24 abandons (3%), après imputation, cette proportion double et passe à 6%IC =[4.3 ; 7.65].
Pour ces deux variables, et en procédant comme précédemment, on trouve uneerreur de prédiction de moins de 10%, ce qui conrme l'hypothèse selon laquellelorsqu'une variable a peu de modalités, la prédiction est plus ne.
4.2 Application de la méthode d'approximation par
une loi normale
Soit Xi une variable aléatoire dont les réalisations sont indépendantes. On montre que
la variable aléatoiren∏
i=1
Xi transformée en log suit asymptotiquement une distribution
normale.Plus généralement, on peut considérer une transformation autre que le log pour
approcher un processus normal. On considère la transformation de Box-Cox (1964) [10].
Y = Pλ(X) =
Xλ − 1
λsi λ 6= 0
log(X) si λ = 0.(4.1)
Ainsi, partant d'une variable X, on obtient la variable aléatoire Y qui dérive de X ets'approche le mieux d'une normale. Pour réaliser les inférences, on revient à la variable
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 34
originale par la transformation inverse.
X =
exp( log(λY − 1)
λ
)si λ 6= 0,
exp(Y ) si λ = 0.
(4.2)
Le λ optimal qui approche le mieux notre variable aléatoire vers une loi normale esttrouvé à l'aide de la fonction Box.Cox.Powers implémentée dans le logiciel R et qui setrouve dans le package "car". La loi normale n'étant appropriée que pour des variablescontinues, nous ne transformerons que les variables quantitatives.
Recherche des λ pour lesquels les variables s'approchent le mieux d' une normale. Données d'inclusion.
variable λâge 0.39
poidsinc 0cd4inc 0.38cvinc 0.29
Tab. 4.6 Choix de λ inclusion
Données suivi.
variable λpoids1 0poids2 0poids3 0poids4 -1.23cd41 0.48cd42 0.55cd43 0.63cd44 0.45cv1 -0.49cv2 -1.2cv3 -0.6cv4 -0.8
Tab. 4.7 Choix de λ suivi
Données n.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 35
variable λpoidsn 0.414cd4n 0.39cvn -0.12
Tab. 4.8 Choix de λ n
Il est important de souligner ici que le λ obtenu ici est celui qui approche le mieux lavariable aléatoire vers une loi normale. Il ne garantit pas qu'après transformation, lavariable suive une loi normale.
1. Imputation sur les données d'inclusion.Après transformation, les observations sur les variables age et poidsinc suiventune loi normale comme le conrme le test de Shapiro et la gure 4.1 qui compareles quantiles de nos observations transformées à ceux d'une loi normale ; l'aligne-ment des quantiles autour de la 1ere bissectrice prouve que la distribution suit unenormale.
variable p− valueâge 0.7
poidsinc 0.72
Fig. 4.1 Transformation normale données inclusion
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 36
Par contre les variables cd4inc et cvinc, même après transformation, ne suiventpas une loi normale, cf gure 4.2.
Fig. 4.2 Transformation cv-cd4inc
Pour imputer les valeurs manquantes, on procède comme suit. Sur chaque variable transformée, on simule un échantillon de taille celle desdonnées manquantes de la loi normale de moyenne celle des observations réelleset de variance celle des observations réelles.
On impute ces valeurs simulées aux valeurs manquantes. On revient à la variable d'intérêt après transformation inverse : équation (4.2)Pour réaliser les inférences, on simule plusieurs échantillons (au moins 5) et onobtient les résultats suivants pour les variables age et poidsinc.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 37
variable poids age1er quartile 56 kg 32 ansmédiane 64 kg 39 ans3e quartile 72 kg 46 ans
IC de la médiane [63.1 ; 65.2] [38 ; 40]ν 4 ddl 4.7 ddl
taux d'info manquantes 28% 29%ecacité 94% 94%
Tab. 4.9 Imputation sur les données inclusion par transformation
On retrouve des valeurs qui ne sont pas signicativement diérentes de cellesobtenues par la méthode ps 1 (cf tab.4.1).
2. Imputation sur les données de suivi. Cas du poids suivi.Pour les poids des patients pendant le suivi, la transformation log approxime lespoids1, poids2 et poids3 comme le conrme le test de Shapiro et la gure :4.3cependant poids4 ne peut être approchée par une loi normale.
Fig. 4.3 Transformation normale des poids suivi
1signie propensity score
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
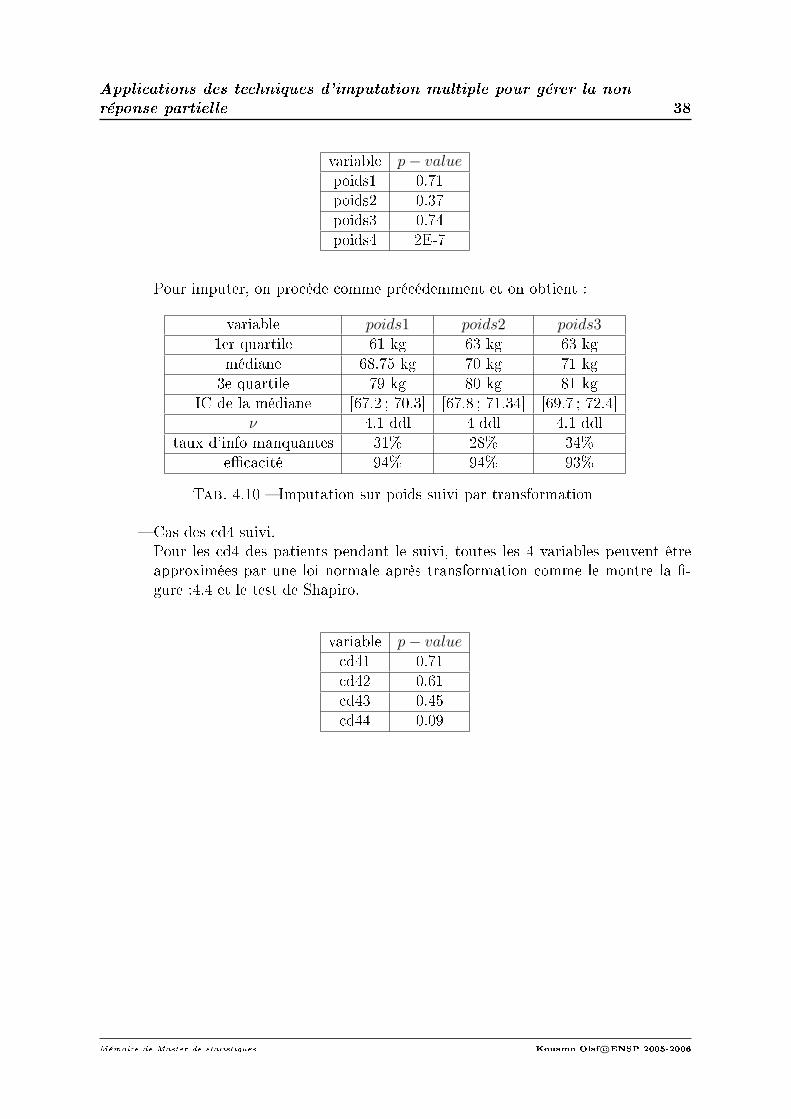
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 38
variable p− valuepoids1 0.71poids2 0.37poids3 0.74poids4 2E-7
Pour imputer, on procède comme précédemment et on obtient :
variable poids1 poids2 poids31er quartile 61 kg 63 kg 63 kgmédiane 68.75 kg 70 kg 71 kg3e quartile 79 kg 80 kg 81 kg
IC de la médiane [67.2 ; 70.3] [67.8 ; 71.34] [69.7 ; 72.4]ν 4.1 ddl 4 ddl 4.1 ddl
taux d'info manquantes 31% 28% 34%ecacité 94% 94% 93%
Tab. 4.10 Imputation sur poids suivi par transformation
Cas des cd4 suivi.Pour les cd4 des patients pendant le suivi, toutes les 4 variables peuvent êtreapproximées par une loi normale après transformation comme le montre la -gure :4.4 et le test de Shapiro.
variable p− valuecd41 0.71cd42 0.61cd43 0.45cd44 0.09
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
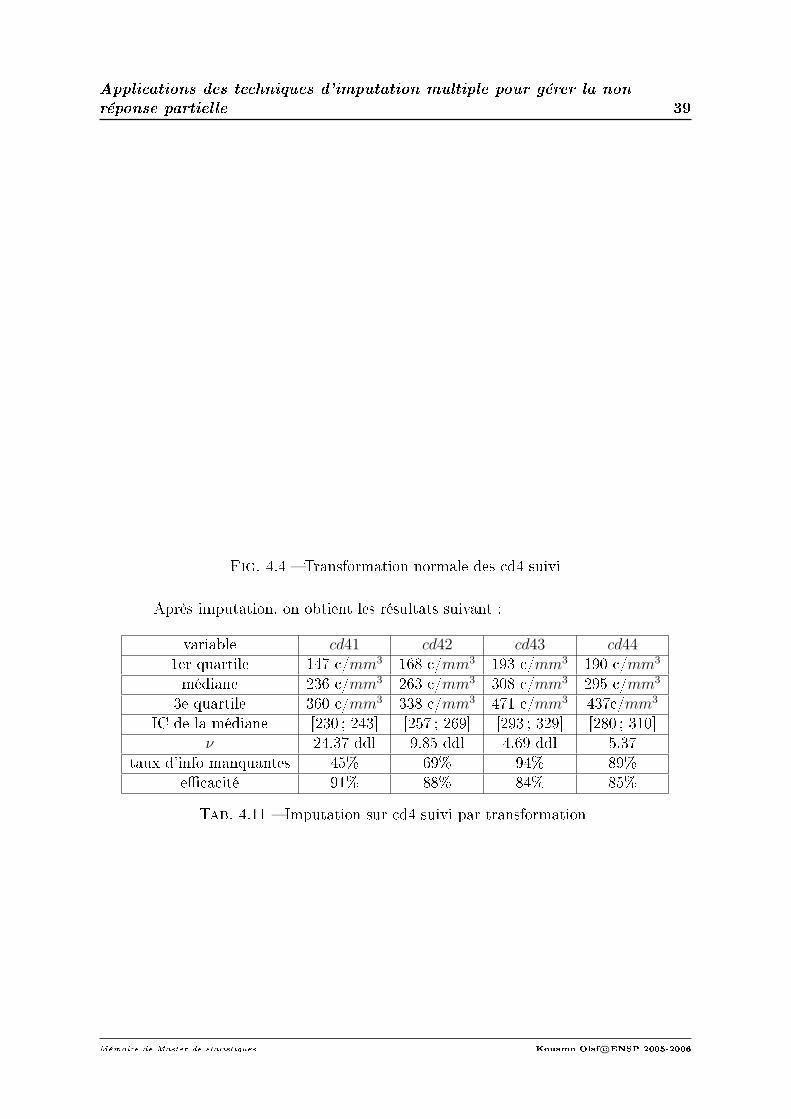
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 39
Fig. 4.4 Transformation normale des cd4 suivi
Après imputation, on obtient les résultats suivant :
variable cd41 cd42 cd43 cd441er quartile 147 c/mm3 168 c/mm3 193 c/mm3 190 c/mm3
médiane 236 c/mm3 263 c/mm3 308 c/mm3 295 c/mm3
3e quartile 360 c/mm3 338 c/mm3 471 c/mm3 437c/mm3
IC de la médiane [230 ; 243] [257 ; 269] [293 ; 329] [280 ; 310]ν 24.37 ddl 9.85 ddl 4.69 ddl 5.37
taux d'info manquantes 45% 69% 94% 89%ecacité 91% 88% 84% 85%
Tab. 4.11 Imputation sur cd4 suivi par transformation
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 40
Cas des cv suivi.Pour les cv l'approximation par une loi normale ne marche pas 4.5
Fig. 4.5 Transformation normale des cv suivi
3. Imputation sur les données n.Dans les données n, il n'y a que le poids qui peut être approximé par une loinormale p− value du test de shapiro après transformation 0.62 et la gure 4.6
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 41
Fig. 4.6 Transformation des données n
On retrouve également des valeurs qui ne sont pas signicativement diérentes decelles obtenus par ps.
Cependant, cette méthode présente quelques limites car elle n'utilise pas la cor-rélation entre les variables. La cv, même après transformation, ne suit pas unedistribution normale, donc il est impossible d'imputer sur cette variable par cetteméthode.
4.3 Application de la méthode k − nn
La méthode k − nn estime les valeurs manquantes dans un tableau de donnéesnumériques en se basant sur l'algorithme du kieme plus proche voisin. Cet algorithmeest implémenté dans le package EMV 2 du logiciel R. Dans le cas de l'imputation par laméthode k − nn, si un individu i a une donnée manquante pour une variable Vj,
2estimate missing value
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 42
On dénit une distance, en général la distance euclidienne dénie par :d : Rn × Rn → R
(X, Y ) 7→√
n∑i=1
(xi − yi)2
où X = (x1, . . . , xn) et Y = (y1, . . . , yn).
(4.3)
On calcule la distance entre la donnée manquante et ses k plus proches voisins ( enconsidérant la distance entre les valeurs réellement observées de l'individu i ayantune donnée manquante sur Vj et celles des autres individus ayant une observationsur Vj ).
On aecte à la valeur manquante la moyenne des valeurs observées chez ses k plusproches voisins [10].
Cette fonction s'utilise de la manière suivante knn(m, k, na.rm = T, correlation =F, dist.bound = F ) où :
m désigne la matrice numérique qui contient les valeurs manquantes qui serontestimées.
k désigne le nombre de voisins (nombre de lignes pour estimer les valeurs man-quantes).
na.rm est une valeur logique indiquant si la donnée manquante doit être estiméeou pas.
correlation est une valeur logique ; si elle est vraie, alors la sélection des voisins estbasée sur la corrélation entre les variables.
dist.bound est une limite pour les distances. Si la correlation est FALSE, l'al-gorithme utilisera uniquement les voisins pour lesquels la distance euclidienne estplus petite que la distance limite. Si la correlation est TRUE, l'algorithme utiliserauniquement les voisins pour lesquels la corrélation des variables de l'échantillonest plus grande que la distance limite. Si la distance limite est FALSE, tous lesvoisins sont utilisés.
1. Imputation sur les données d'inclusion.
variable poidsinc age cd4inc cvinc1er quartile 56 kg 32 ans 55 c/mm3 80958 c/mlmédiane 64 kg 39 ans 126 c/mm3 138000 c/ml3e quartile 72 kg 46 ans 204 c/mm3 200780 c/ml
IC de la médiane [63 ; 65] [38 ; 40] [119 ; 135] [123999 ; 152320]ν 4.0 ddl 4 ddl 418 ddl 40350 ddl
taux d'info manquantes 29% 28% 3.1% 77%ecacité 94% 94% 99% 86%
Tab. 4.12 Imputation sur les données d'inclusion par k-nn
Ici également, on retrouve des valeurs qui ne sont pas signicativement distinctes decelles obtenues par les méthodes précédentes (cf Tab.4.1 et 4.9) à l'exception de lavariable cv ; cette diérence est probablement due au taux de données manquantesélevé et à la dispersion dans cette variable.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 43
2. Imputation sur les données de suivi.Pour les données de suivi, en dehors de la variable poids1, toutes les autres variablescontiennent plus de 50% de données manquantes. Etant donné que cette méthodeimpute aux valeurs manquantes la moyenne des observations de ses k plus prochesvoisins, on aectera en général aux valeurs manquantes la moyenne des valeursobservées : pour les variables comme le poids où toutes les valeurs ont tendance àse regrouper autour de la moyenne, cette imputation est acceptable ; par contre,elle n'est pas appropriée pour les variables cd4 et surtout cv du fait de la dispersionde ces dernières.
3. Imputation sur les données n.
variable poidsfin cd4fin cvfin1er quartile 62 kg 167 c/mm3 19500 c/mlmédiane 68 kg 204 c/mm3 60810 c/ml3e quartile 76 kg 244 c/mm3 63310 c/ml
IC de la médiane [66 ; 70] [165 ; 242] [0 ; 122046]ν 48.22 ddl 4.18 ddl 4.12 ddl
taux d'info manquantes 86% 94% 94 %ecacité 79% 30% 29%
Tab. 4.13 Imputation sur les données n par knn
Conclusion :Le constat que l'on peut faire à l'issue de l'imputation par la méthode k − nn est quelorsqu'une variable ne possède pas beaucoup de données manquantes(moins de 20% desobservations), les résultats obtenus par k − nn ne sont pas signicativement diérentsde ceux obtenus par les 2 méthodes précédentes. Mais lorsque les valeurs manquantesdépassent les 50% des observations, la méthode k−nn a tendance à remplacer les valeursmanquantes par la moyenne des observations réelles.
4.4 Application de la méthode MCMC
Dans la méthode MCMC, les observations étant supposées suivre une loi multinor-male, pour appliquer cette méthode, nous avons transformé nos données par la fonctionde transformation de la section 4.2 an d'obtenir les valeurs qui approchent le mieuxchaque variable vers une loi normale ; ensuite grâce à la procédure proc MI ANALYSEde SAS version 8.1, nous avons imputer les valeurs manquantes ; enn on revient auxvraies valeurs par transformation inverse ; on obtient les résultats suivants :
1. Imputation sur les données d'inclusion.Par application de la méthode MCMC, on obtient les résultats suivants :
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 44
variable age poidsinc cd4inc cvinc1er quartile 32 ans 56 kg 52 c/mm3 34224 c/mlmédiane 39 ans 64 kg 123 c/mm3 108220 c/ml3e quartile 46 ans 72 kg 195 c/mm3 195000 c/ml
IC de la médiane [37.9 ; 39.9] [63 ; 65.1] [114 ; 132] [72256 ; 144181]ν 4.0 ddl 4.0 ddl 1190 ddl 39210 ddl
taux d'info manquantes 33% 32% 4 % 89%ecacité 93% 94% 96% 84%
Tab. 4.14 Imputation sur les données inclusion par MCMC
Les inférences obtenues ici ne sont pas signicativement diérents de celles obtenuspar les autres méthodes.
2. Imputation sur les données de suivi. Cas de la variable poidssuivi.
variable poids1 poids2 poids3 poids41er quartile 61 kg 63 kg 62 kg 64 kgmédiane 68.8 kg 70 kg 69.8 kg 71 kg3e quartile 78 kg 79 kg 80 kg 82 kg
IC de la médiane [67 ; 70.7] [68.4 ; 71.3] [68.2 ; 71.42] [68.8 ; 73.4]ν 4.78 ddl 4.36 ddl 4.51 ddl 8.44 ddl
taux d'info manquantes 48% 75% 55 % 80%ecacité 91% 86% 90% 86%
Tab. 4.15 Imputation sur les poids suivis par MCMC
Cas de la variable cd4suivi.
variable cd41 cd42 cd43 cd441er quartile 143 c/mm3 147 c/mm3 174 c/mm3 204 c/mm3
médiane 238 c/mm3 260 c/mm3 311 c/mm3 290 c/mm3
3e quartile 358 c/mm3 397 c/mm3 460 c/mm3 446 c/mm3
IC de la médiane [209 ; 267] [221 ; 298] [224 ; 395] [210 ; 383]ν 21.3 ddl 29 ddl 71.5 ddl 12 ddl
taux d'info manquantes 73% 84% 96 % 96%ecacité 83% 84% 84% 83%
Tab. 4.16 Imputation sur les cd4 suivis par MCMC
Cas de la variable cvsuivi.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 45
variable cv1 cv2 cv3 cv41er quartile 51 c/ml 52 c/ml 50 c/ml 78 c/mlmédiane 95 c/ml 77 c/ml 59 c/ml 438 c/ml3e quartile 299 c/ml 170 c/ml 170 c/ml 2510 c/ml
IC de la médiane [56 ; 135] [51 ; 102] [44 ; 75] [0 ; 1015]ν 156 ddl 55110 ddl 579 ddl 8.76 ddl
taux d'info manquantes 94% 95% 87% 96%ecacité 84% 84% 85% 83%
Tab. 4.17 Imputation sur les cv suivis par MCMC
Dans le cas des données suivi, les résultats obtenus pour les variables poids et cd4ne sont pas signicativement diérents des résultats précédents.
3. Imputation sur les données n
variable poidsfin cd4fin cvfin1er quartile 63 kg 80 c/mm3 446 c/mlmédiane 70 kg 185 c/mm3 21000 c/ml3e quartile 77 kg 352 c/mm3 50000 c/ml
IC de la médiane [47 ; 92] [104 ; 265] [0 ; 66035]ν 39 ddl 7.1 ddl 9.0
taux d'info manquantes 90% 83% 85%ecacité 97% 96% 85%
Tab. 4.18 Imputation sur les données n par MCMC
Ici également on retrouve des résultats qui ne sont pas signicativement diérentsde ceux obtenus par d'autres méthodes.
Conclusion
Au vu des résultats obtenus par cette méthode, on peut conclure que cette méthodeégalement est ecace lorsque la proportion des données manquantes n'est pas trop éle-vée ; de même, elle incorpore toute la variabilité due aux données manquantes car ellene diminue pas articiellement la variance.
Soulignons que dans les 4 méthodes d'imputations précédentes, on a supposé que lesdonnées manquantes étaient du type MAR. Compte tenu du fait que la non-réalisationdes examens biologiques chez certains patients est liée au fait que ces derniers ne dis-posent pas de moyens nanciers susants pour en acquerir, ou encore que certainspatients n'ont pas fait les examens de cv et cd4 à un moment donné sachant que lesrésultats seraient "mauvais" du fait d'une inobservance du traitement, ces données man-quantes peuvent être considérées, comme NMAR. Et, comme dans ce type de donnéesmanquantes le fait qu'une donnée manque sur une variable est lié à la variable elle même,une imputation par la moyenne ne serait pas erronée.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 46
4.5 Imputation par la moyenne
En imputant par la moyenne, on obtient les résultats suivants :
1. Données inclusion
variable age poidsinc cd4inc cvinc1er quartile 32 ans 56 kg 54 c/mm3 150700 c/mlmédiane 39 ans 64 kg 130 c/mm3 150700 c/ml3e quartile 46ans 72kg 197 c/mm3 150700 c/ml
IC de la médiane [38.41 ; 39.75] [63.59 ; 64.97] [119 ; 142]
Tab. 4.19 Imputation sur les données inclusion par la moyenne
2. Imputation sur les données de suivi. Cas de la variable poids.
variable poids1 poids2 poids3 poids41er quartile 63 kg 68 kg 73 kg 73 kgmédiane 70kg 71 kg 73 kg 73 kg3e quartile 75 kg 71 kg 73 kg 73 kg
IC de la médiane
Tab. 4.20 Imputation sur les poids suivis par la moyenne
Cas de la variable cd4 suivi.
variable cd41 cd42 cd43 cd441er quartile 267 c/mm3 291 c/mm3 335 c/mm3 336 c/mm3
médiane 267 c/mm3 291 c/mm3 335 c/mm3 336 c/mm3
3e quartile 267 c/mm3 291 c/mm3 335 c/mm3 336 c/mm3
IC de la médiane
Tab. 4.21 Imputation sur les cd4 suivis par la moyenne
Cas de la variable cv suivi.
variable cv1 cv2 cv3 cv41er quartile 24220 c/ml 15140 c/ml 26230 c/ml 50710 c/mlmédiane 24220 c/ml 15140c/ml 26230c/ml 50710 c/ml3e quartile 24220 c/ml 15140 c/ml 26230 c/ml 50710c/ml
IC de la médiane
Tab. 4.22 Imputation sur les cv suivis par la moyenne
3. Données n
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 47
variable poidsn cd4n cvn1er quartile 63 kg 269 c/mm3 44809 c/mlmédiane 70 kg 269 c/mm3 44809 c/ml3e quartile 75 kg 269 c/mm3 44809 c/ml
IC de la médiane
Tab. 4.23 Imputation sur les données n par la moyenne
L'inconvénient de remplacer les données manquantes par la moyenne des valeurs réel-lement observées est que la variance est réduite articiellement surtout lorque le tauxde données manquantes est élevé comme c'est le cas pour les données de suivi et de n.Par contre, pour les variables d'inclusion à l'exception de cvinc, on retrouve des valeursqui ne sont pas diérentes de celles obtenues par les autres méthodes. L'imputation parcette méthode aurait été beaucoup plus pertinente sur des variables comme la cv et lescd4 si les données manquantes n'étaient pas si abondantes dans ces variables.
4.6 Comparaison des méthodes d'imputation sur
les variables quantitatives
La qualité des imputations est fonction de diérents paramètres dont les plus impor-tants sont :
le nombre de données manquantes, la loi du vecteur aléatoire qui décrit le tableau de données, la distribution des valeurs manquantes.
Supposons que les données proviennent d'une loi multi normale de moyenne nulle et dematrice de variances covariances Σ et que les valeurs manquantes sont réparties selon uneloi uniforme. Pour évaluer et comparer les méthodes d'imputation en fonction du tauxde données manquantes, nous proposons la méthode comportant les étapes suivantes[5] :
Etape-1Par simulation, on génère un tableau T de n lignes (individus) et p colonnes(variables) représentant n réalisations du vecteur aléatoire X ∼ N(0, Σ) (N désignela loi normale). Nous avons choisi n = 100 pour obtenir un échantillon de taillesusante.
Etape-2On génère dans le tableau T un pourcentage xé pm de valeurs manquantes, dis-tribuées selon une loi uniforme.
Etape-3Les valeurs manquantes sont imputées en utilisant une technique quelconque. Ici,l'une des techniques décrites précédemment.
Etape-4Pour mesurer la précision de l'imputation, on calcule l'indice d'erreur quadratique
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 48
moyenne normalisé (Mean Square Error ou MSE) déni par :
MSE =1
n× p× pm
p∑j=1
[ n∑i=1
(xij − xij)2
n∑i=1
(xij − xij)2
],
où : pm représente le taux de valeurs manquantes. xij est l'imputation de xij si xij est manquante et xij = xij sinon.
xij = 1n
n∑i=1
xij moyenne de la variable Xj avant le tirage au sort
Dans l'expression de MSE, le terme entre crochets représente, pour une variable don-née, le rapport entre la somme des carrés des erreurs d'imputation et la variance de lavariable. On calcule alors la moyenne des écarts quadratiques en divisant par le nombrede données manquantes n×p×pm. An d'étudier le comportement de MSE en fonctiondu pourcentage des données manquantes, les étapes 1 à 4 sont répétées k fois, ceci pourchaque pourcentage pm.Comme dans les méthodes bootstrap, nous avons choisi k=1000.On obtient ainsi pour chaque pm une série de k observations de MSE pour laquelle oncalcule la moyenne et les quartiles.
Résultats des comparaisons
1. Par simulationConsidérons le vecteur aléatoire X distribué suivant une loi multi normale demoyenne nulle et de matrice de variances-covariances
Σ =
1 0 0 00 2 0 00 0 3 00 0 0 4
On obtient les résultats suivants : Méthode de la moyenne
pm 1er quartile médiane moyenne 3e quartile5% 0.008 0.0099 0.01 0.01215% 0.009 0.01 0.0102 0.012350% 0.01 0.0121 0.0121 0.0124
Méthode de transformation
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
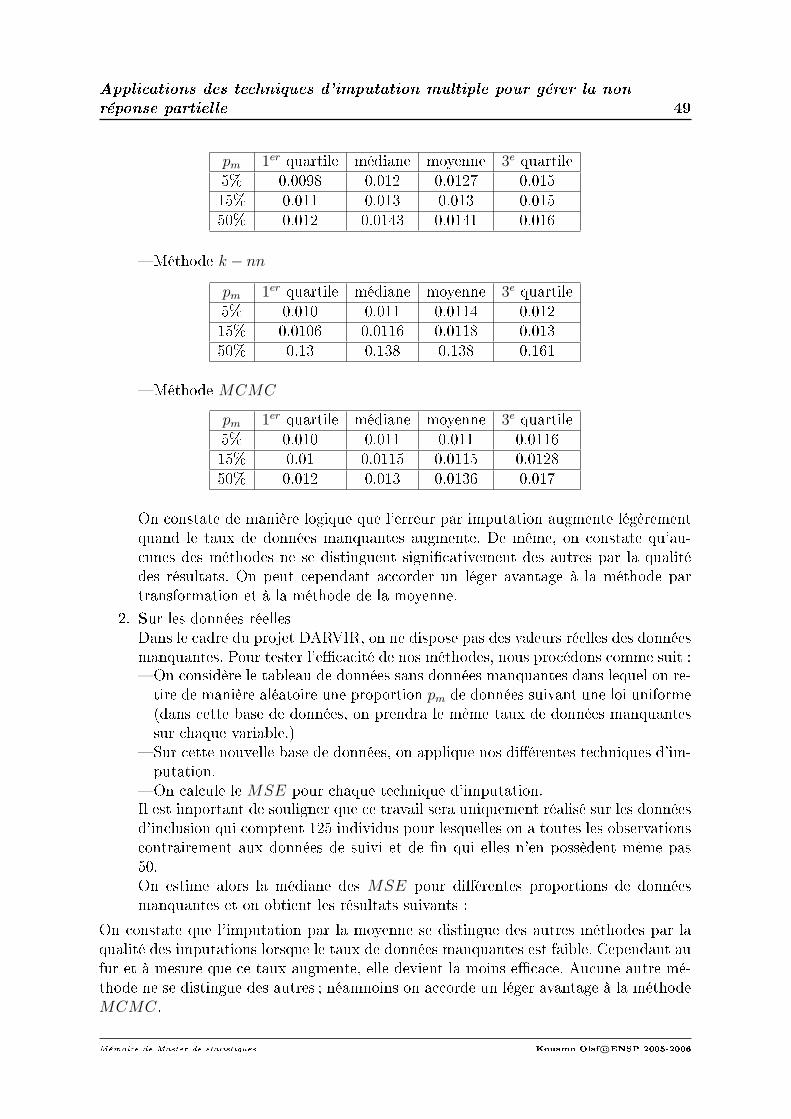
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 49
pm 1er quartile médiane moyenne 3e quartile5% 0.0098 0.012 0.0127 0.01515% 0.011 0.013 0.013 0.01550% 0.012 0.0143 0.0141 0.016
Méthode k − nn
pm 1er quartile médiane moyenne 3e quartile5% 0.010 0.011 0.0114 0.01215% 0.0106 0.0116 0.0118 0.01350% 0.13 0.138 0.138 0.161
Méthode MCMC
pm 1er quartile médiane moyenne 3e quartile5% 0.010 0.011 0.011 0.011615% 0.01 0.0115 0.0115 0.012850% 0.012 0.013 0.0136 0.017
On constate de manière logique que l'erreur par imputation augmente légèrementquand le taux de données manquantes augmente. De même, on constate qu'au-cunes des méthodes ne se distinguent signicativement des autres par la qualitédes résultats. On peut cependant accorder un léger avantage à la méthode partransformation et à la méthode de la moyenne.
2. Sur les données réellesDans le cadre du projet DARVIR, on ne dispose pas des valeurs réelles des donnéesmanquantes. Pour tester l'ecacité de nos méthodes, nous procédons comme suit : On considère le tableau de données sans données manquantes dans lequel on re-tire de manière aléatoire une proportion pm de données suivant une loi uniforme(dans cette base de données, on prendra le même taux de données manquantessur chaque variable.)
Sur cette nouvelle base de données, on applique nos diérentes techniques d'im-putation.
On calcule le MSE pour chaque technique d'imputation.Il est important de souligner que ce travail sera uniquement réalisé sur les donnéesd'inclusion qui comptent 125 individus pour lesquelles on a toutes les observationscontrairement aux données de suivi et de n qui elles n'en possèdent même pas50.On estime alors la médiane des MSE pour diérentes proportions de donnéesmanquantes et on obtient les résultats suivants :
On constate que l'imputation par la moyenne se distingue des autres méthodes par laqualité des imputations lorsque le taux de données manquantes est faible. Cependant aufur et à mesure que ce taux augmente, elle devient la moins ecace. Aucune autre mé-thode ne se distingue des autres ; néanmoins on accorde un léger avantage à la méthodeMCMC.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
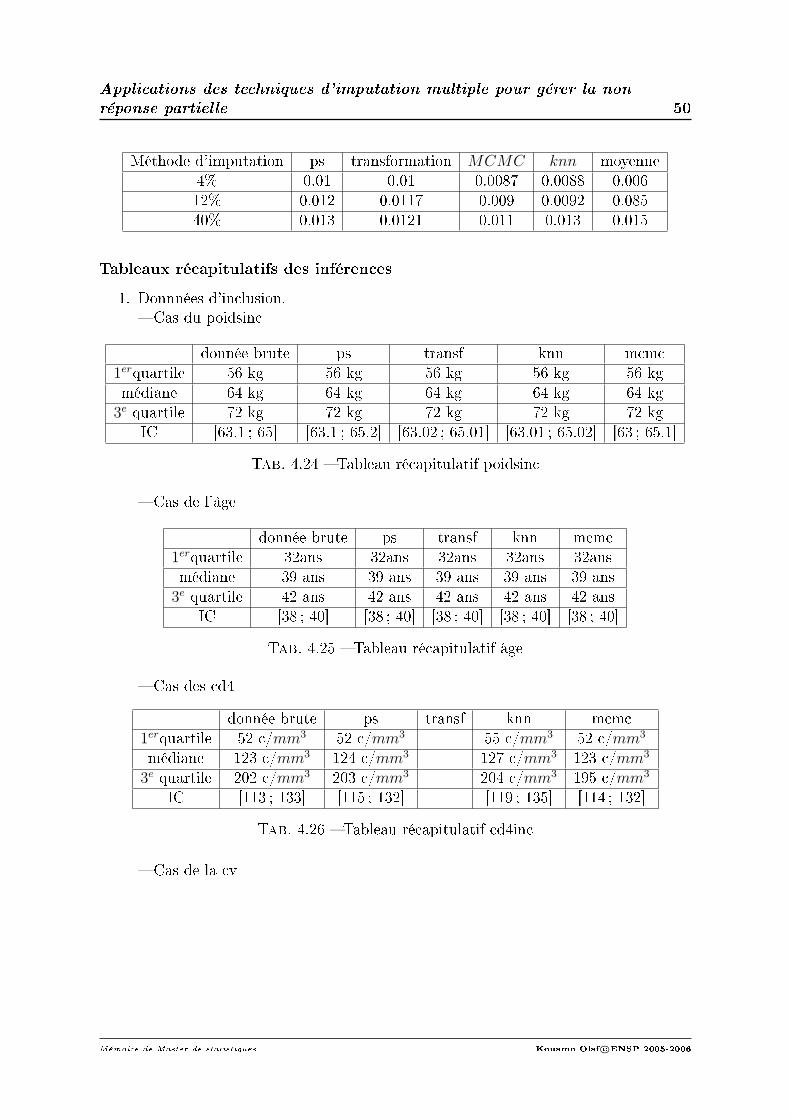
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 50
Méthode d'imputation ps transformation MCMC knn moyenne4% 0.01 0.01 0.0087 0.0088 0.00612% 0.012 0.0117 0.009 0.0092 0.08540% 0.013 0.0121 0.011 0.013 0.015
Tableaux récapitulatifs des inférences
1. Donnnées d'inclusion. Cas du poidsinc
donnée brute ps transf knn mcmc1erquartile 56 kg 56 kg 56 kg 56 kg 56 kgmédiane 64 kg 64 kg 64 kg 64 kg 64 kg
3e quartile 72 kg 72 kg 72 kg 72 kg 72 kgIC [63.1 ; 65] [63.1 ; 65.2] [63.02 ; 65.01] [63.01 ; 65.02] [63 ; 65.1]
Tab. 4.24 Tableau récapitulatif poidsinc
Cas de l'âge
donnée brute ps transf knn mcmc1erquartile 32ans 32ans 32ans 32ans 32ansmédiane 39 ans 39 ans 39 ans 39 ans 39 ans
3e quartile 42 ans 42 ans 42 ans 42 ans 42 ansIC [38 ; 40] [38 ; 40] [38 ; 40] [38 ; 40] [38 ; 40]
Tab. 4.25 Tableau récapitulatif âge
Cas des cd4
donnée brute ps transf knn mcmc1erquartile 52 c/mm3 52 c/mm3 55 c/mm3 52 c/mm3
médiane 123 c/mm3 124 c/mm3 127 c/mm3 123 c/mm3
3e quartile 202 c/mm3 203 c/mm3 204 c/mm3 195 c/mm3
IC [113 ; 133] [115 ; 132] [119 ; 135] [114 ; 132]
Tab. 4.26 Tableau récapitulatif cd4inc
Cas de la cv
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
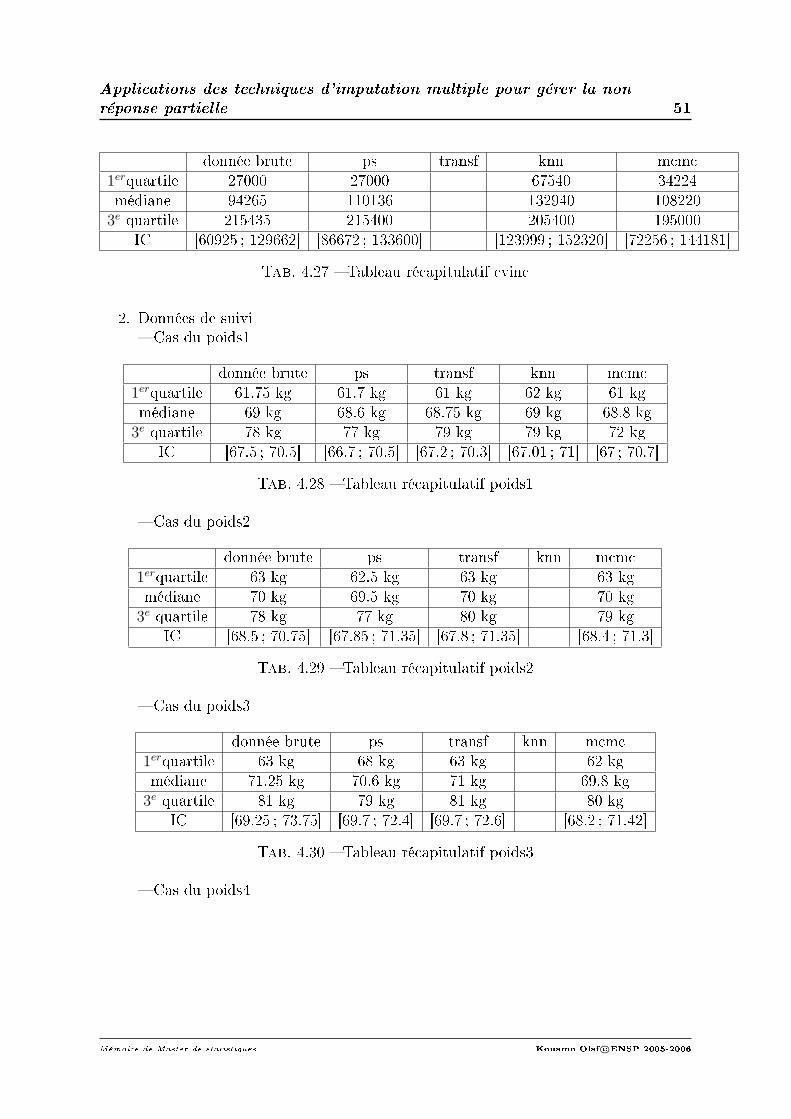
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 51
donnée brute ps transf knn mcmc1erquartile 27000 27000 67540 34224médiane 94265 110136 132940 108220
3e quartile 215435 215400 205400 195000IC [60925 ; 129662] [86672 ; 133600] [123999 ; 152320] [72256 ; 144181]
Tab. 4.27 Tableau récapitulatif cvinc
2. Données de suivi Cas du poids1
donnée brute ps transf knn mcmc1erquartile 61.75 kg 61.7 kg 61 kg 62 kg 61 kgmédiane 69 kg 68.6 kg 68.75 kg 69 kg 68.8 kg
3e quartile 78 kg 77 kg 79 kg 79 kg 72 kgIC [67.5 ; 70.5] [66.7 ; 70.5] [67.2 ; 70.3] [67.01 ; 71] [67 ; 70.7]
Tab. 4.28 Tableau récapitulatif poids1
Cas du poids2
donnée brute ps transf knn mcmc1erquartile 63 kg 62.5 kg 63 kg 63 kgmédiane 70 kg 69.5 kg 70 kg 70 kg
3e quartile 78 kg 77 kg 80 kg 79 kgIC [68.5 ; 70.75] [67.85 ; 71.35] [67.8 ; 71.35] [68.4 ; 71.3]
Tab. 4.29 Tableau récapitulatif poids2
Cas du poids3
donnée brute ps transf knn mcmc1erquartile 63 kg 68 kg 63 kg 62 kgmédiane 71.25 kg 70.6 kg 71 kg 69.8 kg
3e quartile 81 kg 79 kg 81 kg 80 kgIC [69.25 ; 73.75] [69.7 ; 72.4] [69.7 ; 72.6] [68.2 ; 71.42]
Tab. 4.30 Tableau récapitulatif poids3
Cas du poids4
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
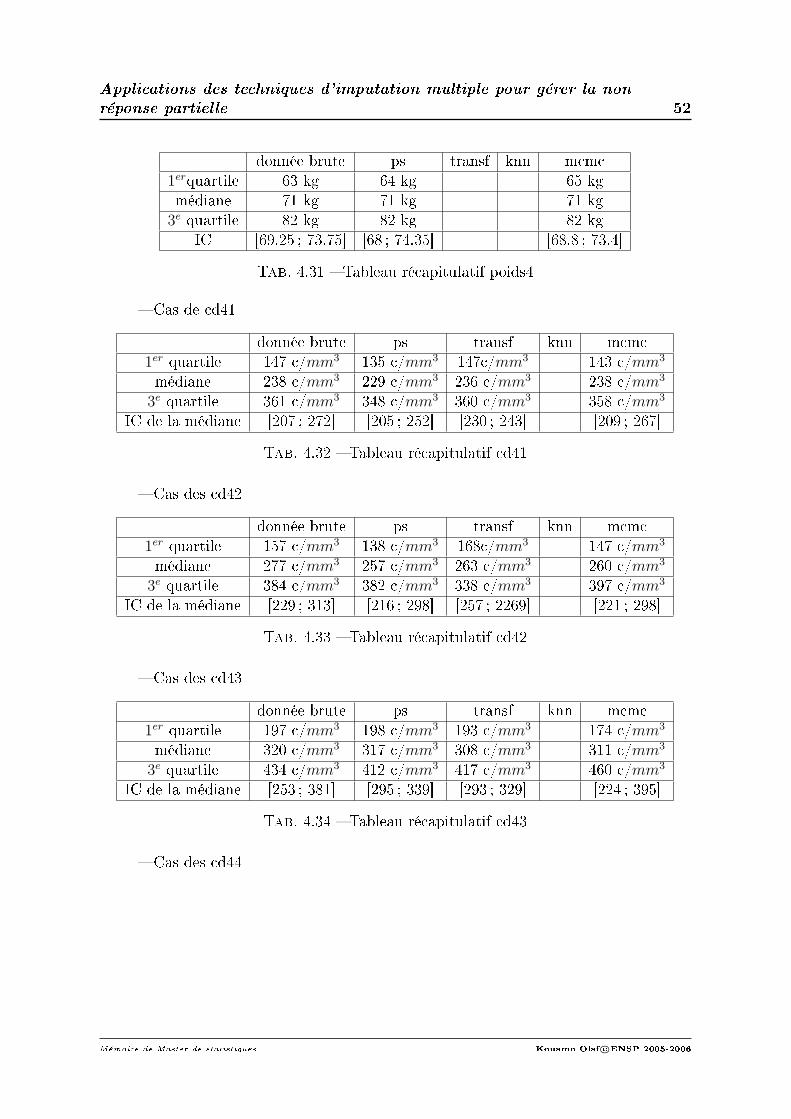
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 52
donnée brute ps transf knn mcmc1erquartile 63 kg 64 kg 65 kgmédiane 71 kg 71 kg 71 kg
3e quartile 82 kg 82 kg 82 kgIC [69.25 ; 73.75] [68 ; 74.35] [68.8 ; 73.4]
Tab. 4.31 Tableau récapitulatif poids4
Cas de cd41
donnée brute ps transf knn mcmc1er quartile 147 c/mm3 135 c/mm3 147c/mm3 143 c/mm3
médiane 238 c/mm3 229 c/mm3 236 c/mm3 238 c/mm3
3e quartile 361 c/mm3 348 c/mm3 360 c/mm3 358 c/mm3
IC de la médiane [207 ; 272] [205 ; 252] [230 ; 243] [209 ; 267]
Tab. 4.32 Tableau récapitulatif cd41
Cas des cd42
donnée brute ps transf knn mcmc1er quartile 157 c/mm3 138 c/mm3 168c/mm3 147 c/mm3
médiane 277 c/mm3 257 c/mm3 263 c/mm3 260 c/mm3
3e quartile 384 c/mm3 382 c/mm3 338 c/mm3 397 c/mm3
IC de la médiane [229 ; 313] [216 ; 298] [257 ; 2269] [221 ; 298]
Tab. 4.33 Tableau récapitulatif cd42
Cas des cd43
donnée brute ps transf knn mcmc1er quartile 197 c/mm3 198 c/mm3 193 c/mm3 174 c/mm3
médiane 320 c/mm3 317 c/mm3 308 c/mm3 311 c/mm3
3e quartile 434 c/mm3 412 c/mm3 417 c/mm3 460 c/mm3
IC de la médiane [253 ; 381] [295 ; 339] [293 ; 329] [224 ; 395]
Tab. 4.34 Tableau récapitulatif cd43
Cas des cd44
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
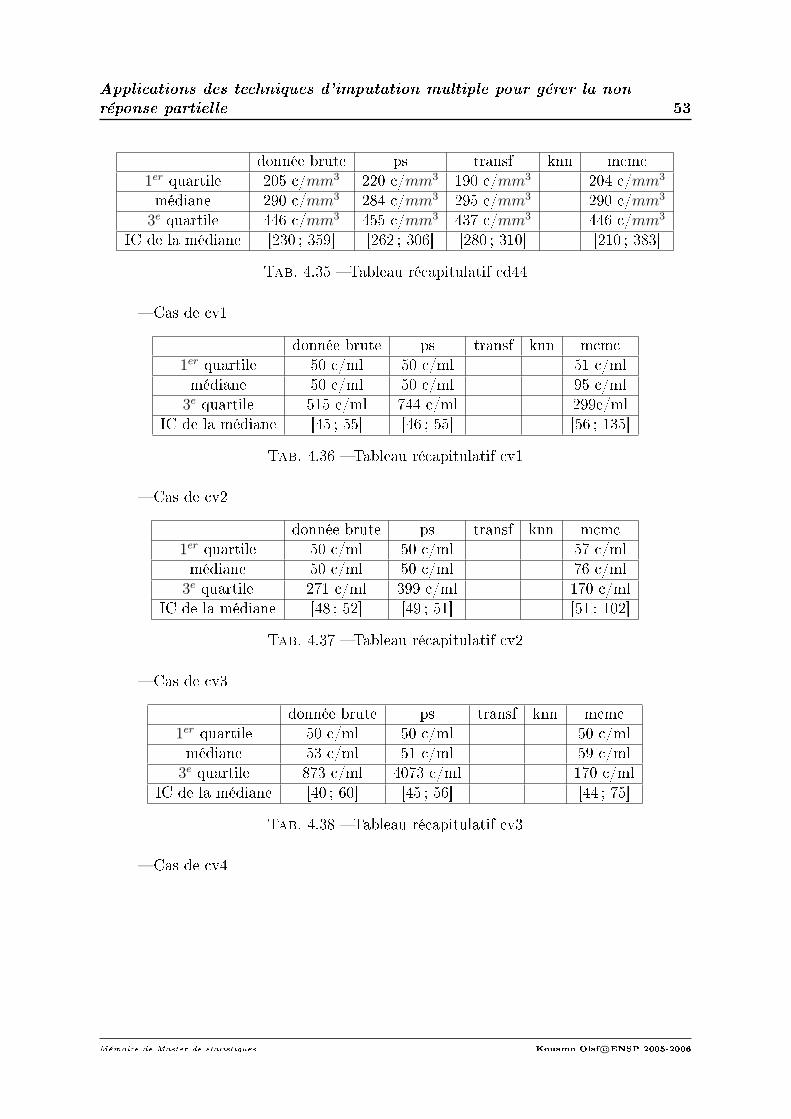
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 53
donnée brute ps transf knn mcmc1er quartile 205 c/mm3 220 c/mm3 190 c/mm3 204 c/mm3
médiane 290 c/mm3 284 c/mm3 295 c/mm3 290 c/mm3
3e quartile 446 c/mm3 455 c/mm3 437 c/mm3 446 c/mm3
IC de la médiane [230 ; 359] [262 ; 306] [280 ; 310] [210 ; 383]
Tab. 4.35 Tableau récapitulatif cd44
Cas de cv1
donnée brute ps transf knn mcmc1er quartile 50 c/ml 50 c/ml 51 c/mlmédiane 50 c/ml 50 c/ml 95 c/ml
3e quartile 515 c/ml 744 c/ml 299c/mlIC de la médiane [45 ; 55] [46 ; 55] [56 ; 135]
Tab. 4.36 Tableau récapitulatif cv1
Cas de cv2
donnée brute ps transf knn mcmc1er quartile 50 c/ml 50 c/ml 57 c/mlmédiane 50 c/ml 50 c/ml 76 c/ml
3e quartile 271 c/ml 399 c/ml 170 c/mlIC de la médiane [48 ; 52] [49 ; 51] [51 ; 102]
Tab. 4.37 Tableau récapitulatif cv2
Cas de cv3
donnée brute ps transf knn mcmc1er quartile 50 c/ml 50 c/ml 50 c/mlmédiane 53 c/ml 51 c/ml 59 c/ml
3e quartile 873 c/ml 4073 c/ml 170 c/mlIC de la médiane [40 ; 60] [45 ; 56] [44 ; 75]
Tab. 4.38 Tableau récapitulatif cv3
Cas de cv4
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006
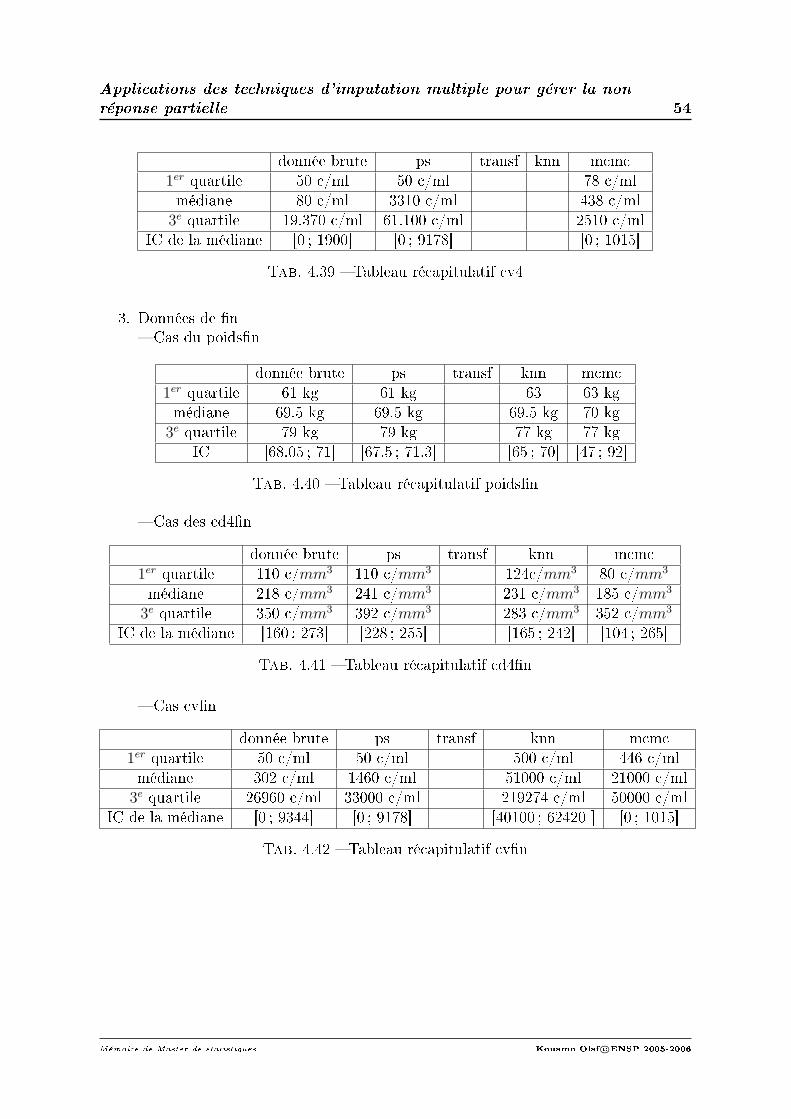
Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 54
donnée brute ps transf knn mcmc1er quartile 50 c/ml 50 c/ml 78 c/mlmédiane 80 c/ml 3310 c/ml 438 c/ml
3e quartile 19.370 c/ml 61.100 c/ml 2510 c/mlIC de la médiane [0 ; 1900] [0 ; 9178] [0 ; 1015]
Tab. 4.39 Tableau récapitulatif cv4
3. Données de n Cas du poidsn
donnée brute ps transf knn mcmc1er quartile 61 kg 61 kg 63 63 kgmédiane 69.5 kg 69.5 kg 69.5 kg 70 kg
3e quartile 79 kg 79 kg 77 kg 77 kgIC [68.05 ; 71] [67.5 ; 71.3] [65 ; 70] [47 ; 92]
Tab. 4.40 Tableau récapitulatif poidsn
Cas des cd4n
donnée brute ps transf knn mcmc1er quartile 110 c/mm3 110 c/mm3 124c/mm3 80 c/mm3
médiane 218 c/mm3 241 c/mm3 231 c/mm3 185 c/mm3
3e quartile 350 c/mm3 392 c/mm3 283 c/mm3 352 c/mm3
IC de la médiane [160 ; 273] [228 ; 255] [165 ; 242] [104 ; 265]
Tab. 4.41 Tableau récapitulatif cd4n
Cas cvn
donnée brute ps transf knn mcmc1er quartile 50 c/ml 50 c/ml 500 c/ml 446 c/mlmédiane 302 c/ml 1460 c/ml 51000 c/ml 21000 c/ml
3e quartile 26960 c/ml 33000 c/ml 219274 c/ml 50000 c/mlIC de la médiane [0 ; 9344] [0 ; 9178] [40100 ; 62420 ] [0 ; 1015]
Tab. 4.42 Tableau récapitulatif cvn
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Chapitre Cinq
Analyse de survie du projet DARVIR
L'analyse de survie est née en Angleterre au 17eme siècle dans le domaine de ladémographie. Le but était d'estimer la variation des caractéristiques des populations(taille de la population, moyenne des temps de survie, etc . . . ) à partir d'une table devie. Ces analyses sont devenues beaucoup plus précises au 19eme siècle quand les tablesde vie étaient catégorisées en utilisant les variables exogènes telles que : le sexe, le statutsocial etc... Pendant le 20eme siècle, l'analyse de survie apparaît dans d'autres domainesde recherche tels que :
la abilité : Weibull (1951), la médécine et la santé.
5.1 Outils probabilistes pour l'analyse de survi
Toutes les notions présentées dans cette partie se trouvent dans [11]. On note T , unedurée de vie aléatoire caractérisée par sa densité fT et de fonction de répartition
F = P(T ≤ t)
=∫ t
0fT (u)du.
On dénit également "la fonction de survie" par ST (t) = P(T > t), encore appelée"fonction de abilité".
a- Fonction de risque instantanée.Elle est notée λT (t) et est dénie par :
λT (t) = limdt→0
P (t < T < t + dt/T > t)
dt.
qui est la probabilité instantanée de survenue de l'évènement juste après t sachantque cet évènement n'était pas encore survenu avant t. On montre que :
λT (t) =fT (t)
ST (t)
= −S ′T (t)
ST (t)
= −log(ST (t)
)′Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Analyse de survie du projet DARVIR 56
d'où
ST (t) = exp(−∫ t
0
λT (u)du)
Le choix du modèle est guidé par cette fonction de risque instantanée.b- Fonction de risque cumulée.Elle est noté ΛT et est donnée par ΛT (t) =
∫ t
0λT (t)dt. Cette fonction mesure
l'accumulation du risque instantané au cours du temps.On censure lorsqu'un patient abandonne l'étude, ou lorsque ce dernier n'a toujours pasobservé l'évènement d'intérêt à la n de l'étude. On la note Ci, et Ti représente la duréejusqu'à l'évènement d'intérêt. On connait la nature de l'observation :
Censure : min(Ci, Ti) = Ci, Non censure : min(Ci, Ti) = Ti.
La nature censurée ou non est connue et on la code1 si Ti ≤ Ci
0 si Ti > Ci
On représente une durée par un couple (Xi, ∆i) où Xi = min(Ti, Ci) et ∆i = 1|(Ti,Ci).
5.1.1 Estimation non paramétrique
Estimateur de Kaplan Meier
Considérons X1, . . . , Xn n réalistions d'une variable aléatoire X de loi inconnue L(X)et de fonction de répartition FX(x). L'objectif est d'estimer FX . La fonction de répar-
tition empirique de X est Fn(x) =1
n
n∑i=1
1|(Xi≤x) et la fonction de survie empirique est
Sn(x) =1
n
n∑i=1
1|(Xi>x) Un estimateur de la fonction de survie vérie l'équation (5.1) :
Sn(x) =1
n
[ n∑i=1
1|(Xi>x) +n∑
i=1
1|(Xi≤x)(1−∆i)Sn(x)
Sn(Xi)
](5.1)
où le second membre de l'addition désigne les individus censurés avant x et mort aprèsx. On montre que la solution unique de cet équation est :
Sn(x) =∏
Xi≤x∆i=1
(1− 1∑n
j=1 1|(Xj≥Xi)
)(5.2)
appelé estimateur de Kaplan-Meier ; qui représente le produit des probabilités de sur-vivre en chacun des instants de décès observés avant x.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Analyse de survie du projet DARVIR 57
Estimateur de Nelson Aalen
Un estimateur de la fonction de risque cumulée est l'estimateur de Nelson Aalennoté :
Λ(t) =∑ti<t
∆N(t)
Y (t),
ou
Λ(t) =
∫ t
0
dN(s)
Y (s)1|(Y (s)>0).
où les ti sont les instants distincts de décès avant t, Y (t) le nombre d'individu à risqueen ti et ∆N(t) la variation du nombre de décès entre t et t + ∆t.
Test du log- rank :Il est utilisé pour tester l'égalité des distributions dans des échantillons de données
censurées. H0 : λ1 = λ2 = . . . = λk
H1 : ∃i, j tel que λi 6= λj.
On décrit le test pour le cas ou on a juste 2 groupes (k = 2).Posons
Ui =L∑
k=1
∆N1(tk)−∆N(tk)
Y (tk)Yi(tk)
où ∆N1(tk) représente le nombre de décès observés dans le groupe i en tk et∆N(tk)
Y (tk)Yi(tk)
le nombre de décès attendu sous H0 dans le groupe i en tk. La statistique de test est :
X =Ui√V (Ui)
L→ N(0, 1) sous H0.
Remarque 5.1.1. Pour i = 1, . . . , k, la statistique de test est :
X2 = (U1, U2, . . . , Uk−1)Σ−1(U1, U2, . . . , Uk−1)
T ∼ χ2(k − 1)
5.1.2 Quelques exemples de modèles
Modèle de Weibull
Proposition 5.1.1. Soit X une variable aléatoire de loi de Weibull W (α, λ). Soit Y =
log(X). On pose σ =1
αet µ = −σlnλ alors ∀y ∈ R la fonction de survi de la loi de
Weibull est donnée par :
SY (y) = exp(− exp
(y − µ
σ
))
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Analyse de survie du projet DARVIR 58
Pour la preuve voir [11].En posant
U =Y − µ
σon en déduit que
SU(u) = e−eu
On dit que U suit une loi de Gumbel(on rappelle que U suit une loi de Gumbel si sa
densité par rapport à la mesure de lebesgue estfU(u) = exp(u− eu).Finalement, si X suit W (α, λ), on peut écrire que :
Y = lnx = µ + σU (5.3)
où U suit une Gumbel.On dénit ainsi un modèle de régression paramétrique en posant µ(Z) = µ + γT Z dans(5.3) et on obtient
Y = lnX = µ + γT Z + σU (5.4)
L'équation (5.4) induit alors la fonction de risque instantanée
λ(X/Z) = αλxα−1eβT Z .
Le rapportλX/Z(x/z1)
λX/Z(x/z2)= eβ(z1−z2)
D'ou le risque d'un individu est proportionnel à celui d'un autre.En pratique, on n'interprète pas β mais plutôt eβ. En général,
λX/Z(x/Z = z)
λX/Z(x/Z = z + 1)= eβ
et s'interprète par :Lorsque l'on augmente la covariable d'une unité, le risque de décès (d'apparition de
l'évènement d'intérêt). augmente de eβ si eβ > 1 diminue de eβ si eβ < 1
Modèle semi-paramétrique de Cox
Le modèle proportionnel de Cox est devenu la procédure la plus utilisée dans lamodélisation de la relation entre covariables dans une analyse de survie. Ce modèlen'est ni paramétrique ni non paramétrique (il est appelé modèle semi-paramétrique).
Considérons les variables aléatoires T : instant de décès ( d'apparition de l'évènementd'intérêt ), C : censure, X = TΛC et ∆ = 1|T<C Z ∈ Rp est le vecteur des covariables(qualitatives ou quantitatives).
L'objectif est d'étudier la distribution de la durée conditionellement aux covariables.Le modèle est :
λ(t/Z) = λ0(t)eβT Z .
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Analyse de survie du projet DARVIR 59
β est le vecteur de paramètres d'intérêt. Z est le vecteur de covariables. λ0 : est le paramètre de nuisance qui est une fonction positive inconnue qu'on necherchera pas à spécier.
Remarque 5.1.2. Ce modèle est également qualié de modèle à risque proportionnelcar le ratio des fonctions de risque pour 2 sujets avec des vecteurs de covariables xésZi et Zj est
λ0(t)eβT Zi
λ0(t)eβT Zj= eβ(Zi−Zj)
qui est une constante. Les paramètres βk représente l'eet de chaque covariable sur lasurvie.
Inférence basée sur la vraisemblance partielle.On dispose d'un échantillon (Xi, ∆i, Zi) ; la vraisemblance est donnée par :
L(β, λ0(.)
)=
n∏i=1
λT/Z(Xi/Zi)
∆e−
R yi0 λT/Z(u/Zi)du
=n∏
i=1
λ0(Xi)
∆ieβZi∆ie−Λ0(Xi)eβZi
on ne peut pas maximiser cette vraisemblance d'où la méthode proposée par Cox.Méthode du maximum de vraisemblance partielle.
On maximise la vraisemblance de β uniquement.
L(β) =n∏
i=1
(eβZi∑n
i=1 eβZj1|Xi≤Xj
)∆i
(5.5)
L'équation (5.5) est l'estimation du maximum de vraisemblance partielle. La probabilitépour que ce soit l'individu i qui décède à l'instant Xi sachant qu'un décès se produit etconnaissant l'ensemble des individus à risque en Xi est :
eβZi∑ni=1 eβZj1|Xi≤Xj
.
5.2 Application des modèles de survie au projet
DARVIR
Dans le cadre de l'analyse de survie de ce projet, on aurait pu étudier l'ecacitédu traitement antirétroviral en considérant par exemple comme évènement d'intérêt "lefait que la cv d'un patient soit < 50 copies/ml" à un moment donnée de l'étude, maisl'abondance des valeurs manquantes principalement dans cette variable (quasiment 3/4
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Analyse de survie du projet DARVIR 60
des données étaient inobservées) montre qu'une telle étude ne serait pas pertinente ;par conséquent les résultats qui en découleraient seraient erronés. De même étudieruniquement le décès ne serait pas approprié non plus : de nombreux patients perdus devue étaient probablement décédés ; mais en l'absence de recherche active des perdus devue, cette information n'était pas connue. Il serait donc préférable de considérer commeévènement d'intérèt les personnes décedées ou perdues de vue. Ainsi, toute personneencore suivie à la n de l'étude sera censurée et toute personne décedée ou perdue devue comme ayant observé l'évènement d'intérèt.
On obtient ainsi les résultats suivant :La probabilité de continuer le traitement après 12 mois est de 0.76 (IC = [0.73; 0.79])
et elle est de 0.60 (IC = [0.55; 0.65]) après 28 mois comme le montre la courbe deKaplan-Meier g 5.1
Fig. 5.1 Courbe de survie de Kaplan-Meier
Eet du stade cdc la survie.
Considérons les 3 stades d'évolution du VIH. Lorsque l'on modélise la survie enfonction du stade, le test du log-rank nous donne une p − value = 0.00015 ; alors ilexiste au moins un groupe qui dière des autres (la fonction de risque cumulée n'est pasla même à tous les stades). En d'autres termes, la probabilité de continuer le traitementdépend du stade cf g 5.2. De même, le test du rapport de vraisemblance nous donne17.6 > χ2(2) = 5.99 alors on rejette l'hypothèse de nullité des β. Ce qui conrme que lala probabilité de continuer le traitement dépend du stade CDC.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Analyse de survie du projet DARVIR 61
Fig. 5.2 Courbe de survie en fonction du stade.
Prenons le stade C comme stade de reférence et considérons le modèle de Weibullλ(t/Z) = λ0(t)e
β1Z1+β2Z2 en construisant le modèle de régression grâce à la fonction
survreg de R, on obtient les paramètres suivants : λ(t/stadeA)λ(t/stadeC)
= 0.32 alors la probabilité
γ1 γ2 eβ1 eβ2
1.399 0.39 0.32 0.73
de continuer le traitement est environ 3 fois plus grande lorsque le patient est au stade Apar rapport au stade C. Par contre, elle ne dière pas signicativement entre un patientclassé stade B et un patient classé stade C.
En refaisant la même analyse avec le modèle de Cox, on trouve des valeurs sensible-ment égales aux précédentes.
Considérons maintenant le modèle de Cox : λ(t/Z) = λ0(t)eβ1Z1+β2Z2+β3age et tes-
tons : H0 : β1 = β2 = β3 = 0H1 : ∃ au moins un βi 6= 0
Le test du rapport de vraisemblance nous donne 19.7 > χ2(2) = 5.99, alors on rejettel'hypothèse de nullité des β. A âge égal, il existe une diérence signicative entre lesstades ; mais il n'ya pas eet de l'âge sur la survie.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Conclusion
Le but de notre étude était de gérer la non réponse partielle apparaissant dans lecadre du projet "DARVIR" an d'obtenir des bases de données complètes. Pour ce fairenous avons utilisé 4 méthodes d'imputations multiples. La méthode de propensity score,la méthode de transformation vers une loi normale, la méthode "k-nn" et la méthodeMCMC grâce à la procédure "MI ANALYSE" du logiciel SAS version8.1. Ces méthodesprésentent l' avantage d'être adaptées aux cas de données manquantes de type MARet de pouvoir être utilisées par des logiciels classiques. Toutes ces méthodes ont étécomparées sur notre jeu de données, mais aucune ne se distingue signiticativement desautres par la qualité des résultats. L'un des avantages de la procédure MI ANALYSE deSAS est qu'elle est rapide, simple d'utilisation et qu'elle ne diminue pas articiellementla variance. On peut cependant lui reprocher d'agir comme une "boîte noire" à partirdes modèles probabilistes basés sur les méthodes de MONTE CARLO et les chaînesde markov. La méthode de propensity score, elle, est adaptée tant pour les variablesquantitatives que pour les variables qualitatives et a pour avantage de préserver lesaspects importants des distributions ; cependant une imputation par cette méthode peutfausser les corrélations avec d'autres variables ; en outre, la structure monotone quisoutend les conditions d'application de cette méthode n'est pas vériée.
Un des très grands problèmes de notre base de données est le fait que les donnéesmanquantes représentent la plupart du temps plus de 50% des données. Sur cette base,il est très dicile de trouver des méthodes d'imputation ecaces. Alors les autorités desanté locales, dans le cadre de la lutte contre le sida, devraient mettre tout en ÷uvre pouréviter à l'avenir d'avoir dans des suivis médicaux quotidiens tant de données manquantes.Ceci passe par exemple par :
La réduction du coût des examens biologiques, du coût des tests pré-thérapeutiqueset même du coût des médicaments antirétroviraux.
Une plus grande implication de tout le personnel de santé (les médecins n'étantpas toujours disponibles, les inrmiers(es) peuvent prendre la relève lorsque cesderniers sont absents.).
Enn la diversication des pôles d'acquisition des ARV (pour le projet DARVIRpar exemple,on ne disposait que d'un seul point de vente des ARV ce qui crée unproblème d'anonymat.)
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Chapitre ANNEXE
ANNEXE
6.1 Densités des lois de probabilités utilisées
Soit Ω une population (un ensemble) et X un caractère réel dans cette population.
La loi normale
On dit que X suit une loi normale de paramètres µ et σ2 si sa densité par rapport àla mesure de Lebesgue sur R est
f(x) =1√
2πσ2e−
1
2σ2(x−µ)2
, ∀x ∈ R.
Si µ = 0 et σ2 = 1 , on dit que X suit une loi normale centrée reduite. Les paramètresµ et σ représentent respectivement la moyenne et l'écart type.
La loi log-normale
On dit que X suit une loi log-normale de paramètres µ et σ2 si log(X) suit une loinormale ; sa densité par rapport à la mesure de Lebesgue sur R est
f(x) =
1√
2πσ2x2e−
1
2σ2(log(x)−µ)2
si x > 0
0 sinon
La moyenne de X est E(X) = e(µ+
σ2
2)et sa variance est var(X) = e2µ+2σ2−1
La loi de Weibull
On dit que X suit une loi de Weibull de paramètres θ et α si sa densité par rapportà la mesure de R est
f(x) =
αθxα−1e−θxα
si x > 00 sinon
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

ANNEXE 64
6.2 Estimation
On suppose que la loi de X, PX , appartient à une famille de loi (Pθ)θ ∈ Θ avec Θ
ouvert de Rp, p ∈ N∗ et ∀x ∈ R, fθ(x) =dpθ
dx(x) connue ∀θ ; (fθ)θ∈Θ est la famille des
densités (par rapport à la mesure de lebesgue sur Rp) possible de PX .Si on a observé X1 = x1, X2 = x2, . . ., Xn = xn, n ∈ N∗, on note X = x, X =(X1, . . . , Xn) et x = (x1, . . . , xn)
Dénition 6.2.1. Sous les hypothèses ci-dessus, on dit que (X, (Pθ)θ∈Θ) est un modèleparamétrique de paramètre θ dominé par la mesure de Lebesgue sur R, de famille dedensités (fθ)θ∈Θ.
Dénition 6.2.2. On dit que (X, (Pθ)θ∈Θ) est un modèle regulier si :
1. ∀θ ∈ Θ, x ∈ Rn/fθ(x) > 0 = D,
2. ∀x ∈ D, l'application θ → fθ(x) est de classe C2 sur Θ,
3. ∀θ ∈ Θ, E[ ∂
∂θi
(logfθ(X)
)]2< +∞, i = 1, . . . , p,
4. ∀θ ∈ Θ, E[ ∂
∂θi∂θj
(logfθ(X)
)]2< +∞ i, j = 1, . . . , p
5. ∀θ ∈ Θ,∂
∂θi
∫D
fθ(x)dx =∫
D
∂
∂θi
fθ(x)dx, i = 1, . . . , p
6. ∀θ ∈ Θ,∂
∂θi∂θj
∫D
fθ(x)dx =∫
D
∂
∂θi∂θj
fθ(x)dx, i, j = 1, . . . , p
Pour θ0 ∈ Θ, on pose :
I(θ0) = E[(
~∇logfθ(x))T (~∇logfθ(x)
)]θ=θ0
= −E[Hlogfθ(X)
]θ=θ0
, avec ~∇ =( ∂
∂θi
)i∈I
et H =( ∂2
∂θi∂θj
)i∈I j∈I
où I = 1, . . . , p
Dénition 6.2.3. ∀θ ∈ Θ, I(θ0) > 0 est applelée information de Fisher ou matriced'information de Fisher (si p>1) pour la valeur θ0 du paramètre θ dans la famille.
Remarque 6.2.1. Lorsque p > 1, I(θ) est une matrice carrée d'ordre p. Dire qu'elleest ≥ 0 signie qu'elle est semi-dénie positive.
Dénition 6.2.4. L'estimation par maximum de vraisemblance du paramètre inconnuθ est le réel θn ∈ Θ vériant ;
fθn(x) = Sup
θ∈Θfθ(x) s'il existe
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

ANNEXE 65
Théorème 6.2.1. Si (Pθ)θ∈Θ est un modèle exponentiel 1 de paramètre naturel θ, alorssi, θ0 est la vraie valeur du paramètre θ, on a :
1. ∀(θn
)n∈N∗, suite d'estimateurs du maximum de θ, on a :
θnp→ θ0, qd n → +∞.
2. √n(θn − θ0
) L→ N(~0, I(θ0)
−1).
6.3 Codes R des fonctions utilisées
#fonction qui remplace les na par 1 et les valeurs non manquantes par 0por<-function(mat) v<-mat[,ncol(mat)]for(i in 1 :nrow(mat))if(is.na(v[i]))v[i]<-1elsev[i]<-0 mat1<-data.frame(mat,v)mat1#fonction qui impute les valeurs manquantes dans une variable par psmat0=data.frame(z=data$ident,a=data$centre,b=data$sexe,c=data$arvinc, e=data$nvisites,f=data$cd4d,g=data$cvd,p=data$stadeinc)estim0<-function(mat0)mat<-por(mat0)reg1<-step(glm(mat$v∼mat$a+ mat$b+mat$c+mat$e+mat$f+mat$g,family=binomial)val<-round(tted.values(reg1),digits=2))datta<-data.frame(mat,val=val)dat1<-datta[order(datta$val),]dat11<-dat1[dat1$val<=0.03,]dat12<-dat1[dat1$val>0.03,]# je m'interesse au 1er tableauq1<-dat11$pq1sna<-q1[ !is.na(q1)]q1sna<-sample(q1sna,length(q1),replace=T)q1na<-sample(q1sna,length(q1[is.na(q1)]),replace=T)dat11$p[is.na(dat11$p)]<-q1na
1Un modèle dominé est dit exponentiel lorsque ∀θ ∈ Θ, ∀x ∈ Rn, fθ(x) = e≺θ,T (X)−φ(θ) où T(X)est une statistique (fonction mesurable des observations).
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

ANNEXE 66
# je m'interesse au 2e tableauq2<-dat12$pq2sna<-q2[ !is.na(q2)]q2sna<-sample(q2sna,length(q2),replace=T)q2na<-sample(q2sna,length(q2[is.na(q2)]),replace=T)dat12$p[is.na(dat12$p)]<-q2namatre<-rbind(dat11,dat12)result<-matre[,-c(ncol(matre),ncol(matre)-1)]resultat<-result[order(result$z),]resultatOn obtient une imputation sur une variable on refait le même processus pour toutesles variables avec données manquantes en formant le nombre de groupes appropriés (2groupes ne sont pas toujours susant pour l'homogénéité des classes. Par exemple pourla cv, nous avons regroupés le tableau en 4 groupes homogènes ).#
#fonction qui impute les valeurs manquantes sur les données transforméesfonct<-function(var)library("car")p1 = var[!is.na(var)]box.cox.powers(p1)p11 = pλ
1 − 1/λmp1 = mean(p11) # moyenne de la transfoecarp1 = sd(p11) #variance de la transformationnap1 = var[is.na(var)]echantp1 = rnorm(length(nap1), mp1, ecarp1) # echantillon de taille # des d m
pour imputationechanp1 = round(exp(log((λ ∗ echantp1) + 1)/λ , digits = 0)var[is.na(var)] = echanp1
On obtient les variances de nos estimateurs par bootstrap.#
bootstrap_reel=function(X,B=1000,alpha=0.05,fun)n=length(X) #Taille de XN=n*BY<-sample(X,N,replace=TRUE) #Echantillon bootstrapX_mat=matrix(Y,nrow=B,ncol=n,byrow=TRUE) #Decoupage de Y en #B échan-
tillon de taille nfun_X_mat=apply(X_mat,1,fun) #Stat appliquée à chaque échantillonmoy=mean(fun_X_mat)est_var=var(fun_X_mat) #Estimation de la variance de fun(X)
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

ANNEXE 67
inf=moy-qnorm(1-alpha/2)*sqrt(est_var)sup=moy+qnorm(1-alpha/2)*sqrt(est_var)inf=round(inf, digits=2)sup=round(sup, digits=2)reponse<-list(moy,est_var)return(reponse)#-#bootstrap_vect=function(X,B=1000, alpha=0.05 ; fun)#boostrap_vect est une fonction qui prend en entrée un échantillon X de vecteurs,#le nombre de rééchantillonnages et une fonction fun à valeur dans IRd,# qui s'applique à un échantillon X. n=nrow(X) #Nombre de vecteurs dans la
matrice XN=n*BY<-X[sample(c(1 :n),N,replace=TRUE),] #Echantillon boostrapX_mat=list()fun_X_mat=matrix(0,nrow=B,ncol=ncol(X))for(k in 1 :B)X_mat[[k]]=Y[((k-1)*n+1) :(k*n),] #Decoupe Y en B block de #matricesfun_X_mat=t(sapply(X_mat,fun)) #Stat appliquée à chaque échantillon qui# est un block de de matricesmoy=colMeans(fun_X_mat)est_var=var(fun_X_mat)reponse<-list(moy,est_var)return(reponse)##comparaison des diérentes méthodes utilisées##-parsimulation
sigma=diag(1 :4)table=mvrnorm(n=100,m=rep(0,4),sigma)mat2=tablemaa<-function(mat2,pm)
mat<- apply(mat2,2,function(u)u[sample(1 :100,pm)]=NAreturn(u) )data=data.frame(a=mat[,1],b=mat[,2],c=mat[,3],d=mat[,4])data=transform(data) # fonction qui impute les valeurs manquantes par transformationn=nrow(data)
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

ANNEXE 68
p=ncol(data)v=colMeans(table)
MSE=sum(sapply(1 :p,function(j)
sum(((table[,j]-data[,j]) 2)/(sum((table[,j]-v[j]) 2)))))MSE=MSE/(p*n*pm)
return(MSE)
sapply(1 :1000,function(i) maa(mat2,pm))On refait le même procedé pour les autres méthodes et on obtient les diérents
$MSE$##-sur les données
table=eaceligne.na(data) # fonction qui supprime les NA dans mon tableaumat2=tablemaa1<-function(mat2,pm)
matt<- apply(mat2[,-c(1 :3)],2,function(u)u[sample(1 :100,pm)]=NAreturn(u) )data=estim(data) # fonction qui impute les valeurs manquantestable=table[,-c(1 :3)]n=nrow(data)p=ncol(data)v=colMeans(table)
MSE=sum(sapply(1 :p,function(j)
sum(((table[,j]-data[,j]) 2)/(sum((table[,j]-v[j]) 2)))))MSE=MSE/(p*n*pm)
return(MSE)
v<-sapply(1 :100,function(i) maa1(mat2,pm))
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Bibliographie
[1] Cours de statistique mathématiques du Pr. Hili Master de Statistique, ENSP de-cembre et février 2005-2006
[2] Philippe Tassi, "Fondements statistiques " Collection Economica, vol2, pp 319-322.
[3] Efron B, Tibshirani R. An introduction to the bootstrap. London, U.K : Chapmanand Hall, 1999. pp 37-41.
[4] Efron B. Better bootstrap condence intervals. Journal of the American StatisticalAssociation 1987, vol2, pp 171-200.
[5] Donzé L., Imputation multiple et modélisation : quelques expériences tirées del'enquête 1999 KOF/ETHZ sur l'innovation. Ecole polytechnique fédérale de Zurich2001. http ://www.kof.ethz.ch/pdf
[6] Little R. J. "A Test of Missing Completely at Random for Multivariate Data WithMissing Values". Journal of the American Statistical Association, Vol. 83, No. 404,Theory and Methods. December 1988. pp 1198-1202.
[7] Rubin D. B. "Multiple Imputation for Nonresponse in Surveys". John Wiley etSons, 1987. pp 79-84
[8] Rubin, D.B. "Inference and Missing Data". Biometrika 63, 1976. pp 581-592.
[9] Multiple imputation for missing dat : Concepts and new developpment Yang C,Yuan, SAS institute Inc, Rockville, MD. 2001.
[10] The R development Core Team : R : A language and environment for statisticalcomputing, Reference Index, Version 3.1.0, 2005
[11] Cours de Jean- François Dupuy Survival analysis : Techniques for censored Data ,Master de statistique Yaoundé mars 2006
[12] Laurent C, Meilo H, Guiard-Schmid JB, Mpoure Y, M'Bangué M, et al Antiretro-viral therapy in public and private routine health care clinics in Cameroon : lessonsfrom the Douala antiretroviral (DARVIR) initiative. Clin infect Dis 2005 ; 108-111
[13] Laurent C, Kouanfack C, Koulla-Shiro S, Nkoué N, Bourgeois A, Calmy A, Lac-tuock B, Nzeusseu V, Mougnutou R, Peytavin G, Liegeois F, Nerrienet E, TardyM, Peeters M, Andrieux-Meyer I, Zekeng L, Kazatchkine M, Mpoudi-Ngole E etDelaporte E. Eectiveness and safety of a generic xed-dose combination of nevira-pine, stavudine, and lamivudine in HIV-1-infected adults in Cameroon : open-labelmulticentre trial. Lancet 2004 ; 364 :29-34.
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Table des matières
Dédicaces 1
Remerciements 2
Résumé 3
Abstract 4
Résumé exécutif 5
0.1 Problème . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50.2 Méthodologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50.3 Résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60.4 Conclusions et Recommandations . . . . . . . . . . . . . . . . . . . . . . 6
Introduction 2
1 Fondements statistiques pour la gestion des données manquantes 5
1.1 Exemples de tests statistiques . . . . . . . . . . . . . . . . . . . . . 51.1.1 Test de Wald et du rapport de vraisemblance . . . . . . . . 51.1.2 Test de Shapiro-Wilk . . . . . . . . . . . . . . . . . . . . . . . 7
1.2 Le bootstrap . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2.1 Le principe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.2.2 Estimation de la variance de la moyenne empirique . . . . 8
2 Méthodes statistiques pour la gestion des données manquantes 10
2.1 Quelques notions théoriques . . . . . . . . . . . . . . . . . . . . . . 102.1.1 Types de données manquantes . . . . . . . . . . . . . . . . . 102.1.2 Types de modèles . . . . . . . . . . . . . . . . . . . . . . . . . 112.1.3 Les techniques d'imputation . . . . . . . . . . . . . . . . . . . 112.1.4 Procédure d'imputation multiple "valide" . . . . . . . . . . 122.1.5 La procédure d'imputation ABB "approximate bayesian
bootstrap". . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.1.6 Revue des inférences en présence d'imputation multiple. . 12
2.2 Description de quelques méthodes . . . . . . . . . . . . . . . . . . . 15
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

TABLE DES MATIÈRES i
2.2.1 Méthode de régression multiple . . . . . . . . . . . . . . . . 152.2.2 Méthode de propensity score . . . . . . . . . . . . . . . . . . 152.2.3 Méthode MCMC . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3 Etude descriptive du projet DARVIR 22
3.1 Statistique descriptive . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4 Applications des techniques d'imputation multiple pour gérer la non
réponse partielle 29
4.1 Application de la méthode de propensity score . . . . . . . . . . . 304.1.1 Méthode de sélection du modèle optimal . . . . . . . . . . 304.1.2 Résultats obtenus après imputation . . . . . . . . . . . . . 30
4.2 Application de la méthode d'approximation par une loi normale 334.3 Application de la méthode k − nn . . . . . . . . . . . . . . . . . . . 414.4 Application de la méthode MCMC . . . . . . . . . . . . . . . . . . . 434.5 Imputation par la moyenne . . . . . . . . . . . . . . . . . . . . . . . 464.6 Comparaison des méthodes d'imputation sur les variables quan-
titatives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5 Analyse de survie du projet DARVIR 55
5.1 Outils probabilistes pour l'analyse de survi . . . . . . . . . . . . . . 555.1.1 Estimation non paramétrique . . . . . . . . . . . . . . . . . . 565.1.2 Quelques exemples de modèles . . . . . . . . . . . . . . . . . 57
5.2 Application des modèles de survie au projet DARVIR . . . . . . 59
Conclusion 62
6 ANNEXE 63
6.1 Densités des lois de probabilités utilisées . . . . . . . . . . . . . . 636.2 Estimation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 646.3 Codes R des fonctions utilisées . . . . . . . . . . . . . . . . . . . . 65
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Table des gures
3.1 Proportion des patients ayant une cv< 400 . . . . . . . . . . . . . . . . . 273.2 Proportion des patients ayant une cv<50 . . . . . . . . . . . . . . . . . . 273.3 Evolution des cd4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.4 Evolution des poids . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.1 Transformation normale données inclusion . . . . . . . . . . . . . . . . . 354.2 Transformation cv-cd4inc . . . . . . . . . . . . . . . . . . . . . . . . . . . 364.3 Transformation normale des poids suivi . . . . . . . . . . . . . . . . . . . 374.4 Transformation normale des cd4 suivi . . . . . . . . . . . . . . . . . . . . 394.5 Transformation normale des cv suivi . . . . . . . . . . . . . . . . . . . . 404.6 Transformation des données n . . . . . . . . . . . . . . . . . . . . . . . 41
5.1 Courbe de survie de Kaplan-Meier . . . . . . . . . . . . . . . . . . . . . . 605.2 Courbe de survie en fonction du stade. . . . . . . . . . . . . . . . . . . . 61
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

Liste des tableaux
3.1 Données d'inclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.2 Données d'inclusion suite . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.3 Données de suivi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.4 Données de n . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.1 Imputation sur les données d'inclusion quantitatives par ps . . . . . . . 314.2 Imputation sur la variable poids suivi par ps . . . . . . . . . . . . . . . . 324.3 Imputation sur la variable cd4 suivi par ps . . . . . . . . . . . . . . . . . 324.4 Imputation sur la variable cv suivi par ps . . . . . . . . . . . . . . . . . 324.5 Imputation sur les données n quantitatifs par ps . . . . . . . . . . . . . 334.6 Choix de λ inclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.7 Choix de λ suivi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.8 Choix de λ n . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.9 Imputation sur les données inclusion par transformation . . . . . . . . . 374.10 Imputation sur poids suivi par transformation . . . . . . . . . . . . . . . 384.11 Imputation sur cd4 suivi par transformation . . . . . . . . . . . . . . . . 394.12 Imputation sur les données d'inclusion par k-nn . . . . . . . . . . . . . . 424.13 Imputation sur les données n par knn . . . . . . . . . . . . . . . . . . . 434.14 Imputation sur les données inclusion par MCMC . . . . . . . . . . . . . 444.15 Imputation sur les poids suivis par MCMC . . . . . . . . . . . . . . . . 444.16 Imputation sur les cd4 suivis par MCMC . . . . . . . . . . . . . . . . . 444.17 Imputation sur les cv suivis par MCMC . . . . . . . . . . . . . . . . . . 454.18 Imputation sur les données n par MCMC . . . . . . . . . . . . . . . . . 454.19 Imputation sur les données inclusion par la moyenne . . . . . . . . . . . 464.20 Imputation sur les poids suivis par la moyenne . . . . . . . . . . . . . . 464.21 Imputation sur les cd4 suivis par la moyenne . . . . . . . . . . . . . . . 464.22 Imputation sur les cv suivis par la moyenne . . . . . . . . . . . . . . . . 464.23 Imputation sur les données n par la moyenne . . . . . . . . . . . . . . . 474.24 Tableau récapitulatif poidsinc . . . . . . . . . . . . . . . . . . . . . . . . 504.25 Tableau récapitulatif âge . . . . . . . . . . . . . . . . . . . . . . . . . . . 504.26 Tableau récapitulatif cd4inc . . . . . . . . . . . . . . . . . . . . . . . . . 504.27 Tableau récapitulatif cvinc . . . . . . . . . . . . . . . . . . . . . . . . . . 514.28 Tableau récapitulatif poids1 . . . . . . . . . . . . . . . . . . . . . . . . . 51
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006

LISTE DES TABLEAUX i
4.29 Tableau récapitulatif poids2 . . . . . . . . . . . . . . . . . . . . . . . . . 514.30 Tableau récapitulatif poids3 . . . . . . . . . . . . . . . . . . . . . . . . . 514.31 Tableau récapitulatif poids4 . . . . . . . . . . . . . . . . . . . . . . . . . 524.32 Tableau récapitulatif cd41 . . . . . . . . . . . . . . . . . . . . . . . . . . 524.33 Tableau récapitulatif cd42 . . . . . . . . . . . . . . . . . . . . . . . . . . 524.34 Tableau récapitulatif cd43 . . . . . . . . . . . . . . . . . . . . . . . . . . 524.35 Tableau récapitulatif cd44 . . . . . . . . . . . . . . . . . . . . . . . . . . 534.36 Tableau récapitulatif cv1 . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.37 Tableau récapitulatif cv2 . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.38 Tableau récapitulatif cv3 . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.39 Tableau récapitulatif cv4 . . . . . . . . . . . . . . . . . . . . . . . . . . . 544.40 Tableau récapitulatif poidsn . . . . . . . . . . . . . . . . . . . . . . . . 544.41 Tableau récapitulatif cd4n . . . . . . . . . . . . . . . . . . . . . . . . . 544.42 Tableau récapitulatif cvn . . . . . . . . . . . . . . . . . . . . . . . . . . 54
Mémoire de Master de statistiques Kouamo Olaf c©ENSP 2005-2006





























